Чем алгоритм машинного обучения отличается от традиционного алгоритма?
Являясь подмножеством искусственного интеллекта, алгоритм Машинное обучение идентифицирует шаблоны в данных, а затем аналогичным образом прогнозирует новые данные. Это помогает компьютерам понять, не будучи явно запрограммированными предыдущими правилами. Однако он отличается от традиционного алгоритма тем, что некоторые входные данные и логика были взяты в виде кода, и окончательные результаты будут выводиться.

Разница между алгоритмом ML и традиционным алгоритмом:
Алгоритм машинного обучения:
В алгоритме машинного обучения как входные, так и выходные данные компилируются в алгоритм, а окончательным продолжением будет программа.

Традиционный алгоритм:
В отличие от алгоритма ML, это в основном ручной процесс, когда программист создает программу с формулирующими кодами, после чего необходимо включить некоторые входные данные, что в значительной степени создает желаемый результат.

Чем они отличаются друг от друга?
Надежное отличие состоит в том, что в традиционном алгоритме программист должен вручную сформулировать код, в то время как в ML окончательное продолжение, полученное из данных, представляет собой программу.
Точнее, если вы рассматриваете демографические данные клиентов и транзакции как входные данные, а выполненные выходные данные являются оттоком или нет, таким образом, алгоритм формулирует модель оттока.

Как правило, у вас может быть множество входных и выходных данных, которые можно использовать в алгоритме для создания моделей. Например, демографические данные и кредитные операции подаются в качестве входных данных, а количество просроченных кредитов будет наблюдаемым выходом, и, наконец, будет создана модель дефолтных кредитов (программа).

Традиционный алгоритм в иллюстративном виде:
Однако, если взять простой пример, 358+287. Большинство людей огорчены ответом слева направо 13.05.15.

Это связано с тем, что Традиционный Алгоритм обрабатывает числа справа налево, сначала взгляните на 8+7.

При сложении мы никогда не записываем 15, а 10 точек нужно развернуть сразу, а 5 пишется на странице в строке ответа вместе с 1, поджатой к средней колонке.

Теперь при добавлении (5+8) было дано 13 точек.

И это приводит к еще одному взрыву.
При написании 4 в строке ответа, а еще 1 остается в следующем столбце. Это даст вам более точное представление о картине точек и прямоугольников.
А теперь задача закончена суммированием позиций точек и сотен.

Теперь вы получите краткое объяснение традиционного алгоритма и того, как выполняются вычисления с использованием точек.
Основы алгоритма ML:
Алгоритмы машинного обучения — это математические и логические программы, которые всякий раз, когда им предоставляется больше данных, автоматически настраиваются, чтобы работать лучше. В основном это набор методов, который объединяет как входные, так и выходные данные, что приводит к программе. ML фокусируется на процветании компьютерных программ, которые могут получать доступ к данным и использовать их, чтобы реализовать себя. Эта способность прогнозирования помогает машинному обучению более эффективно и точно справляться с бизнес-ситуациями. Если программирование — это автоматизация, то машинное обучение ускорит процесс автоматизации.
Для полного понимания алгоритма машинного обучения необходимы три ключевых компонента.
1) Представление: как проиллюстрировать знания. Например, набор правил, графические модели, машины опорных векторов и деревья решений.
2) Оценка: способ оценки программ-кандидатов. Например, точность, квадрат ошибки, правдоподобие, вероятность, маржа и стоимость.
3) Оптимизация: процесс создания программ-кандидатов, известный как процесс поиска. Например, выпуклая оптимизация, комбинационная оптимизация и оптимизация с ограничениями.
Таким образом, алгоритм ML = модель + алгоритм обучения.

МЛ Против. Традиционный алгоритм:
● Алгоритм машинного обучения не подчиняется правилам, установленным людьми. Вместо этого данные обрабатывались только в необработанном виде, например электронные письма, социальные сети, текст, видео, голос и изображения.
● Алгоритм машинного обучения не запрограммирован на выполнение задачи, а используется для обучения тому, как выполнить задачу.
● Алгоритм машинного обучения больше ориентирован на предсказание, но традиционный алгоритм больше ориентирован на интерпретацию.
● В традиционных алгоритмах больше внимания уделяется p-значению и структурированной, но всеобъемлющей модели.
● Основные отличия заключаются в том, что традиционные алгоритмы используют более математический подход, тогда как алгоритмы машинного обучения больше ориентированы на данные.
● Алгоритмы машинного обучения непрерывны, поэтому они не подходят, когда возникает понимание взаимосвязи. Они могут хорошо работать, когда нужен только прогноз.
● Традиционный алгоритм основан на модели, основанной на обучающих данных, и оценка модели по входящим данным неэффективна, поскольку среда постоянно меняется.
● В то время как алгоритм машинного обучения имеет дорогостоящие подходы в веб-средах. и результаты слишком стабильны, чтобы их можно было поддерживать в динамически меняющихся средах обслуживания.
Простая структура:
Менеджер по продукту может использовать структуру, чтобы понять продолжение бизнеса, где у вас есть входные и выходные данные:
1) Укажите бизнес-вопрос, который вы хотите задать.
2) Определите входные данные.
3) Определите выполненный вывод.
Теперь, если вы видите демографические данные и счета в качестве входных данных, а оплату с опозданием или нет в качестве выходных данных, ваше машинное обучение, таким образом, создает всю модель.

Чтобы создать прогностическую модель, компании необходимо определить выборки, когда отток является истинным, а когда отток — ложным. Таким образом, алгоритм прогнозирования передает данные для создания программы. Известно, что это самый простой способ наблюдения за прогнозируемыми результатами.
Традиционный алгоритм требует некоторых входных данных и кода, что дает вам результат. То есть данные и программы запускаются в компьютер для создания выходных данных. Традиционный алгоритм следует шагам, описанным в алгоритме, который создает выходные данные. Жесткий код сам. Правила и генерация вывода — это два метода, на основе которых алгоритм вводит его.

Алгоритму машинного обучения нужны входные и выходные данные, поэтому он предоставляет вам логику, которую можно преобразовать в новые входные данные для получения выходных данных. Алгоритм ML — это в основном процесс обучения, в котором вы учитесь посредством ввода. Не обязательно, что все алгоритмы машинного обучения основаны на нейронных сетях, возврате прохода или алгоритмах на основе дерева используются для решения многих бизнес-кейсов.
Машинное обучение чаще используется в садоводстве или сельском хозяйстве. Где семена — это алгоритмы, данные — питательные вещества, вы — садовник, а растения — программы.

За последние два десятилетия наблюдался эффективный рост приложений алгоритмического моделирования за пределами статистического сообщества. Машинное обучение более надежно среди специалистов по информатике, поскольку оно производит больше информации. Вместо традиционных методов вступают в противоречие точность, простота и прогнозирование.
Машинное обучение против традиционного программирования — руководство для новичков

Машинное обучение — это известный термин в наши дни. Но новичков может сбить с толку то, что такое машинное обучение на самом деле и чем машинное обучение отличается от традиционного программирования. Возможно, что теоретическое определение не могло дать практического понимания.
Итак, давайте рассмотрим практический пример, чтобы узнать разницу между ними. Здесь мы взяли две разные задачи.
Проблема 1. Напишите программу для сложения двух чисел.
Мы можем легко решить эту проблему, реализовав простую функцию, которая использует формулу сложения, или мы можем сказать, что нам известны правила решения этой проблемы. Пример кода написан ниже.
Проблема 2. У нас есть данные, состоящие из набора рукописных цифр, и мы должны написать программу для распознавания цифры, принимая ввод как изображение цифры.
Попробуем решить эту проблему с помощью подхода традиционного программирования. Можем ли мы определить правила для разных чисел и, основываясь на этих правилах, распознать цифру. Но одно и то же число может быть написано по-разному и по-разному (у каждого человека свой почерк), тогда правил будет недостаточно для решения этой проблемы.
Составьте список различий между двумя вышеуказанными проблемами.
В задаче 1 у нас есть формула для сложения двух чисел.
В задаче 2 только человек может распознавать цифры зрением, но мы не можем придумать шаги, которые можно было бы закодировать в компьютере для решения проблемы.
Так что нам нужно сделать что-то еще. Это нечто другое обнаруживается как машинное обучение.
Человек может распознать цифру, потому что люди знают цифры, и они выучили цифры. Человеческий мозг обучен распознавать цифры разного стиля и ориентации. Чтобы заставить компьютер делать это, мы должны тренировать компьютер таким же образом. Такой подход называется машинным обучением.
Итак, наконец, мы можем нарисовать схематическое представление традиционного программирования и машинного обучения на основе фактов, рассмотренных выше.

В традиционном программировании у нас есть данные и правила, и на основе этих правил мы создаем программу для выполнения конкретной задачи.

Как мы видели, проблемы с машинным обучением требуют обучения системы. Из диаграммы можно понять, что изначально в машинном обучении у нас нет правил, вместо этого у нас есть набор меток или примеров, и на основе этих меток наш тренер по машинному обучению который включает в себя алгоритмы и методы машинного обучения, и в результате мы получаем Правила или шаблон, также называемый моделью, и этот этап называется этапом обучения.
После построения модели следующим этапом является этап вывода или прогнозирования, этот этап аналогичен традиционному подходу к программированию. Теперь у нас есть новые данные, и наша модель производит выходные данные на основе входные данные.
Руководство для начинающих по машинному обучению

Машинное обучение — это тип искусственного интеллекта, который позволяет компьютерным системам обучаться и повышать свою производительность без явного программирования. Он включает в себя обучение компьютерной системы на большом наборе данных, что позволяет ей выявлять закономерности и делать прогнозы или решения на основе этих закономерностей.
Некоторые примеры машинного обучения в действии включают:
· Беспилотный автомобиль, который может научиться ориентироваться на дорогах и избегать препятствий, используя данные датчиков и алгоритмы машинного обучения.
· Система рекомендаций, которая может предсказать, какие фильмы или продукты могут заинтересовать пользователя, основываясь на его прошлом поведении.
· Спам-фильтр, который может научиться идентифицировать и блокировать нежелательные электронные письма на основе характеристик предыдущих спам-сообщений.
Машинное обучение отличается от традиционного программирования тем, что не требует явных инструкций для каждого шага. Вместо этого компьютерная система способна учиться на данных и принимать решения самостоятельно, без явных указаний, что делать. Это позволяет системам машинного обучения быть более гибкими и адаптируемыми, чем традиционные программы, но также требует другого подхода к проектированию и разработке.
2. Тип машинного обучения
Существует четыре основных типа машинного обучения: контролируемое обучение, неконтролируемое обучение, частично контролируемое обучение и обучение с подкреплением.
1. Обучение с учителем включает в себя обучение модели на размеченном наборе данных, где для каждого примера в обучающем наборе предоставляются правильные выходные данные. Цель модели состоит в том, чтобы делать прогнозы на новых, невидимых примерах, взятых из того же распределения. Примеры задач контролируемого обучения включают прогнозирование цены дома на основе его характеристик или определение того, является ли электронное письмо спамом, на основе его содержания.
2. Неконтролируемое обучение включает в себя обучение модели на немаркированном наборе данных с целью обнаружения закономерностей или взаимосвязей в данных. Этот тип обучения полезен для изучения и понимания сложных наборов данных. Примеры неконтролируемых задач обучения включают кластеризацию точек данных в группы или выявление аномальных точек данных.
3. Полууправляемое обучение представляет собой комбинацию контролируемого и неконтролируемого обучения, когда модель обучается на наборе данных, который частично помечен, а частично не помечен. Это может быть полезно, когда маркировка большого набора данных обходится дорого или требует много времени, или когда доступно много немаркированных данных, но только небольшое количество маркированных данных.
4. Обучение с подкреплением включает в себя обучение агента принимать последовательность решений в окружающей среде, чтобы максимизировать вознаграждение. Агент получает обратную связь в виде вознаграждения или наказания за свои действия и использует эту обратную связь для изучения оптимальной политики взаимодействия с окружающей средой. Обучение с подкреплением используется в различных приложениях, включая видеоигры, управление роботами и рекомендательные системы.
3. Общие алгоритмы машинного обучения
· Линейная регрессия — это контролируемый алгоритм обучения, который используется для прогнозирования непрерывного результата. Он предполагает, что между входными и выходными объектами существует линейная зависимость, и пытается найти линию наилучшего соответствия по данным.
· Логистическая регрессия — это контролируемый алгоритм обучения, который используется для задач классификации. Он похож на линейную регрессию, но вместо того, чтобы предсказывать непрерывный результат, он предсказывает вероятность принадлежности примера к определенному классу.
· Деревья решений — это тип контролируемого алгоритма обучения, который используется для задач классификации и регрессии. Они работают, создавая древовидную модель решений, основанную на особенностях данных, с целью делать точные прогнозы.
· Машины опорных векторов (SVM) представляют собой тип алгоритма обучения с учителем, который используется для задач классификации. Они работают, находя гиперплоскость в многомерном пространстве, которая максимально разделяет разные классы.
· Нейронные сети — это тип контролируемого алгоритма обучения, вдохновленный структурой и функцией мозга. Они состоят из слоев взаимосвязанных «нейронов», которые обучаются с использованием больших объемов данных и мощной вычислительной мощности. Нейронные сети очень гибкие и могут использоваться для решения широкого круга задач, но требуют много данных и вычислительных ресурсов.
4. Начало работы с машинным обучением
· Инструменты и библиотеки. Существует множество инструментов и библиотек для машинного обучения, таких как TensorFlow, scikit-learn, PyTorch и другие. Рекомендуется ознакомиться с некоторыми из них, чтобы увидеть, какой из них лучше всего подходит для вас.
· Сбор и подготовка данных. Данные являются важнейшим компонентом машинного обучения. Вам нужно будет собрать и подготовить данные, прежде чем вы сможете обучить модель. Это включает в себя очистку данных для удаления любых отсутствующих или недопустимых значений и, возможно, преобразование или масштабирование данных, чтобы сделать их более подходящими для моделирования.
· Выбор алгоритма. Существует множество различных алгоритмов, которые можно использовать для машинного обучения. Некоторые популярные из них включают деревья решений, случайные леса, машины опорных векторов и нейронные сети. Важно выбрать алгоритм, который подходит для ваших данных и задачи, которую вы пытаетесь решить.
· Обучение модели: после того, как вы выбрали алгоритм и подготовили данные, вы можете обучить модель, используя обучающие данные. Это включает в себя подачу данных в алгоритм и настройку параметров модели, чтобы минимизировать ошибку между прогнозируемыми выходными данными и истинными выходными данными.
· Оценка производительности модели. После обучения модели важно оценить ее производительность на невидимых данных (также известных как набор тестов). Это даст вам представление о том, насколько хорошо модель обобщает новые данные и соответствует ли она тренировочным данным.
5. Реальные приложения машинного обучения
1. Здравоохранение. Машинное обучение используется в здравоохранении для прогнозирования результатов лечения пациентов, выявления потенциальных вспышек инфекционных заболеваний и помощи в диагностике и принятии решений о лечении.
2. Финансы. Машинное обучение используется в финансах для обнаружения мошеннических транзакций, прогнозирования цен на акции и выявления потенциальных инвестиционных возможностей.
3. Электронная коммерция. Машинное обучение используется в электронной коммерции для персонализации рекомендаций по продуктам или услугам, оптимизации ценообразования и управления запасами, а также для улучшения качества обслуживания клиентов.
4. Этические соображения. Машинное обучение может принести значительную пользу обществу, но оно также вызывает вопросы этического характера. Например, есть опасения по поводу предвзятости алгоритмов машинного обучения, а также возможности автоматизации для замены рабочих мест. Важно учитывать этические последствия использования машинного обучения и предпринимать шаги для решения любых потенциальных проблем.
6.Дальнейшие шаги, чтобы узнать больше о машинном обучении
1. Книги. Существует множество книг по машинному обучению, от начального до продвинутого. Некоторые популярные из них включают «Практическое машинное обучение с помощью Scikit-Learn, Keras и TensorFlow» Орельена Жерона, «Глубокое обучение» Яна Гудфеллоу и др. и «Элементы статистического обучения» Тревора Хасти и др.
2. Онлайн-курсы. Существует также множество онлайн-курсов по машинному обучению, в том числе МООК (массовые открытые онлайн-курсы) на таких платформах, как Coursera, edX и Udacity. Эти курсы могут быть хорошим способом узнать о машинном обучении в удобном для вас темпе и получить сертификат по окончании.
3. Учебники. В Интернете доступно множество учебных пособий, которые помогут вам начать работу с машинным обучением. Это может быть хорошим способом узнать о конкретных концепциях или методах и опробовать их на практике.
Чтобы быть в курсе событий в этой области, вы можете следить за блогами, посвященными машинному обучению, и учетными записями в социальных сетях, посещать конференции и встречи, а также присоединяться к онлайн-сообществам или форумам. Также рекомендуется постоянно учиться и практиковать свои навыки, работая над проектами машинного обучения и оставаясь в курсе последних исследований.
Это машинное обучение, часть 1: обучение против программирования
Разработчики программного обеспечения любят делиться историями о войне. Как только некоторые из нас садятся в паб, кто-то спрашивает: «Над каким проектом вы работаете?» Затем мы киваем головами, слушая друг друга забавные, а иногда и ужасные сказки.
В середине 90-х, во время одного из вечеров подшучивания, подруга рассказала мне о невыполнимой миссии, которую она выполняла. Ее менеджерам нужна была программа, которая анализировала бы рентгеновские снимки и выявляла заболевания, такие как пневмония.
Моя подруга предупредила руководство, что задача безнадежна, но они отказались ей верить. Если радиолог мог это сделать, рассуждали они, то почему бы не программу на Visual Basic? Они даже соединили мою подругу с профессиональным радиологом, чтобы она могла изучить эту работу и превратить ее в код. Этот опыт только укрепил ее мнение о том, что радиология требует человеческого суждения и ума.
Мы смеялись над бесполезностью этой задачи. Через несколько месяцев проект закрыли.
Перенесемся в более недавние времена: в конце 2017 года исследовательская группа из Стэнфордского университета опубликовала алгоритм диагностики пневмонии с помощью рентгеновских снимков. Алгоритм был не просто хорош — он был точнее профессиональных радиологов. Это должно было быть невозможно! Как, черт возьми, они могли написать этот код?
Ответ в том, что они этого не сделали. Вместо написания кода они решили проблему с машинным обучением. Посмотрим, что это значит.
Вот пример разницы между машинным обучением (или просто ML) и обычным программированием. Представьте, что вы создаете программу, которая играет в видеоигры. При традиционном программировании эта программа может выглядеть примерно так:

…и так далее. Большая часть кода будет представлять собой большую коллекцию операторов if..else, смешанных с императивными командами, такими как Shot ().
Конечно, современные языки дают нам возможность заменить эти уродливые вложенные if более приятными конструкциями — полиморфизмом, сопоставлением с образцом или вызовами, управляемыми событиями. Однако основная идея программирования остается прежней: вы говорите компьютеру, что искать, и вы говорите ему, что делать. Вы должны перечислить все условия и определить каждое действие.
Этот подход нам хорошо послужил, но у него есть несколько недостатков. Во-первых, вы должны быть исчерпывающими. Вы, вероятно, можете представить себе десятки или сотни конкретных ситуаций, которые вам придется охватить в этой игровой программе. Что произойдет, если враг приближается, но между вами и врагом есть усиление, которое защищает вас от вражеского огня? Человек-игрок быстро заметит ситуацию и воспользуется ею. Ваша программа . ну, это зависит от обстоятельств. Если вы написали код для этого особого случая, ваша программа справится с этим, но мы знаем, как сложно охватить все особые случаи, даже в структурированных областях, таких как бухгалтерский учет. Удачи в перечислении всех возможных особых случаев в сложных областях, таких как видеоигры, вождение грузовика или распознавание изображения!
Даже если бы вы могли перечислить все эти решения, вам в первую очередь нужно было бы знать, как их принимать. Это второе ограничение программирования и остановка в некоторых областях. Например, возьмем задачу компьютерного зрения, подобную нашей первоначальной задаче: выявление пневмонии при сканировании грудной клетки.
Мы не на самом деле знаем, как радиолог распознает пневмонию. Да, у нас есть общее представление об этом, например: «Радиолог ищет непрозрачные участки». Однако мы не знаем, как мозг рентгенолога распознает и оценивает непрозрачную область. В некоторых случаях эксперт сама не может сказать вам, как она пришла к диагнозу, за исключением довольно расплывчатого: «Я знаю по опыту, что пневмония выглядит не так». Поскольку мы не знаем, как эти решения принимаются, мы не можем дать компьютеру указание их принимать. Это проблема, характерная для всех типичных человеческих задач, таких как дегустация пива или понимание предложения.
С другой стороны, машинное обучение переворачивает традиционное программирование с ног на голову. Посмотрим как.
Напомним, что программирование — это передача компьютеру инструкций:

В отличие от этого, машинное обучение дает компьютеру данные и просит его выяснить, что делать.
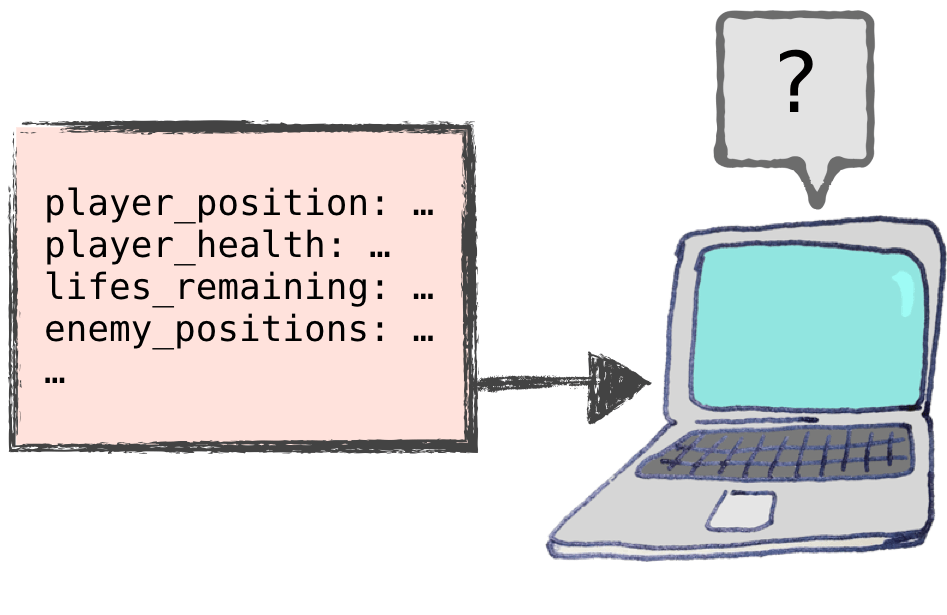
Идея о том, что компьютер «вычисляет» что-либо, звучит как принятие желаемого за действительное, но на самом деле есть несколько разных способов осуществить это. Если вам интересно, все они по-прежнему требуют работающего кода. Однако этот код не является пошаговой процедурой для решения проблемы, как в традиционном программировании. Вместо этого код в машинном обучении сообщает компьютеру, как обрабатывать данные, чтобы компьютер мог решить проблему самостоятельно.
В качестве примера приведу один из способов, с помощью которого компьютер может понять, как играть в видеоигры. Представьте себе алгоритм, который учится играть методом проб и ошибок. Он начинается с подачи случайных команд: «выстрелить», «замедлить», «повернуть» и так далее. Если эти команды в конечном итоге приводят к успеху, например, к более высокому баллу, алгоритм запоминает этот опыт. Если они приводят к отказу, например к смерти, алгоритм также принимает это к сведению. В то же время он также принимает во внимание состояние игры: где враги, препятствия и бонусы? Сколько у нас здоровья? И так далее.
С этого момента всякий раз, когда он сталкивается с подобным игровым состоянием, алгоритм с большей вероятностью попытается выполнить успешные действия, чем неудачные. После многих циклов проб и ошибок такая программа стала бы компетентным игроком. В 2013 году система, использующая этот подход, достигла сверхчеловеческих навыков в нескольких старых играх Atari.
Этот стиль машинного обучения называется обучением с подкреплением. Обучение с подкреплением работает примерно так же, как дрессировка собак: «хорошее» поведение вознаграждается, так что собака делает его больше.
(Я также пробовал тот же подход со своей кошкой. Пока что у меня ничего не вышло.)
Обучение с подкреплением — лишь один из способов позволить компьютеру решить проблему. В следующем посте этой мини-серии мы сосредоточимся на другом стиле машинного обучения, который, возможно, является самым популярным: контролируемое обучение.


Этот пост был адаптирован из первой главы Программирование машинного обучения , вводного курса для программистов, от основ до глубокого обучения. Перейдите сюда, чтобы получить электронную книгу, сюда, чтобы получить бумажную книгу, или зайдите на форум, если у вас есть вопросы и комментарии!