Импортозамещенное шифрование глазами программиста. Хешируем по ГОСТ 34.11—2012

Стандарт ГОСТ 34.11—2012 пришел на смену ГОСТ 34.11—94, который к настоящему времени уже считается потенциально уязвимым (хотя до 2018 года ГОСТ 1994 года выпуска все же применять не возбраняется). Отечественные стандарты хеширования обязательны к применению в продуктах, которые будут крутиться в ответственных и критических сферах и для которых обязательно прохождение сертификации в уполномоченных органах (ФСТЭК, ФСБ и подобных). ГОСТ 34.11—2012 был разработан Центром защиты информации и специальной связи ФСБ России с участием открытого акционерного общества «Информационные технологии и коммуникационные системы» (ИнфоТеКС). В основу стандарта 2012 года была положена функция хеширования под названием «Стрибог» (если что, такое имя носил бог ветра в древнеславянской мифологии).

Славянский бог ветра Стрибог (сайт myfhology.info)
Другие статьи в выпуске: 
Xakep #210. Краткий экскурс в Ethereum
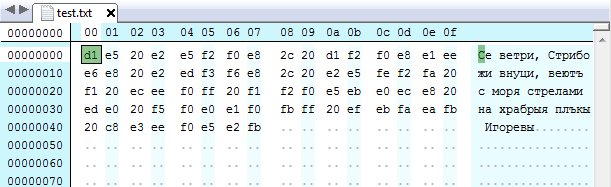
Тестовый пример из ГОСТ 34.11—2012
Хеш-функция «Стрибог» может иметь две реализации с результирующим значением длиной 256 или 512 бит. На вход функции подается сообщение, для которого необходимо вычислить хеш-сумму. Если длина сообщения больше 512 бит (или 64 байт), то оно делится на блоки по 512 бит, а оставшийся кусочек дополняется нулями с одной единичкой до 512 бит (или до 64 байт). Если длина сообщения меньше 512 бит, то оно сразу дополняется нулями с единичкой до полных 512 бит.
Немного теории
Основу хеш-функции «Стрибог» составляет функция сжатия (g-функция), построенная на блочном шифре, построенном с помощью конструкции Миягучи — Пренеля, признанной одной из наиболее стойких.

Блочный шифр в режиме Миягучи — Пренеля. Здесь m — очередной блок исходного сообщения, h — значение предыдущей функции сжатия
В целом хеширование производится в три этапа. Первый этап — инициализация всех нужных параметров, второй этап представляет собой так называемую итерационную конструкцию Меркла — Дамгорда с процедурой МД-усиления, третий этап — завершающее преобразование: функция сжатия применяется к сумме всех блоков сообщения и дополнительно хешируется длина сообщения и его контрольная сумма.
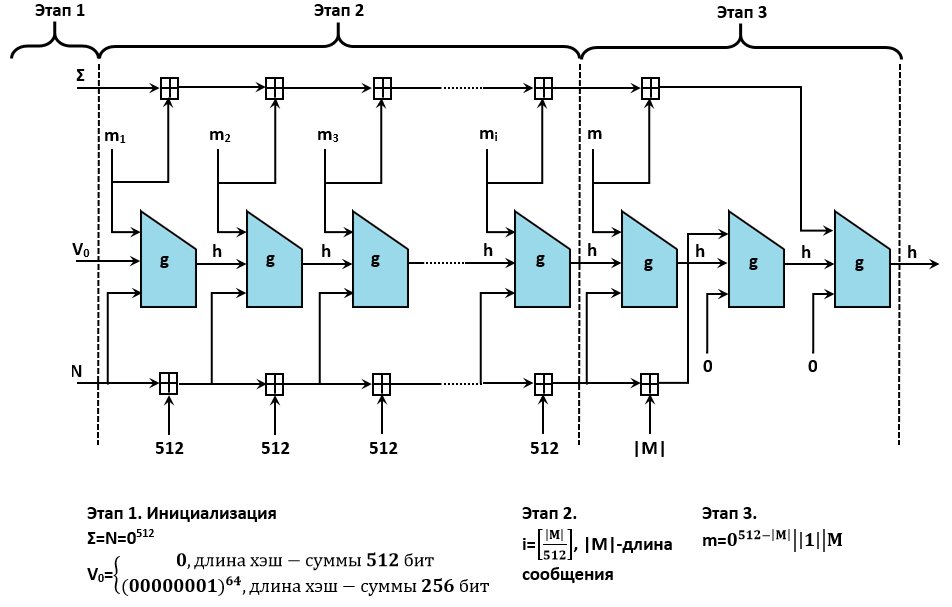
Общая схема вычисления хеш-суммы по ГОСТ 34.11—2012
WARNING
Итак, после краткого и небольшого погружения в теорию начинаем кодить.
Базовые функции стандарта
Поскольку при вычислении хеша мы имеем дело с 64-байтовыми блоками (в стандарте они представлены 512-разрядными двоичными векторами), для начала определим этот самый двоичный вектор:
Сложение двух двоичных векторов по модулю 2
Здесь все предельно просто. Каждый байт первого вектора ксорится с соответствующим байтом второго вектора, и результат пишется в третий (выходной) вектор:
Побитовое исключающее ИЛИ над 512-битными блоками
В тексте ГОСТа название данной операции звучит как сложение в кольце вычетов по модулю 2 в степени n. Такая фраза кого угодно может вогнать в уныние, но на самом деле ничего сложного и страшного в ней нет. Два исходных 64-байтовых вектора представляются как два больших числа, далее они складываются, и переполнение, если оно появляется, отбрасывается:
Нелинейное биективное преобразование (преобразование S)
При биективном отображении каждому элементу одного множества соответствует ровно один элемент другого множества (более подробно про биекцию можешь почитать в Википедии). То есть это просто банальная подстановка байтов в исходном векторе по определенному правилу. В данном случае правило задается массивом из 256 значений:
Здесь для экономии места показаны не все значения, определенные в стандарте, а только три первых и два последних. Когда будешь писать код, не забудь про остальные.
Итак, если в исходном векторе у нас встречается какой-либо байт со значением, например, 23 (в десятичном выражении), то вместо него мы пишем байт из массива Pi, имеющий порядковый номер 23, и так далее. В общем, код функции преобразования S получается такой:
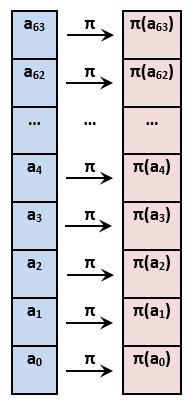 Преобразование S
Преобразование S
Перестановка байтов (преобразование P)
Преобразование P — простая перестановка байтов в исходном массиве в соответствии с правилом, определяемым массивом Tau размером в 64 байта:
Здесь, так же как и в предыдущем случае, для экономии места показаны не все значения массива Tau.
Перестановка выполняется следующим образом: сначала идет нулевой элемент исходного вектора, далее — восьмой, потом — шестнадцатый и так далее до последнего элемента. Код функции напишем так:
Линейное преобразование (преобразование L)
Это преобразование носит название «умножение справа на матрицу A над полем Галуа GF(2)» и по сравнению с первыми двумя будет немного посложнее (по крайней мере, вкурить всю суть от и до с первого прочтения стандарта удается далеко не всем). Итак, есть матрица линейного преобразования A, состоящая из 64 восьмибайтовых чисел (здесь приведена не в полном объеме):
Исходный вектор делится на порции размером по 8 байт, каждая из этих порций интерпретируется в виде 64-разрядного двоичного представления. Далее берется очередная порция, каждому биту из этой порции ставится в соответствие строка из матрицы A. Если очередной бит равен нулю, то соответствующая ему строка из матрицы A вычеркивается; если очередной бит равен единице, то соответствующая ему строка из матрицы A остается. После всего этого оставшиеся строки из матрицы линейного преобразования ксорятся, и получившееся число записывается в виде очередной восьмибайтовой порции в результирующий вектор. Код выглядит следующим образом:
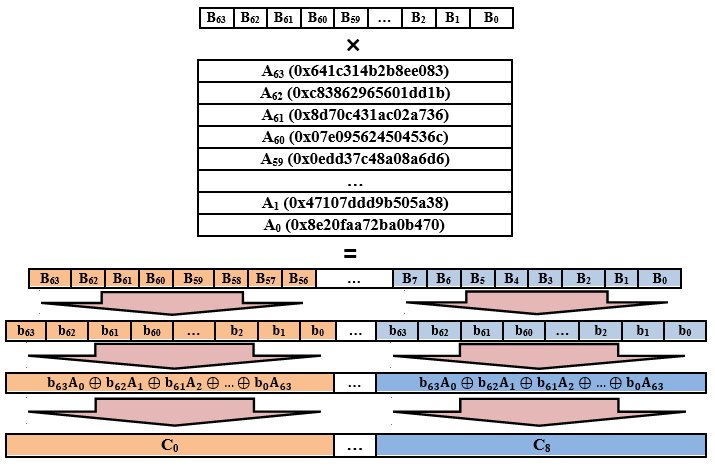
Схема линейного преобразования L
Пишем все остальное
Имея в наличии все необходимые базовые преобразования, определенные стандартом, можно приступить непосредственно к реализации алгоритма «Стрибог» в целом.
Для начала определим структуру, в которую будем складывать все исходные, промежуточные и конечные результаты вычислений:
Далее напишем преобразование E, которое является частью функции сжатия. В этом преобразовании задействовано двенадцать так называемых итерационных констант (C1 — C12), на основе которых вычисляются раундовые ключи K. Для вычисления этих раундовых ключей определим функцию GOSTHashGetKey , которая представляет собой сочетание преобразований S, P и L, а также побайтного сложения по модулю 2:
Для этой функции необходимо описать итерационные константы, которых, как мы уже говорили, двенадцать штук (для краткости здесь эти константы показаны не в полном объеме):
Если ты попытаешься сравнить приведенные выше константы с текстом стандарта, то увидишь, что эти самые константы записаны «задом наперед». Дело в том, что все байтовые массивы (в том числе и строки тестовых примеров) в тексте стандарта описаны таким образом, что нулевой их элемент находится в конце массива, а не в начале, как мы привыкли, поэтому строки перед использованием надо «переворачивать».
Далее пишем саму функцию преобразования E:
И, используя эти функции, пишем самую главную функцию алгоритма «Стрибог» — функцию сжатия g:
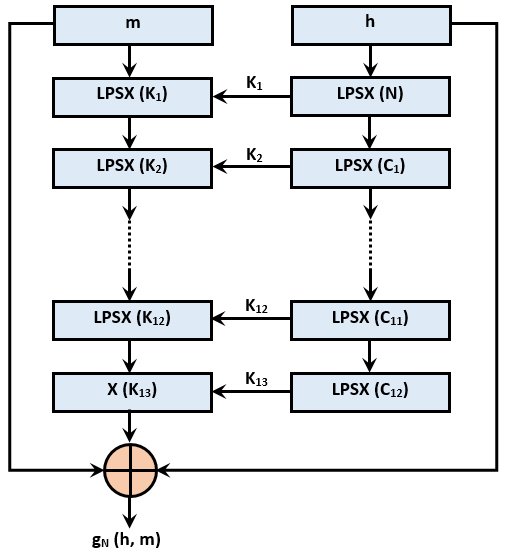
Схема функции сжатия g
В самом начале мы говорили, что хеширование выполняется блоками по 64 байта, а последний блок, если он меньше 64 байт, дополняется нулями с одной единичкой. Для этой операции вполне подойдет функция GOSTHashPadding :
Теперь открываем руководящий документ на шестой странице и внимательно разбираемся с этапами вычисления столь нужной нам хеш-функции.
Первый этап (инициализация)
Как ясно из названия, этот этап необходим для первоначального задания значений всех переменных:
Второй этап
На этом этапе мы хешируем отдельные блоки размером в 512 бит (или 64 байта) до тех пор, пока они не кончатся. Этап состоит из функции сжатия и двух операций исключающего ИЛИ (с их помощью формируется контрольная сумма):
Третий этап
На третьем этапе мы хешируем остаток, который не попал в очередной 64-байтный блок из-за того, что его размер меньше. Далее формируем контрольную сумму всего сообщения с учетом его длины и вычисляем окончательный результат. Выглядит это все так:
Разобравшись со всеми этапами, сложим все в единое целое. Весь процесс будет описан в трех функциях:
- GOSTHashInit (она у нас уже есть);
- GOSTHashUpdate (туда мы поместим все итерации второго этапа);
- GOSTHashFinal (там мы завершим весь процесс третьим этапом).
Функция GOSTHashUpdate
Объявим эту функцию таким образом:
Как уже неоднократно говорилось, хеширование производится блоками по 64 байта, поэтому в начале функции напишем следующее:
Поскольку при чтении файла мы его будем читать по кусочкам, длина которых задается при использовании функции fread, то при слишком длинном файле мы можем потерять остаток файла и, соответственно, неправильно посчитать хеш-сумму. Чтобы этого избежать, необходимо в нашу функцию GOSTHashUpdate добавить следующий код:
Функция GOSTHashFinal
Здесь все просто:
Считаем хеш-сумму файла
Вот мы и подошли к завершающему этапу написания кода, позволяющего посчитать хеш-сумму по алгоритму «Стрибог». Осталось считать нужный файл в заранее отведенный участок памяти и поочередно вызвать функции GOSTHashUpdate и GOSTHashFinal :
После завершения в зависимости от нужной нам длины хеш-суммы берем значение CTX->hash полностью (длина хеша 512 бит) либо берем от CTX->hash последние 32 байта.
Не забудь про исходники
Весь код: классическую реализацию алгоритма (в полном соответствии с ГОСТом), усовершенствованную реализацию (с предварительным расчетом значений преобразований S и L), а также код предварительного расчета значений преобразований S и L — ты найдешь в приложении к этому номеру.
Заключение
Наверняка у тебя промелькнула мысль о ресурсоемкости данного алгоритма и возможных способах увеличения быстродействия. Очевидные приемы типа применения выравнивания при описании всех используемых структур, переменных и участков памяти, скорее всего, ощутимого эффекта не дадут, но в этом алгоритме есть возможность заранее посчитать некоторые значения и использовать при написании кода в дальнейшем именно их.
Если внимательно почитать стандарт (особенно страницы 3 и 4), то выяснится, что преобразования S и L можно выполнить заранее и сформировать восемь массивов по 256 восьмибайтовых чисел, в которых будут содержаться все возможные значения этих двух преобразований. Помимо этого, при вычислении хеш-суммы с использованием заранее рассчитанных значений можно сразу сделать и нужные перестановки в соответствии с преобразованием P. В общем, весь нужный код (вычисление хеша классическим алгоритмом, предварительный расчет значений преобразований S и L и вычисление хеша с помощью заранее просчитанных значений) найдешь в приложении к этой статье. Бери, разбирайся, пользуйся.
2.1 В России
В 1994 году Главным управлением безопасности связи ФАПСИ был разработан первый российский стандарт ЭЦП — ГОСТ Р 34.10-94 «Информационная технология. Криптографическая защита информации. Процедуры выработки и проверки электронной цифровой подписи на базе асимметричного криптографического алгоритма».
В 2002 году для обеспечения большей криптостойкости алгоритма взамен ГОСТ Р. 34.10-94 был введён одноимённый стандарт ГОСТ Р. 34.10-2001, основанный на вычислениях в группе точек эллиптической кривой[6]. В соответствии с этим стандартом, термины «электронная цифровая подпись» и «цифровая подпись» являются синонимами.
1 января 2013 года ГОСТ Р. 34.10-2001 заменён на ГОСТ Р. 34.10-2012 «Информационная технология. Криптографическая защита информации. Процессы формирования и проверки электронной цифровой подписи.»
3. Алгоритмы
Существует несколько схем построения цифровой подписи:
На основе алгоритмов симметричного шифрования. Данная схема предусматривает наличие в системе третьего лица — арбитра, пользующегося доверием обеих сторон. Авторизацией документа является сам факт зашифрования его секретным ключом и передача его арбитру.
На основе алгоритмов асимметричного шифрования. На данный момент такие схемы ЭП наиболее распространены и находят широкое применение.
Кроме этого, существуют другие разновидности цифровых подписей (групповая подпись, неоспоримая подпись, доверенная подпись), которые являются модификациями описанных выше схем. Их появление обусловлено разнообразием задач, решаемых с помощью ЭП.
3.1 Использование хэш-функций
Поскольку подписываемые документы — переменного (и как правило достаточно большого) объёма, в схемах ЭП зачастую подпись ставится не на сам документ, а на него хэш. Для вычисления хэша используются криптографические хэш-функции, что гарантирует выявление изменений документа при проверке подписи. Хэш-функции не являются частью алгоритма ЭП, поэтому в схеме может быть использована любая надёжная хэш-функция. Использование хэш-функций даёт следующие преимущества:
Вычислительная сложность. Обычно хэш цифрового документа делается во много раз меньшего объёма, чем объём исходного документа, и алгоритмы вычисления хэша являются более быстрыми, чем алгоритмы ЭП. Поэтому формировать хэш документа и подписывать его получается намного быстрее, чем подписывать сам документ.
Совместимость. Большинство алгоритмов оперирует со строками бит данных, но некоторые используют другие представления. Хэш-функцию можно использовать для преобразования произвольного входного текста в подходящий формат.
Целостность. Без использования хэш-функции большой электронный документ в некоторых схемах нужно разделять на достаточно малые блоки для применения ЭП. При верификации невозможно определить, все ли блоки получены и в правильном ли они порядке.
Использование хэш-функции не обязательно при электронной подписи, а сама функция не является частью алгоритма ЭП, поэтому хэш-функция может использоваться любая или не использоваться вообще.
В большинстве ранних систем ЭП использовались функции с секретом, которые по своему назначению близки к односторонним функциям. Такие системы уязвимы к атакам с использованием открытого ключа (см. ниже), так как, выбрав произвольную цифровую подпись и применив к ней алгоритм верификации, можно получить исходный текст. Чтобы избежать этого, вместе с цифровой подписью используется хэш-функция, то есть, вычисление подписи осуществляется не относительно самого документа, а относительно его хэша. В этом случае в результате верификации можно получить только хэш исходного текста, следовательно, если используемая хэш-функция криптографические стойкая, то получить исходный текст будет вычислительно сложно, а значит, атака такого типа становится невозможной.
Шифруем по-русски, или отечественные криптоалгоритмы
В данной статье простыми словами описаны криптоалгоритмы, являющиеся актуальными на данный момент российскими стандартами защиты информации, и подобраны ссылки на материалы, которые при желании помогут разобраться с ними глубже. А также, в конце статьи приведены работы с результатами криптоанализа одного из важнейших элементов данных алгоритмов.
Из новостей
За ближайший год не раз появлялись новости о предложениях расширять области использования отечественной криптографии. Чтобы представить сроки реализации предложений, стоит упомянуть ряд новостей.

До конца 2020 года планируется «закончить создание национального удостоверяющего центра — структуры, которая будет выдавать сайтам в Рунете отечественные цифровые сертификаты», пишет Медуза. Также, по данным этого издательства отечественные цифровые сертификаты будут использовать криптоалгоритмы Магма и Кузнечик. Кроме того, отечественные алгоритмы шифрования по требованию Центробанка станут обязательными к использованию в платежных системах уже с 2024 года, пишет РБК.
Добавим к этому новость от газеты Коммерсантъ, в которой Магма и Кузнечик упоминаются в контексте тестируемых алгоритмов для использования в виртуальных сим-картах eSim.
Упомянутые выше и другие основные алгоритмы, используемые в отечественной криптографии стандартизованы и описаны в ГОСТах.
Направления ГОСТов
Отечественная криптография базируется на четырех основных объектах, которые мы рассмотрим далее.
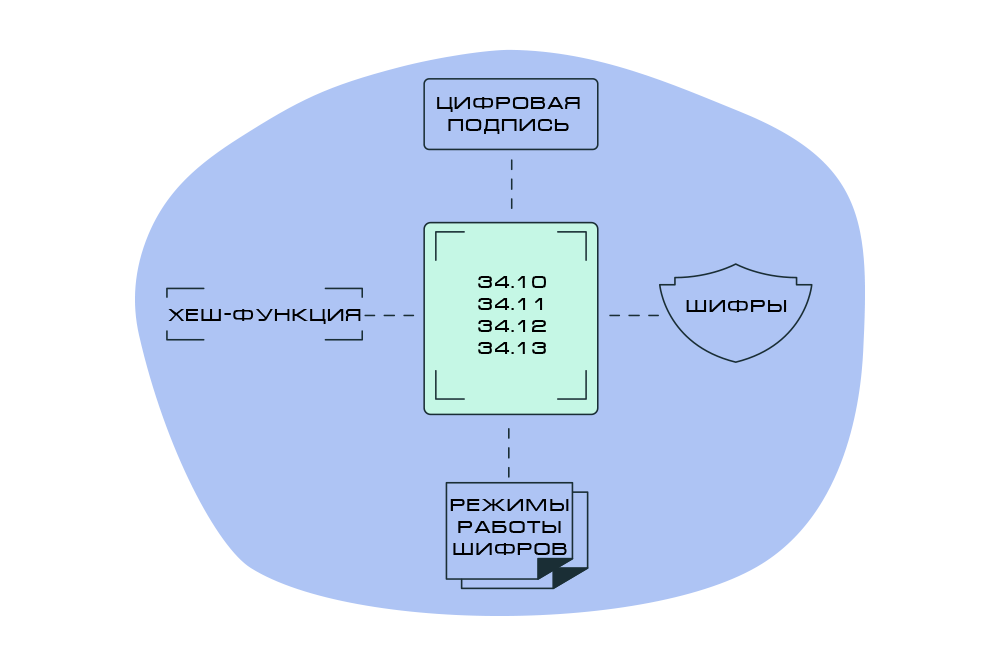
Цифровая подпись
ГОСТ 34.10-2018 описывает алгоритмы формирования и проверки электронной цифровой подписи с помощью операций в группе точек эллиптической кривой и функции хеширования. Длины секретного ключа 256 бит и 512 бит.
У пользователя есть сообщение, ключ подписи и ключ для проверки подписи. Ключ проверки подписи является открытым, для того, чтобы любой получатель смог расшифровать и убедиться в достоверности подписи. То есть если получателю удается расшифровать сообщение с помощью открытого ключа проверки подписи, принадлежащего определенному отправителю, то он может быть уверен, что сообщение подписывалось ключом подписи именно этого отправителя.
В алгоритмах формирования и проверки электронной цифровой подписи важным шагом является вычисление точки на эллиптической кривой, поэтому, прежде чем переходить к самим алгоритмам, приведем используемые понятия.
Эллиптической кривой над конечным простым полем , где , называется множество точек , , удовлетворяющих уравнению (в форме Вейерштрасса) , где , .
Альтернативный способ задать эллиптическую кривую
Отметим, что эллиптическую кривую можно задать уравнением не только в форме Вейерштрасса. Относительно новым способом задания эллиптической кривой является уравнение в форме Эдвардса .
Суммой точек , эллиптической кривой называется точка , координаты которой определяются, как , , где .
Точка эллиптической кривой , может быть определена через сумму точек .
Разбор теории, необходимой для криптографии на эллиптических кривых, можно найти тут.
Алгоритмы формирования и проверки электронной цифровой подписи.
Подпись создается по следующему алгоритму.

входные данные: сообщение и закрытый ключ подписи .
— к сообщению применяется хеш-функция(Стрибог) и вычисляется хеш-код сообщения , отметим, что хеш-код — это строка бит.
— определяется число , где — целое число, которое соответствует двоичному представлению хеш-кода . Причем если , то принимается за 1.
— это порядок порядок циклической подгруппы группы точек эллиптической кривой, который является одним из параметров цифровой подписи. Также среди параметров есть — это базовая точка подгруппы.
— на основе случайно сгенерированного целого числа , это число называют секретным ключом. Затем вычисляется точка на эллиптической кривой . Точка имеет координаты .
— из координаты точки на эллиптической кривой и преобразования хеша вычисляется электронная подпись , где . Если либо , либо равняется 0, то нужно вернуться к предыдущему шагу.
выходные данные: цифровая подпись которую добавляют к сообщению.
Теперь перейдем к алгоритму проверки подписи.
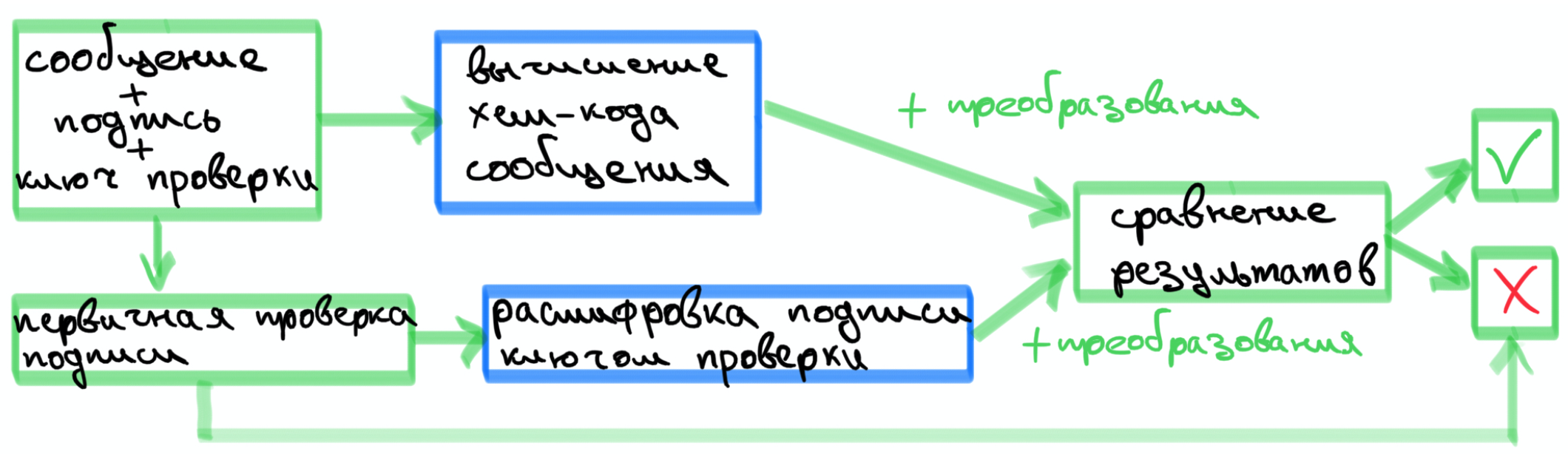
входные данные: сообщение c цифровой подписью и ключ проверки подписи
— полученная цифровая подпись проходит первичную проверку, если проверка не пройдена, то есть не выполнены неравенства , то подпись неверна.
— вычисляется хеш-код сообщения , опять же с помощью алгоритма Стрибог.
— определяется число , где целое число, которое соответсвует двоичному представлению хеш-кода . Причем если , то принимается за 1. Затем определяется .
— вычисляется точка эллиптической кривой , из которой получается .
— если , то подпись верна
выходные данные: подпись вена/неверна
Хеш-функция
ГОСТ 34.11-2018 посвящен функции хеширования. В данном документе содержится описание алгоритма вычисления хеш-функции, известной из предыдущих версий стандарта, как Стрибог.
Стрибог принимает на вход сообщение произвольной длины, которое впоследствии разбивается на блоки размером 512 бит(с дополнением блоков при необходимости). После чего входные данные преобразуются в хеш-код фиксированной длинны 256 или 512 бит.
Подробное описание алгоритма вместе с разбором используемых в нем преобразований можно найти в статье @NeverWalkAloner.
Шифры
ГОСТ 34.12-2018 охватывает блочные шифры. Именно в этом ГОСТе описаны алгоритмы шифрования Кузнечик и Магма — алгоритмы блочного шифрования с длинами шифруемых блоков 128 бит и 64 бита соответсвенно и длиной ключа шифрования 256 бит у обоих.
Шифрование блока открытого теста Кузнечиком происходит в 10 раундов, для каждого раунда из исходного ключа шифрования генерируется пара раундовых ключей, в каждом раунде проходят стадии подстановки и перестановки (перестановка вызывает особый интерес для криптоанализа алгоритма).
Приведем упрощенную схему работы Кузнечика при зашифровании.

Расшифрование Кузнечиком реализуется путем использования обратных операций подстановки и перестановки в инвертированном порядке, также, в обратном порядке следуют и раундовые ключи.
@sevastyan01 в своей статье подробно описал алгоритм Кузнечик.
Зашифрование блока Магмой проходит в 32 раунда, для каждого раунда из исходного ключа шифрования генерируется раундовый ключ, причем алгоритм генерации ключей отличается от генерации ключей в Кузнечике.
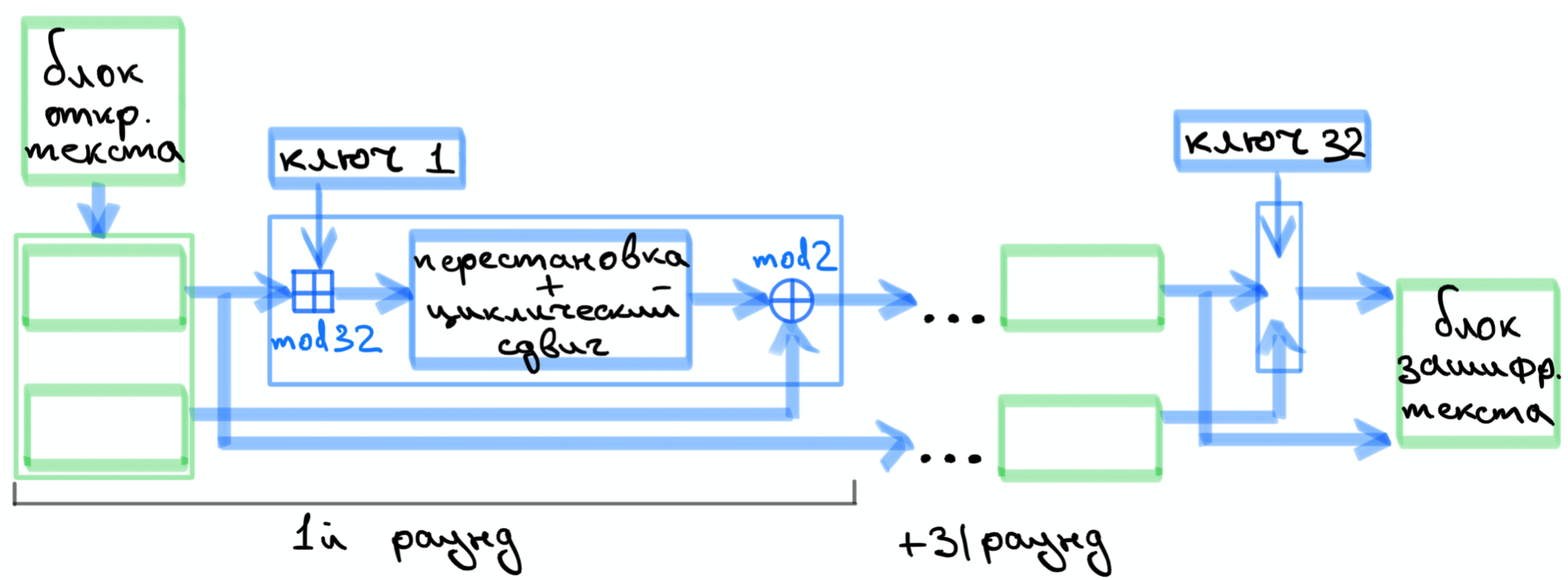
Расшифрование производится аналогичной зашифрованную последовательностью раундов, но с инвертированным порядком следования раундовых ключей.
Режимы работы шифров
ГОСТ 34.13-2018 содержит описание следующих режимов работы блочных шифров.
Режим простой замены
При зашифровании сообщение делится на блоки равной заданной длины. В случае, когда размер сообщения не кратен размеру блока, последний блок дополняется до нужной длины. Каждый блок независимо от остальных шифруется функцией, выполняющей блочное шифрования с использованием ключа.

Расшифрование происходит аналогичным образом. Причем если при зашифровании было применено дополнение, то при расшифровании применяется обратная операция.

Режим гаммирования
В данном режиме работы при шифровании каждый блок открытого текста складывается с блоком гаммы путем операции побитового сложения по модулю 2, XOR. Под гаммой понимается зашифрованная с использованием ключа последовательность, которую вырабатывает определенный алгоритм, который принимает на вход вектор инициализации.
Схематично изобразим данный режим при зашифровании и расшифровании, они происходят аналогично друг другу.
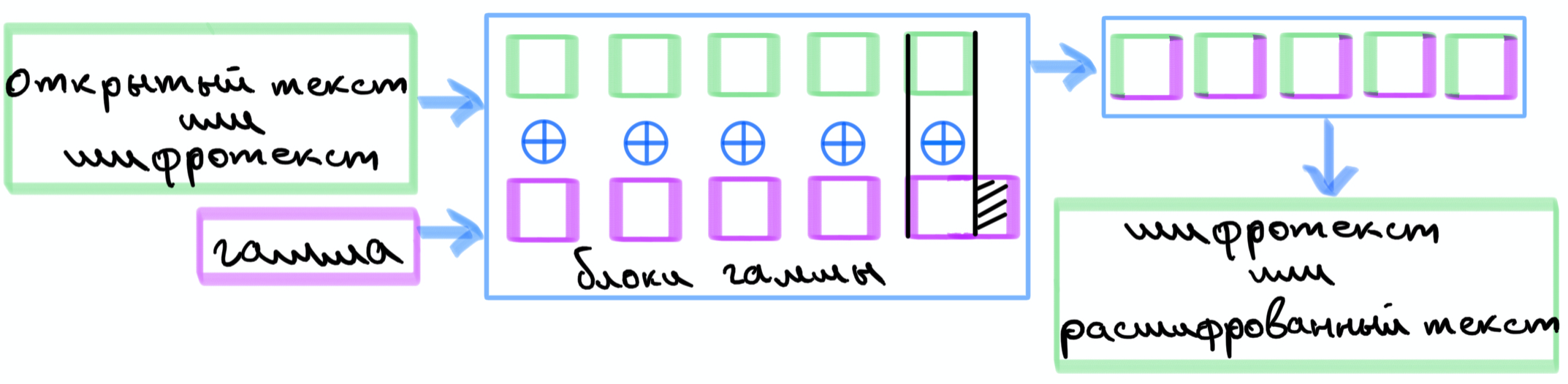
Если общая длина гаммы не кратна длине блока, то последний блок гаммы усекается до размера блока. Блоки гаммы отличны друг от друга и имеют псевдослучайных характер.
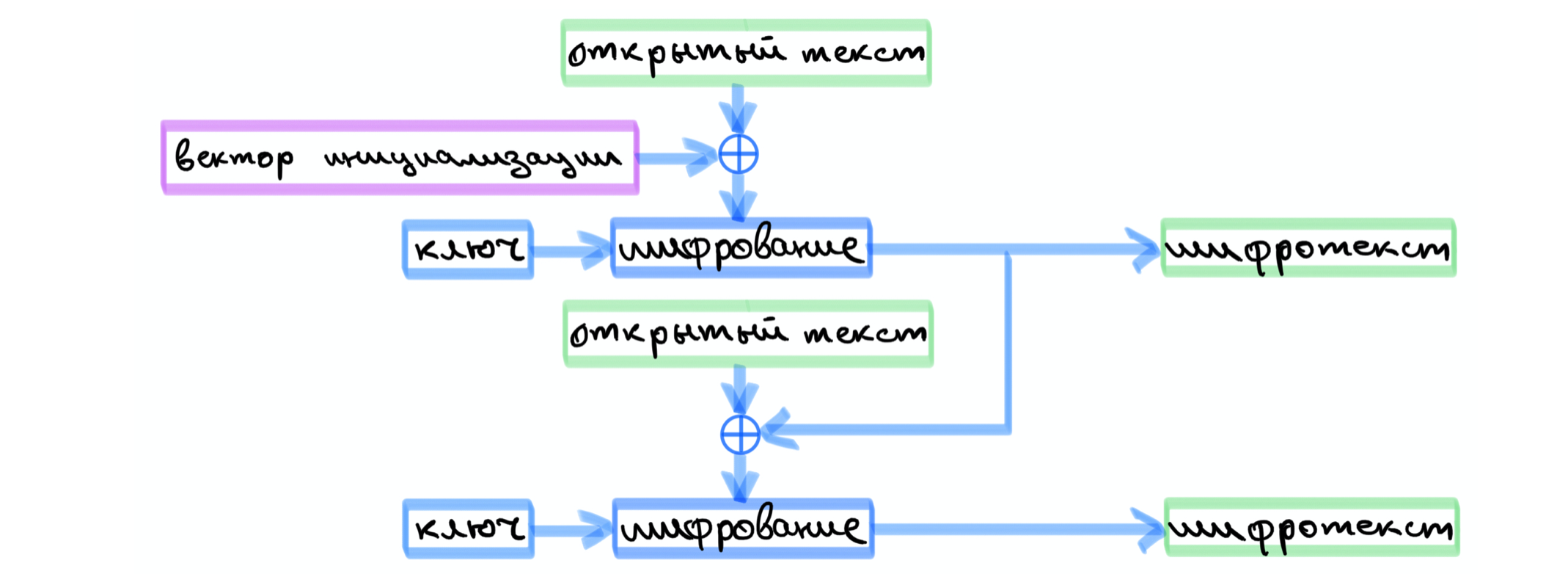
Режимы гаммирования с обратной связью: по выходу, по шифротексту
Два режима помещены в один пункт, так как они похожи между собой. В данных режимах при зашифровании выходные данные процедуры шифрования, либо сам шифротекст в случае обратной связи по шифротексту, подаются на вход следующей процедуре шифрования и так далее.
Отличие режимов можно увидеть на схеме.

При расшифровании схема преобразуется следующим образом. Шифротекст встает на место открытого текста, процедура шифрования сменяется процедурой расшифрования, а выходом алгоритма является расшифрованный текст. В дальнейших схемах будем это учитывать.
Режим простой замены с зацеплением
Особенностью данного режима работы является то, что каждый блок открытого текста, за исключением первого, складывается с предыдущим результатом шифрования.
Режим выработки имитовставки
При работе в данном режиме создается зависящий от всего текста блок, который предназначен для проверки наличия в шифротексте искажений.
Каждый из стандартов действителен с 1 июня 2019 года в соответствии с приказом Федерального агентства по техническому регулированию и метрологии. Актуальные ГОСТы наследуют разработки, прописанные в предыдущих версиях.
Реализации алгоритмов ГОСТов
@ru_crypt в своей статье собрал множество вариантов реализации ГОСТовских алгоритмов на любой вкус.
Интерес к таблице подстановок
Рассмотрим ГОСТ 34.10-2018. В алгоритмах формирования и проверки цифровой подписи на начальных шагах используется хеш-функция Стрибог, которая определена в ГОСТ 34.11-2018.
Заглянем теперь в ГОСТ 34.12-2018. В данном документе в качестве параметра алгоритма Кузнечик для нелинейного биективного преобразования приводится таблица подстановок
. Эта же таблица приведена в ГОСТ 34.11-2018, то есть используется и при хешировании.
Таблица задает единственное нелинейное преобразование в алгоритме шифрования, которое значительно усложняет взлом шифра. То есть функция подстановки особенно важна для устойчивости шифра к взломам.
Разработчики Кузнечика и Стрибога утверждают, что сгенерировали таблицу случайным образом. Однако в ряде работ был проведен криптоанализ таблицы подстановок и выявлено несколько способов ее генерации, причем не случайным образом.
Статьи с алгоритмами генерации таблицы :
В конце каждой из статей приведены алгоритмы генерации таблицы подстановок, которые можно запустить в оригинальном виде с помощью SageMath.
Заключение
В данной статье мы познакомились с основными криптоалгоритмами, которые приняты в качестве стандартов ГОСТ и получили базовое представление об их работе. А также, привели примеры работ по криптоанализу Кузнечика и Стрибога.
Чудеса хеширования
Криптографические хеш-функции — незаменимый и повсеместно распространенный инструмент, используемый для выполнения целого ряда задач, включая аутентификацию, защиту файлов и даже обнаружение зловредного ПО. Как они работают и где применяются?

Криптографические хеш-функции — незаменимый и повсеместно распространенный инструмент, используемый для выполнения целого ряда задач, включая аутентификацию, проверку целостности данных, защиту файлов и даже обнаружение зловредного ПО. Существует масса алгоритмов хеширования, отличающихся криптостойкостью, сложностью, разрядностью и другими свойствами. Считается, что идея хеширования принадлежит сотруднику IBM, появилась около 50 лет назад и с тех пор не претерпела принципиальных изменений. Зато в наши дни хеширование обрело массу новых свойств и используется в очень многих областях информационных технологий.
Что такое хеш?
Если коротко, то криптографическая хеш-функция, чаще называемая просто хешем, — это математический алгоритм, преобразовывающий произвольный массив данных в состоящую из букв и цифр строку фиксированной длины. Причем при условии использования того же типа хеша длина эта будет оставаться неизменной, вне зависимости от объема вводных данных. Криптостойкой хеш-функция может быть только в том случае, если выполняются главные требования: стойкость к восстановлению хешируемых данных и стойкость к коллизиям, то есть образованию из двух разных массивов данных двух одинаковых значений хеша. Интересно, что под данные требования формально не подпадает ни один из существующих алгоритмов, поскольку нахождение обратного хешу значения — вопрос лишь вычислительных мощностей. По факту же в случае с некоторыми особо продвинутыми алгоритмами этот процесс может занимать чудовищно много времени.
Как работает хеш?
Например, мое имя — Brian — после преобразования хеш-функцией SHA-1 (одной из самых распространенных наряду с MD5 и SHA-2) при помощи онлайн-генератора будет выглядеть так: 75c450c3f963befb912ee79f0b63e563652780f0. Как вам скажет, наверное, любой другой Брайан, данное имя нередко пишут с ошибкой, что в итоге превращает его в слово brain (мозг). Это настолько частая опечатка, что однажды я даже получил настоящие водительские права, на которых вместо моего имени красовалось Brain Donohue. Впрочем, это уже другая история. Так вот, если снова воспользоваться алгоритмом SHA-1, то слово Brain трансформируется в строку 97fb724268c2de1e6432d3816239463a6aaf8450. Как видите, результаты значительно отличаются друг от друга, даже несмотря на то, что разница между моим именем и названием органа центральной нервной системы заключается лишь в последовательности написания двух гласных. Более того, если я преобразую тем же алгоритмом собственное имя, но написанное уже со строчной буквы, то результат все равно не будет иметь ничего общего с двумя предыдущими: 760e7dab2836853c63805033e514668301fa9c47.
Впрочем, кое-что общее у них все же есть: каждая строка имеет длину ровно 40 символов. Казалось бы, ничего удивительного, ведь все введенные мною слова также имели одинаковую длину — 5 букв. Однако если вы захешируете весь предыдущий абзац целиком, то все равно получите последовательность, состоящую ровно из 40 символов: c5e7346089419bb4ab47aaa61ef3755d122826e2. То есть 1128 символов, включая пробелы, были ужаты до строки той же длины, что и пятибуквенное слово. То же самое произойдет даже с полным собранием сочинений Уильяма Шекспира: на выходе вы получите строку из 40 букв и цифр. При всем этом не может существовать двух разных массивов данных, которые преобразовывались бы в одинаковый хеш.
Вот как это выглядит, если изобразить все вышесказанное в виде схемы:

Для чего используется хеш?
Отличный вопрос. Однако ответ не так прост, поскольку криптохеши используются для огромного количества вещей.
Для нас с вами, простых пользователей, наиболее распространенная область применения хеширования — хранение паролей. К примеру, если вы забыли пароль к какому-либо онлайн-сервису, скорее всего, придется воспользоваться функцией восстановления пароля. В этом случае вы, впрочем, не получите свой старый пароль, поскольку онлайн-сервис на самом деле не хранит пользовательские пароли в виде обычного текста. Вместо этого он хранит их в виде хеш-значений. То есть даже сам сервис не может знать, как в действительности выглядит ваш пароль. Исключение составляют только те случаи, когда пароль очень прост и его хеш-значение широко известно в кругах взломщиков. Таким образом, если вы, воспользовавшись функцией восстановления, вдруг получили старый пароль в открытом виде, то можете быть уверены: используемый вами сервис не хеширует пользовательские пароли, что очень плохо.
Вы даже можете провести простой эксперимент: попробуйте при помощи специального сайта произвести преобразование какого-нибудь простого пароля вроде «123456» или «password» из их хеш-значений (созданных алгоритмом MD5) обратно в текст. Вероятность того, что в базе хешей найдутся данные о введенных вами простых паролях, очень высока. В моем случае хеши слов «brain» (8b373710bcf876edd91f281e50ed58ab) и «Brian» (4d236810821e8e83a025f2a83ea31820) успешно распознались, а вот хеш предыдущего абзаца — нет. Отличный пример, как раз для тех, кто все еще использует простые пароли.
Еще один пример, покруче. Не так давно по тематическим сайтам прокатилась новость о том, что популярный облачный сервис Dropbox заблокировал одного из своих пользователей за распространение контента, защищенного авторскими правами. Герой истории тут же написал об этом в твиттере, запустив волну негодования среди пользователей сервиса, ринувшихся обвинять Dropbox в том, что он якобы позволяет себе просматривать содержимое клиентских аккаунтов, хотя не имеет права этого делать.
Впрочем, необходимости в этом все равно не было. Дело в том, что владелец защищенного копирайтом контента имел на руках хеш-коды определенных аудио- и видеофайлов, запрещенных к распространению, и занес их в список блокируемых хешей. Когда пользователь предпринял попытку незаконно распространить некий контент, автоматические сканеры Dropbox засекли файлы, чьи хеши оказались в пресловутом списке, и заблокировали возможность их распространения.
Где еще можно использовать хеш-функции помимо систем хранения паролей и защиты медиафайлов? На самом деле задач, где используется хеширование, гораздо больше, чем я знаю и тем более могу описать в одной статье. Однако есть одна особенная область применения хешей, особо близкая нам как сотрудникам «Лаборатории Касперского»: хеширование широко используется для детектирования зловредных программ защитным ПО, в том числе и тем, что выпускается нашей компанией.
Как при помощи хеша ловить вирусы?
Примерно так же, как звукозаписывающие лейблы и кинопрокатные компании защищают свой контент, сообщество создает списки зловредов (многие из них доступны публично), а точнее, списки их хешей. Причем это может быть хеш не всего зловреда целиком, а лишь какого-либо его специфического и хорошо узнаваемого компонента. С одной стороны, это позволяет пользователю, обнаружившему подозрительный файл, тут же внести его хеш-код в одну из подобных открытых баз данных и проверить, не является ли файл вредоносным. С другой — то же самое может сделать и антивирусная программа, чей «движок» использует данный метод детектирования наряду с другими, более сложными.
Криптографические хеш-функции также могут использоваться для защиты от фальсификации передаваемой информации. Иными словами, вы можете удостовериться в том, что файл по пути куда-либо не претерпел никаких изменений, сравнив его хеши, снятые непосредственно до отправки и сразу после получения. Если данные были изменены даже всего на 1 байт, хеш-коды будут отличаться, как мы уже убедились в самом начале статьи. Недостаток такого подхода лишь в том, что криптографическое хеширование требует больше вычислительных мощностей или времени на вычисление, чем алгоритмы с отсутствием криптостойкости. Зато они в разы надежнее.
Кстати, в повседневной жизни мы, сами того не подозревая, иногда пользуемся простейшими хешами. Например, представьте, что вы совершаете переезд и упаковали все вещи по коробкам и ящикам. Погрузив их в грузовик, вы фиксируете количество багажных мест (то есть, по сути, количество коробок) и запоминаете это значение. По окончании выгрузки на новом месте, вместо того чтобы проверять наличие каждой коробки по списку, достаточно будет просто пересчитать их и сравнить получившееся значение с тем, что вы запомнили раньше. Если значения совпали, значит, ни одна коробка не потерялась.