2 способа. Как тестировать hash начинающему тестировщику? 2023
Хеш-функция или в народе хеш — очень важная и нужная штука, которая используется повсеместно, например в защите файлов, обнаружение вирусов, аутентификация и другое. Но как ее тестировать?
Далее вы узнаете:
- Что такое хэш-функция?
- Что такое криптографическая хэш-функция?
- Как тестировать хэш?
Поставь лайк за полезный материал❤
Хеш-функция — это математическая функция, которая принимает ввод (или «сообщение») и возвращает строку символов фиксированного размера, которая обычно представляет собой «дайджест», уникальный для уникального ввода. Одни и те же входные данные всегда будут давать один и тот же результат, но даже небольшое изменение ввода приведет к совершенно другому результату.
Хеш-функции обычно используются в структурах данных, таких как хэш-таблицы, и в криптографии. Их можно использовать для создания уникального отпечатка цифрового файла, проверки целостности данных и обнаружения дубликатов в больших наборах данных.
Криптографическая хеш-функция — это особый тип хэш-функции, обладающий определенными свойствами, делающими ее пригодной для использования в криптографии. Это односторонняя функция, что означает, что практически невозможно обратить процесс вспять и восстановить исходный ввод из хэша. Кроме того, вычислительно невозможно найти два разных входа, которые производят один и тот же хэш (известный как «коллизия»). Некоторыми примерами криптографических хеш-функций являются SHA-256, SHA-1 и MD5.
Первый способ, чтобы проверить хеш-сумму файла, вы можете использовать такой инструмент, как утилита командной строки «md5sum» (для хэша MD5), «sha1sum» (для хэша SHA-1) или «sha256sum» (для хэша SHA-256). хэш).
Основной синтаксис:
- md5sum /путь/к/файлу
- sha1sum /путь/к/файлу
- sha256sum /путь/к/файлу
Затем вы можете сравнить выходное хеш-значение с ожидаемым хэш-значением. Если они совпадают, файл считается неповрежденным и неизмененным.
Другой способ тестирования — использовать программное обеспечение, такое как Hashtab для Windows, оно даст вам значения хэша для выбранного вами файла, а также вы сможете сравнить его с ожидаемым хэшем.
Вы также можете использовать веб-сайты онлайн-калькулятора хэшей, вам просто нужно загрузить файл, и он даст вам значение хеш-функции.
Итог. Вы узнали про хэш и то, как его можно тестировать.
Хочу еще привести вам пример кейса для большего понимания:
- Возьми файл,
- Посмотри его хэш,
- Загрузи в тестовое приложение,
- Скачай,
- Посмотри хэш и сравни с прошлым.
Также хэш можно было посмотреть, после загрузки в приложение через консоль разработчика. На самом деле вариантов в разы намного больше и зависит от ваших кейсов.
Blockchain for Test Engineers: Hashing
This is the first blog post in the “Blockchain for Test Engineers” series.
When you start to study blockchain, the odds are pretty high that you will hear about hashing and hash functions.
But what is hashing? Why is it a critical concept in cryptography? Which hashing algorithms are used for different blockchains? And even more interesting — how can we test a cryptographic hash function (and should we do it at all)?
What is hashing?
Hashing can be imagined as a “box” with one input and one output. You can provide any data as an input and get a result of the fixed length.
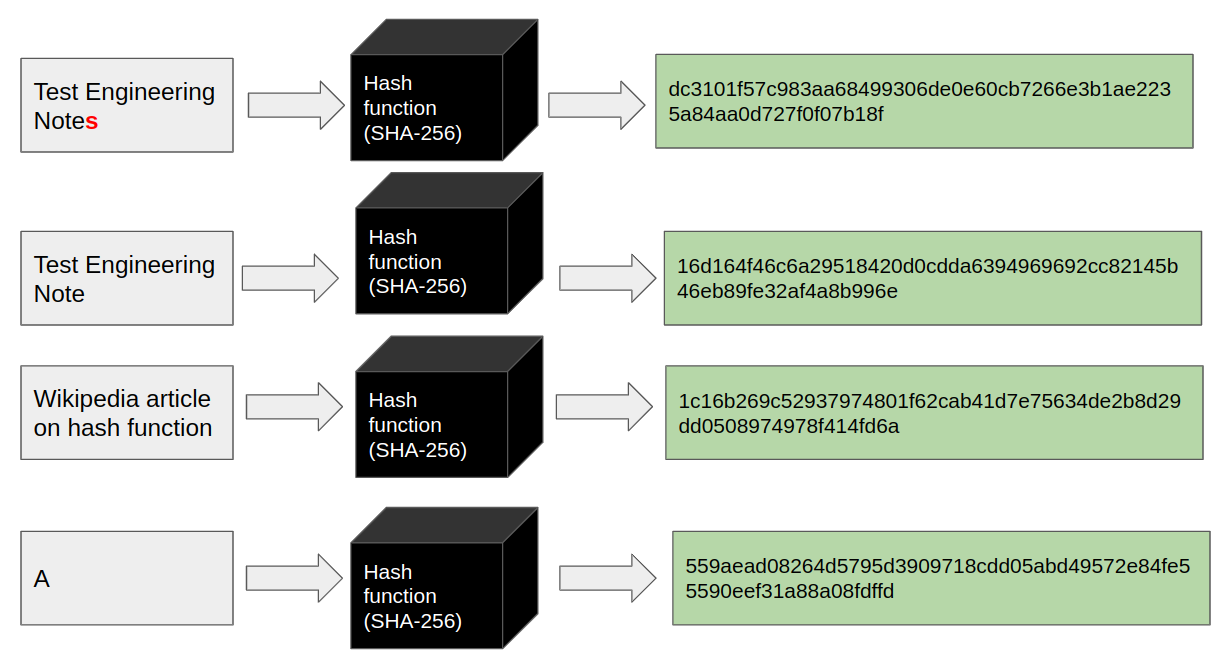
In the case of the SHA-256 hash function — the result will always be a 256-bit sequence. The most exciting thing in hashing is — that even the minimal change to the input changes the output — significantly.
As an example, let’s get the SHA-256 hash of the text “Test Engineering Notes”.
The result will be — “dc3101f57c983aa68499306de0e60cb7266e3b1ae2235a84aa0d727f0f07b18f”.
But “Test Engineering note” will have completely different hash: “16d164f46c6a29518420d0cdda6394969692cc82145b46eb89fe32af4a8b996e”.
Properties of hash functions
The two main properties of the hash function are ease of computation and determinism (the same input data should always result in the same hash).
Besides that, a good hashing function should withstand cryptographic attacks.
So it should have the following properties:
- Pre-image resistance. The hash function should be a “one-way”: Given a hash value h, it should be difficult to find any message m such that h = hash(m).
- Second pre-image resistance. Given an input m1, it should be difficult to find a different input m2 such that hash(m1) = hash(m2).
- Collision resistance. It should be difficult to find two different messages m1 and m2, such that hash(m1) = hash(m2). Such two messages are called a hash collision.
Why does hashing exist?
There are multiple applications of the hashing in the world of computers:
- With hashing, you can check the integrity of the data;
- Instead of storing user passwords as plain text in a database — it is better to keep its hashes;
- You can use hashing in the digital signatures;
- Datatypes, such as Hash Tables and Hash Maps;
- Blockchains :);
Different hash functions
The most famous are MD5, SHA-1, RIPEMD-160, BLAKE, Whirlpool, SHA-2, and SHA-3. E.g., Bitcoin (and its forks) uses SHA-256 cryptographic function, Ethereum — SHA-3 (Keccak), Cardano — BLAKE2b-224.
Those algorithms are based on some sequence of rounds with bit operations: shifts, AND, XOR operations, and others).
Lane Wagner’s blog post provides an excellent step-by-step explanation of the SHA-2 hash function. You can also try to hash something online.
It is a vast mathematical task to create new hash functions and prove their properties. National Institute of Standards and Technologyis reponsible for testing hash functions. The chosen one are added to the family of secure hash algorithms and recommeded by NIST. The last known standard algorithm (Keccak) was chosen at the NIST hash functions competition. Hash functions were evaluated by their performance, security, analysis, and diversity.
How to test hash functions?
One of the leading indicators of the quality of hash functions is the probability of getting hash collisions. So one test is to check collisions at the massive input data.
Usually, the distribution of hash values is uniform and is tested using the Chi-square test. The actual distribution of elements is compared with the expected (uniform) distribution. The ratio within the confidence interval should be in the range of 0.95 — 1.05.
Also, there is an additional test for uniformity of distribution of hashes. It is based on strict avalanche criteria — when each input bit changes with a probability of 50% in the output sequence.
Will you test hashing function as a blockchain test engineer?
As always — it depends. Many blockchains use well-known standards and rarely implement hash functions from scratch.
Suppose you will be a part of the core engineering team responsible for developing the whole blockchain from scratch. In that case, you may need to verify that hashing algorithm works as expected within the context of the system.
If you test only blockchain-based applications based on smart contracts — you don’t need to verify the hashing function in isolation. You should trust other security specialists and mathematicians who tested these functions for you. But you definitely need to know how such functions are used in your system.
How to test a hash function?
Is there a way to test the quality of a hash function? I want to have a good spread when used in the hash table, and it would be great if this is verifyable in a unit test.
EDIT: For clarification, my problem was that I have used long values in Java in such a way that the first 32 bit encoded an ID and the second 32 bit encoded another ID. Unfortunately Java’s hash of long values just XORs the first 32 bit with the second 32 bits, which in my case led to very poor performance when used in a HashMap . So I need a different hash, and would like to have a Unit Test so that this problem cannot creep in any more.
4 Answers 4
You have to test your hash function using data drawn from the same (or similar) distribution that you expect it to work on. When looking at hash functions on 64-bit longs, the default Java hash function is excellent if the input values are drawn uniformly from all possible long values.
However, you’ve mentioned that your application uses the long to store essentially two independent 32-bit values. Try to generate a sample of values similar to the ones you expect to actually use, and then test with that.
For the test itself, take your sample input values, hash each one and put the results into a set. Count the size of the resulting set and compare it to the size of the input set, and this will tell you the number of collisions your hash function is generating.
For your particular application, instead of simply XORing them together, try combining the 32-bit values in ways a typical good hash function would combine two indepenet ints. I.e. multiply by a prime, and add.
First I think you have to define what you mean by a good spread to yourself. Do you mean a good spread for all possible input, or just a good spread for likely input?
For example, if you’re hashing strings that represent proper full (first+last) names, you’re not going to likely care about how things with the numerical ASCII characters hash.
As for testing, your best bet is to probably get a huge or random input set of data you expect, and push it through the hash function and see how the spread ends up. There’s not likely going to be a magic program that can say «Yes, this is a good hash function for your use case.». However, if you can programatically generate the input data, you should easily be able to create a unit test that generates a significant amount of it and then verify that the spread is within your definition of good.
Edit: In your case with a 64 bit long, is there even really a reason to use a hash map? Why not just use a balanced tree directly, and use the long as the key directly rather than rehashing it? You pay a little penalty in overall node size (2x the size for the key value), but may end up saving it in performance.
If your using a chaining hash table, what you really care about is the number of collisions. This would be trivial to implement as a simple counter on your hash table. Every time an item is inserted and the table has to chain, increment a chain counter. A better hashing algorithm will result in a lower number of collisions. A good general purpose table hashing function to check out is: djb2
Based on your clarification:
I have used long values in Java in such a way that the first 32 bit encoded an ID and the second 32 bit encoded another ID. Unfortunately Java’s hash of long values just XORs the first 32 bit with the second 32 bits, which in my case led to very poor performance when used in a HashMap.
it appears you have some unhappy «resonances» between the way you assign the two ID values and the sizes of your HashMap instances.
Are you explicitly sizing your maps, or using the defaults? A QAD check seems to indicate that a HashMap<Long,String> starts with a 16-bucket structure and doubles on overflow. That would mean that only the low-order bits of the ID values are actually participating in the hash bucket selection. You could try using one of the constructors that takes an initial-size parameter and create your maps with a prime initial size.
Alternately, Dave L’s suggestion of defining your own hashing of long keys would allow you to avoid the low-bit-dependency problem.
Another way to look at this is that you’re using a primitive type (long) as a way to avoid defining a real class. I’d suggest looking at the benefits you could achieve by defining the business classes and then implementing hash-coding, equality, and other methods as appropriate on your own classes to manage this issue.
Как работает хэширование

Если вы программист, то пользуетесь хэш-функциями каждый день. Они применяются в базах данных для оптимизации запросов, в структурах данных для ускорения работы, в безопасности для защиты данных. Почти каждое ваше взаимодействие с технологией тем или иным образом включает в себя хэш-функции.
Хэш-функции фундаментальны и используются повсюду .
Но что же такое хэш-функции и как они работают?
В этом посте я собираюсь развенчать мифы вокруг этих функций. Мы начнём с простой хэш-функции, узнаем, как проверить, хороша ли хэш-функция, а затем рассмотрим реальный пример применения хэш-функции: хэш-таблицу.
В оригинале статьи многие иллюстрации интерактивны
Что такое хэш-функция?
Хэш-функции — это функции, получающие на входе данные, обычно строку, и возвращающие число. При многократном вызове хэш-функции с одинаковыми входными данными она всегда будет возвращать одно и то же число, и возвращаемое число всегда будет находиться в гарантированном интервале. Этот интервал зависит от хэш-функции: в некоторых используются 32-битные целочисленные значения (то есть от 0 до 4 миллиардов), в других интервалы гораздо больше.
Если бы мы захотели написать на JavaScript имитацию хэш-функции, то она могла бы выглядеть так:
Даже не зная, как используются хэш-функции, мы бы могли понять, что эта функция бесполезна. Давайте узнаем, как определить качественность хэш-функции, а чуть позже мы поговорим о том, как они используются в хэш-таблицах.
Какая хэш-функция может считаться хорошей?
Так как input может быть любой строкой, а возвращаемое число находится в каком-то гарантированном интервале, может случиться так, что при двух разных входных строках будет возвращено одно и то же число. Это называется «коллизией»; хорошие хэш-функции стремятся к минимизации создаваемых ими коллизий.
Однако полностью избавиться от коллизий невозможно. Если бы мы написали хэш-функцию, возвращающую число в интервале от 0 до 7, и передали бы ей 9 уникальных входных значений, то гарантированно получили бы как минимум 1 коллизию.

Выходные значения хорошо известной хэш-функции modulo 8 (деление на 8 с остатком). Какие бы 9 значений мы ни передали, есть всего 8 уникальных чисел, поэтому коллизии неизбежны. Цель заключается в том, чтобы их было как можно меньше.
Для визуализации коллизий я использую сетку. Каждый квадрат в сетке будет обозначать число, возвращаемое хэш-функцией. Вот пример сетки 8×2.
В дальнейшем при каждом хэшировании значения мы будем делать соответствующий ему квадрат в сетке чуть темнее. Смысл в том, чтобы наглядно показать, насколько хорошо хэш-функция избегает коллизий. Мы стремимся получить хорошее равномерное распределение. Будет понятно, что функция плоха, если у нас получатся скопления или паттерны из тёмных квадратов.
Вы сказали, что когда хэш-функция возвращает одинаковое значение для двух входных данных, это называется коллизией. Но если у нас будет хэш-функция, которая возвращает значения в большом интервале, а мы накладываем их на маленькую сетку, то не создадим ли мы множество коллизий, которые на самом деле не будут коллизиями? В нашей сетке 8×2 и 1, и 17 соответствуют второму квадрату.
Отличное замечание. Ты совершенно права, в нашей сетке будут возникать «псевдоколлизии». Но это приемлемо, потому что если хэш-функция хороша, то мы всё равно увидим равномерное распределение. Инкремент каждого квадрата на 100 — это столь же хорошее распределение, как и инкремент каждого квадрата на 1. Если мы получим хэш-функцию с большой степенью коллизий, то это всё равно будет бросаться в глаза. Вскоре мы сами в этом убедимся.
Давайте возьмём сетку побольше и хэшируем 1000 случайно сгенерированных строк. Анимация сетки показывает, как каждое входное значение хэшируется и помещается в сетку.
Значения распределяются равномерно, потому что мы используем хорошо изученную хэш-функцию под названием murmur3 . Эта функция широко используется в реальных приложениях благодаря своему отличному распределению, а также очень высокой скорости работы.
Как бы выглядела наша сетка, если бы мы использовали плохую хэш-функцию?
Эта хэш-функция циклически обходит всю переданную ей строку и суммирует числовые значения каждого символа. Затем она делает так, чтобы значение находилось в интервале от 0 до 1000000 при помощи оператора деления с остатком ( % ). Назовём эту хэш-функцию stringSum .
Вот как она выглядит в сетке. Напомню, что это 1000 случайно сгенерированных строк, которые мы хэшируем.
Не сильно отличается от murmur3 . В чём же дело?
Проблема в том, что передаваемые на хэширование строки случайны. Давайте посмотрим, как ведёт себя каждая функция, когда входные данные не случайны: это будут числа от 1 до 1000, преобразованные в строки.

Теперь проблема стала очевиднее. Когда входные данные не случайны, выходные данные stringSum образуют паттерн. А сетка murmur3 выглядит так же, как и при случайных значениях.

Разница менее заметна, но мы всё равно видим паттерн в сетке stringSum . Функция murmur3 снова выглядит, как обычно.
В этом и состоит сила хорошей хэш-функции: какими бы ни были входные данные, выходные данные всегда распределены равномерно. Давайте поговорим о ещё одном способе визуализации этого, а затем расскажем, почему это важно.
▍ Лавинный эффект
Ещё один способ проверки хэш-функций — это так называемый «лавинный эффект». Это показатель того, какое количество битов меняется в выходном значении при изменении всего одного бита во входном значении. Чтобы можно было сказать, что хэш-функция имеет хороший лавинный эффект, смена одного бита во входном значении должна приводить в среднем к смене 50% битов в выходном значении.
Именно это свойство помогает хэш-функциям не создавать паттерны в сетке. Если небольшое изменение во входных данных приводит к небольшим изменениям в выходных, то возникнут паттерны. Паттерны — это показатели плохого распределения и повышенного уровня коллизий.
Ниже мы показали лавинный эффект на примере двух 8-битных двоичных чисел. Верхнее число — это входное значение, а нижнее — выходное значение murmur3 . Каждый раз во входном значении меняется один бит. Изменившиеся в выходном значении биты будут выделены зелёным , а неизменившиеся биты — оранжевым .
murmur3 проявляет себя хорошо, несмотря на то, что иногда меняется меньше 50% битов, а иногда больше. И это нормально, если в среднем получается 50%.
Давайте посмотрим, как ведёт себя stringSum .
А вот это уже отвратительно. Выходные данные равны входным, поэтому каждый раз меняется только один бит. И это логично, ведь stringSum просто суммирует числовое значение каждого символа в строке. Этот пример хэширует эквивалент одного символа, то есть выходное значение всегда будет таким же, как входное.
Почему всё это важно
Мы поговорили о нескольких способах определения качественности хэш-функций, но не обсудили, почему это важно. Давайте исправим это, рассмотрев хэш-таблицы (hash map).
Чтобы понять хэш-таблицы, нужно сначала понять, что такое map. Map — это структура данных, позволяющая хранить пары «ключ-значение». Вот пример на JavaScript:
Здесь мы берём пару «ключ-значение» ( «hello» → «world» ) и сохраняем её в map. Затем мы выводим значение, связанное с ключом «hello» , то есть «world» .
Более интересным примером реального использования стал бы поиск анаграмм. Анаграмма — это когда два разных слова состоят из одинаковых букв, например, «апельсин» и «спаниель» или «кабан» и «банка». Если у вас есть список слов, и вы хотите найти все анаграммы, то можно отсортировать буквы в каждом слове по алфавиту и использовать эту строку как ключ структуры map.
В результате выполнения этого кода мы получаем map со следующей структурой:
▍ Реализация собственной простой хэш-таблицы
Хэш-таблицы — одна из множества реализаций map; также существует множество способов реализации хэш-таблиц. Простейший способ, который мы и покажем — это список списков. Внутренние списки в реальном мире часто называют «bucket», поэтому так мы их и будем называть. Хэш-функция применяется к ключу для определения того, в каком bucket должна храниться пара «ключ-значение», после чего эта пара «ключ-значение» добавляется в bucket.
Давайте рассмотрим простую реализацию хэш-таблицы на JavaScript. Мы изучим её снизу вверх, то есть сначала рассмотрим вспомогательные методы, а затем перейдём к реализациям set и get .
Мы начнём с создания класса HashMap с конструктором, настраивающим три bucket. Мы используем три bucket и короткое имя переменной bs , чтобы этот код удобно было просматривать на устройствах с маленькими экранами. В реальном коде можно создавать любое количество bucket (и придумать более осмысленные имена переменных).
В методе bucket к переданному key применяется murmur3 , чтобы найти bucket, который нужно использовать. Это единственное место в нашем коде хэш-таблицы, где используется хэш-функция.
Метод entry получает bucket и key и сканирует bucket, пока не найдёт элемент с указанным ключом. Если элемент не найден, возвращается null .
Метод set мы первым узнаём из предыдущих примеров Map на JavaScript. Он получает пару «ключ-значение» и сохраняет её в хэш-таблицу. Он делает это при помощи созданных ранее методов bucket и entry . Если элемент найден, то значение перезаписывается. Если элемент не найден, то пара «ключ-значение» добавляется в map. В JavaScript < key, value >— это более компактная запись < key: key, value: value >.
Метод get очень похож на set . Он использует bucket и entry для поиска элемента, связанного с переданным key , точно так же, как это делает set . Если элемент найден, возвращается его value . Если он не найден, то возвращается null .
Объём кода получился довольно большим. Главное, что нужно из него понять: наша хэш-таблица — это список списков, а хэш-функция используется для того, чтобы понять, в каком из списков хранить ключ и откуда его извлекать.
Вот визуальное представление этой хэш-таблицы. При помощи set добавляется новая пара «ключ-значение». Чтобы не усложнять визуализацию, если bucket должен «переполниться», то все bucket очищаются.
Так как мы используем в качестве хэш-функции murmur3 , то распределение между bucket оказывается хорошим. Можно ожидать частичный дисбаланс, но обычно распределение достаточно равномерное.
Чтобы получить значение из хэш-таблицы, мы сначала хэшируем ключ, чтобы понять, в каком из bucket будет находиться значение. Затем нам нужно сравнить ключ, который мы ищем, со всеми ключами в bucket.
Именно этот этап поиска мы минимизируем при помощи хэширования, и именно благодаря ему murmur3 оптимизирована по скорости. Чем быстрее хэш-функция, тем быстрее мы отыскиваем нужный bucket для поиска, и тем быстрее наша хэш-таблица в целом.
Кроме того, из-за этого так важно снижение количества коллизий. Если бы мы решили использовать имитацию хэш-функции из начала статьи, постоянно возвращающую 0, то поместили бы все пары «ключ-значение» в первый bucket. Для поиска любого элемента нам пришлось бы проверить все значения в хэш-таблице. При хорошей хэш-функции с хорошим распределением мы снижаем количество необходимых операций поиска до 1/N, где N — это количество bucket.
Давайте посмотрим, как проявляет себя здесь stringSum .
Любопытно: кажется, stringSum распределяет достаточно неплохо. Мы замечаем паттерн, но в целом распределение выглядит хорошим.
Наконец-то! Победа stringSum ! Я знала, что она когда-нибудь пригодится.
Не торопись, Хаски. Нам нужно обсудить серьёзную проблему. Распределение выглядит приемлемым при этих последовательных числах, однако мы видели, что у stringSum плохой лавинный эффект. Всё это не кончится ничем хорошим.
Коллизии в реальном мире
Давайте рассмотрим два массива данных из реального мира: IP-адреса и английские слова. Я возьму 100 000 000 случайных IP-адресов и 466 550 английских слов, хэширую их murmur3 и stringSum , а потом посмотрю, сколько коллизий мы получим.
| murmur3 | stringSum | |
| Коллизии | 1 156 959 | 99 999 566 |
| 1,157% | 99,999% |
Английские слова
| murmur3 | stringSum | |
| Коллизии | 25 | 464 220 |
| 0,005% | 99,5% |
Когда мы используем хэш-таблицы в реальности, то обычно не храним в них случайные значения. В качестве примера можно представить подсчёт количества запросов, в которых встречался IP-адрес, в коде вычисления ограничения частоты доступа к серверу. Или код, подсчитывающий количество вхождений слов в книгах на протяжении веков для отслеживания их происхождения и популярности. В этих областях применения stringSum ужасна из-за своей чрезвычайно высокой частоты коллизий.
Синтетические коллизии
А теперь настало время плохих новостей для murmur3 . Нам стоит учитывать не только коллизии, вызванные схожестью входных данных. Взгляните:
Что здесь происходит? Почему все эти бессмысленные строки хэшируются в одинаковое число?
Я хэшировал 141 триллион случайных строк, чтобы найти значения, при использовании murmur3 хэшируемые в число 1228476406 . Хэш-функции всегда должны возвращать одинаковый результат для конкретного входного значения, поэтому можно найти коллизии простым перебором.
Простите, 141 триллион ? Это… 141 и 12 нулей?
Да, и это заняло у меня всего 25 минут. Компьютеры очень быстры.
Наличие у злоумышленников лёгкого доступа к коллизиям может иметь катастрофические последствия, если ваше ПО создаёт хэш-таблицы из пользовательского ввода. Возьмём для примера HTTP-заголовки. HTTP-запрос выглядит так:
Вам необязательно понимать все слова, достаточно знать, что первая строка — это запрашиваемый путь, а все остальные строки — это заголовки. Заголовки — это пары Key: Value , поэтому HTTP-серверы обычно хранят их в таблицах. Ничто не мешает нам отправить любые нужные заголовки, поэтому мы можем быть очень жестокими и передать заголовки, которые, как нам известно, вызовут коллизии. Это может существенно замедлить сервер.
И это не теоретические рассуждения. Если вы поищите «HashDoS», то сможете найти ещё множество примеров этого. В середине 2000-х это была очень серьёзная проблема.
Есть несколько способов решения этой проблемы конкретно для HTTP-серверов: например, игнорирование бессмысленных ключей заголовков и ограничение количества хранимых заголовков. Однако современные хэш-функции наподобие murmur3 предоставляют более общее решение: рандомизацию.
Выше в этом посте мы показали несколько примеров реализаций хэш-функций. Эти реализации получают единственный аргумент: input . Многие из современных хэш-функций получают второй параметр: порождающее значение ( seed ) (иногда называемое «солью» ( salt )). В случае murmur3 этим seed является число.
Пока мы использовали в качестве seed значение 0. Давайте посмотрим, что произойдёт с собранными мной коллизиями при использовании seed, равного 1.
Именно так: простой заменой 0 на 1 мы избавились от всех коллизий. В этом и заключается предназначение seed: он непредсказуемым образом рандомизирует выходные данные хэш-функции. То, как он этого достигает, не относится к теме нашей статьи, каждая хэш-функция делает это по-своему.
Хэш-функция по-прежнему возвращает одинаковые выходные данные для одинаковых входных данных, только теперь входные данные — это сочетание input и seed . Те значения, у которых возникают коллизии при одном seed, не приводят к коллизиям при использовании другого. Языки программирования в начале процесса часто генерируют случайное число для использования в качестве seed, чтобы каждый раз при запуске программы seed различался. Если я злоумышленник, не знающий seed, то больше не могу стабильно наносить ущерб.
Если внимательно присмотреться к двум предыдущим визуализациям, то можно заметить, что в них хэшируются одинаковые значения, но они создают разные значения хэша. Из этого следует, что если вы хэшируете значение с одним seed, и хотите в будущем выполнять сравнения с ним, то необходимо использовать одинаковый seed.
Использование разных значений для разных seed не влияет на применение хэш-таблиц, потому что хэш-таблицы существуют только во время выполнения программы. При условии, что на протяжении всего срока работы программы вы используете один seed, ваши хэш-таблицы будут без проблем работать. Если вам нужно сохранить значения хэша вне своей программы, например, в файл, то обязательно знать, какой seed использовался.
Песочница
По традиции я создал песочницу, в которой вы можете писать собственные хэш-функции и визуализировать их в сетках, как в этой статье. Поэкспериментировать с песочницей можно здесь.
Заключение
Мы поговорили о том, что такое хэш-функции, рассказали о некоторых способах оценки их качества, объяснили, что происходит, когда они плохие; также мы узнали о нескольких способах, которыми их могут взломать злоумышленники.
Вселенная хэш-функций велика, и в этом посте мы рассказали о ней лишь поверхностно. Мы не говорили о криптографическом и некриптографическом хэшировании, коснулись лишь одного из тысяч способов применения хэш-функций и вообще не обсудили способ работы современных хэш-функций.
Если вам интересна эта тема, то рекомендую изучить следующие материалы:
-
: этот репозиторий — золотой стандарт тестирования качества хэш-функций. Он проводит кучу тестов, выполняя сравнение с большим количеством хэш-функций, и представляет результаты в виде большой таблицы. Может быть сложно понять, для чего нужны все эти тесты, но это самая современная система для тестирования хэш-функций. — это интерактивная статья о структуре данных под названием HyperLogLog. Она используется для эффективного подсчёта уникальных элементов в огромных массивах данных. Для этого она очень хитро применяет хэширование. — это ПО, которому можно передать ожидаемое множество элементов, которые нужно хэшировать, и оно автоматически сгенерирует «идеальную» хэш-функцию.
Благодарности
Благодарю всех, кто читал ранние черновики статьи и давал бесценные отзывы.