Трансформер
Трансформер (англ. transformer) — архитектура глубоких нейронных сетей, основанная на механизме внимания без использования рекуррентных нейронных сетей (сокр. RNN). Самое большое преимущество трансформеров по сравнению с RNN заключается в их высокой эффективности в условиях параллелизации. Впервые модель трансформера была предложена в статье Attention is All You Need [1] от разработчиков Google в 2017 году.
Содержание
Архитектура трансформера
![]()
Устройство трансформера состоит из кодирующего и декодирующего компонентов. На вход принимается некая последовательность, создается ее векторное представление (англ. embedding), прибавляется вектор позиционного кодирования, после чего набор элементов без учета порядка в последовательности поступает в кодирующий компонент (параллельная обработка), а затем декодирующий компонент получает на вход часть этой последовательности и выход кодирующего. В результате получается новая выходная последовательность.
Внутри кодирующего и декодирующего компонента нет рекуррентности. Кодирующий компонент состоит из кодировщиков, которые повторяются несколько раз, аналогично устроен декодирующий компонент. Трансформер — это поставленные друг за другом модели внимания, которые позволяют исходную последовательность векторов перевести в новую последовательность векторов, которые кодируют информацию о контексте каждого элемента. Трансформер-кодировщик переводит исходные векторы в скрытые, которые правильно сохраняют в себе информацию о контексте каждого элемента. Далее трансформер-декодировщик декодирует результат кодировщика в новую последовательность, которая состоит из эмбедингов элементов выходного языка. После по эмбедингам генерируются сами итоговые элементы с помощью вероятностной языковой модели.
Ниже рассмотрим архитектуру кодировщика и декодировщика подробнее.
Архитектура трансформера-кодировщика
![]()
Рассмотрим последовательно шаг за шагом этапы работы кодировщика:
1. На вход поступает последовательность элементов [math]w_i[/math] , по ней создается последовательность эмбедингов, где каждый [math]x_i[/math] это векторное представление элемента [math]w_i[/math] .
2. Добавляются позиционные векторы [math]p_i[/math] : [math]h_i = x_i + p_i[/math] , [math]H = (h_1. h_n)[/math] . Это необходимо для того, чтобы отобразить информацию о позиции элемента в исходной последовательности. Основное свойство позиционного кодирования — чем дальше два вектора будут стоять друг от друга в последовательности, тем больше между ними будет расстояние. Более подробное устройство позиционного кодирования будет рассмотрено ниже.
3. Полученный вектор [math]h_i[/math] подается на вход в блок многомерного самовнимания (англ. multi-headed self-attention). [math]h^j_i = \mathrm
4. Затем необходима конкатенация, чтобы вернуться в исходную размерность: [math] h’_i = M H_j (h^j_i) = [h^1_i. h^J_i] [/math]
5. Добавим сквозные связи (англ. skip connection) — по факту просто добавление из входного вектора к выходному ( [math]h’_i + h_i[/math] ). После делаем нормализацию слоя (англ. layer normalization): [math]h»_i = \mathrm
6. Теперь добавим преобразование, которое будет обучаемым — полносвязную двухслойную нейронную сеть: [math] h»’_i = W_2 \mathrm
7. Повторим пункт 5 еще раз: добавим сквозную связь и нормализацию слоя: [math]z_i = \mathrm
После, в кодирующем компоненте пункты кодировщика 3—7 повторяются еще несколько раз, преобразовывая друг за другом из контекста контекст. Тем самым мы обогащаем модель и увеличиваем в ней количество параметров.
Позиционное кодирование
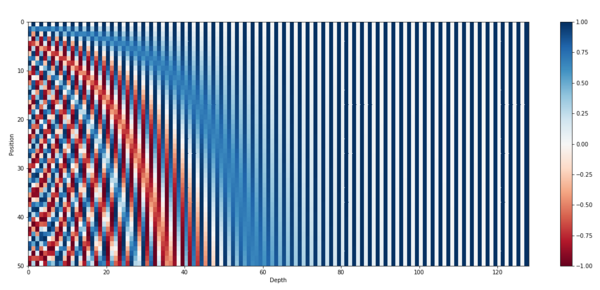
Так как в архитектуре трансформер обработка последовательности заменяется на обработку множества мы теряем информацию о порядке элементов последовательности. Чтобы отобразить информацию о позиции элемента в исходной последовательности мы используем позиционное кодирование.
Позиционное кодирование (англ. positional encoding) — позволяет модели получить информацию о порядке элементов в последовательности путем прибавления специальных меток к вектору входных элементов. Позиции элементов [math]i[/math] кодируются векторами [math]p_i[/math] , [math]i = 1, 2, . n[/math] , так, что чем больше [math]|i — j|[/math] , тем больше [math]||p_i — p_j||[/math] , и [math]n[/math] не ограничено. Пример такого кодирования:
[math] p_ <(i, s)>= \begin
Self-attention
Self-Attention — разновидность механизма внимания, задачей которой является выявление закономерности между входными данными.
Будем для каждого элемента [math]x_i[/math] получать обучаемым преобразованием три вектора:
- Запрос (query) [math]q_i = Q x_i[/math]
- Ключ (key) [math]k_i = K x_i[/math]
- Значение (value) [math]v_i = V x_i[/math]
Векторы [math]q_i[/math] и [math]k_i[/math] будем использовать, чтобы посчитать важность элемента [math]x_j[/math] для элемента [math]x_i[/math] . Чтобы понять, насколько для пересчета вектора элемента [math]x_i[/math] важен элемент [math]x_j[/math] мы берем [math]k_j[/math] (вектор ключа элемента [math]x_j[/math] ) и умножаем на [math]q_i[/math] (вектор запроса элемента [math]x_i[/math] ). Так мы скалярно перемножаем вектор запроса на все векторы ключей, тем самым понимаем, насколько каждый входной элемент нам нужен, чтобы пересчитать вектор элемента [math]x_i[/math] .
Далее считаем важность элемента [math]x_j[/math] для кодирования элемента [math]x_i[/math] : [math]w_
Таким образом, новое представление элемента [math]x_i[/math] считаем как взвешенную сумму векторов значения: [math]z_i = \mathrm
v_p[/math] , где [math]X = (x_1, x_2, . x_n)[/math] — входные векторы. По факту self-attention — это soft-arg-max с температурой [math]\sqrt
Multi-headed self-attention
Multi-headed self-attention — улучшенная модификация self-attention.
Слой внимания снабжается множеством «подпространств представлений» (англ. representation subspaces). Теперь у нас есть не один, а множество наборов матриц запроса/ключа/значения. Каждый из этих наборов создается случайным образом. Далее после обучения каждый набор используется для отображения входящих векторов в разных подпространствах представлений. Также появляется способность модели фокусироваться на разных аспектах входной информации.
То есть параллельно независимо несколько раз делаем attention. Потом результат каждого attention по элементам конкатенируем, затем сжимаем получившуюся матрицу и получаем для каждого элемента свой вектор той же размерности.
[math]с^j = \mathrm
Архитектура трансформера-декодировщика
![]()
На вход декодировщику подается выход кодировщика. Главное отличие архитектуры декодировщика заключается в том, что дополнительно имеется attention к вектору, который получен из последнего блока кодирующего компонента. Компонент декодировщика тоже многослойный и каждому блоку компонента на вход подается вектор именно с последнего блока кодирующего компонента. Разберем по порядку этапы работы декодировщика:
1. Для того, чтобы распараллелить декодировщик и уйти от рекуррентности, но тем не менее генерировать элементы друг за другом, используется прием маскирования данных из будущего. Идея в том, что мы запрещаем себе подглядывать в те элементы, которые еще не сгенерированы с учетом порядка. Когда генерируем элемент под номером [math]t[/math] , имеем право смотреть только первые [math]t-1[/math] элементов: [math]h_t = y_
2. Далее идет этап многомерного самовнимания: линейная нормализация и multi-headed self-attention. Особенность в том, что в attention ключи и значения применяются не ко всем векторам, а только к тем, значения которых уже синтезировали ( [math]H_t[/math] ): [math] h’_t = \mathrm
3. На следующем этапе мы делаем многомерное внимание на кодировку [math]Z[/math] , результат работы компонента кодировщика: [math] h»_t = \mathrm
4. Линейная полносвязная сеть (по аналогии с кодировщиком): [math] y_t = \mathrm
5. В самом конце мы хотим получить вероятностную порождающую модель для элементов. Результат (индекс слова с наибольшей вероятностью): [math]\mathrm
Последний этап выполняется только после того, когда повторились пункты 1—4 для всех декодировщиков. На выходе получаем вероятности классов, по факту для каждой позиции решаем задачу многоклассовой классификации, для того, чтобы понять какие элементы лучше поставить на каждые позиции.
Как работают трансформеры — крутейшие нейросети наших дней
Трансформер — самая модная сегодня нейросетевая архитектура. Она появилась в 2017 и перевернула всю обработку языка машинами. Мы расскажем о структуре трансформера без кода — чтобы потом при взгляде на код вы могли понять, что он делает
![]()
Трансформер придумали ученые из Google Research и Google Brain. Целью исследований была обработка естественного языка, но позже другие авторы адаптировали трансформерную архитектуру под любые последовательности. Сегодня если нейросеть распознает или генерирует текст, музыку или голос, скорее всего, где-то замешан трансформер.
В тексте будут попадаться термины, о которых мы уже писали подробнее. Если нужно, сперва почитайте наши тексты:
Зачем изобретать трансформер?
Эта нейросетевая архитектура избавляется от рекуррентности, то есть от последовательных вычислений. Можно больше не ждать, пока закончит работу прежний шаг программы, а провести подсчеты параллельно, нейросеть станет работать быстрее. Современные видеокарты как раз заточены под параллелизацию.
Еще данные в трансформере идут по укороченному пути по сравнению с рекуррентной архитектурой. Все благодаря механизму внимания — он фокусируется на отдаленных, но важных словах, и отдает их напрямую в обработку. В результате у нейросети улучшается долгосрочная память.
Допустим, надо что-нибудь перевести. Вот схема старого подхода — когда в RNN без внимания слово проходит путь к переводу через всё предложение:
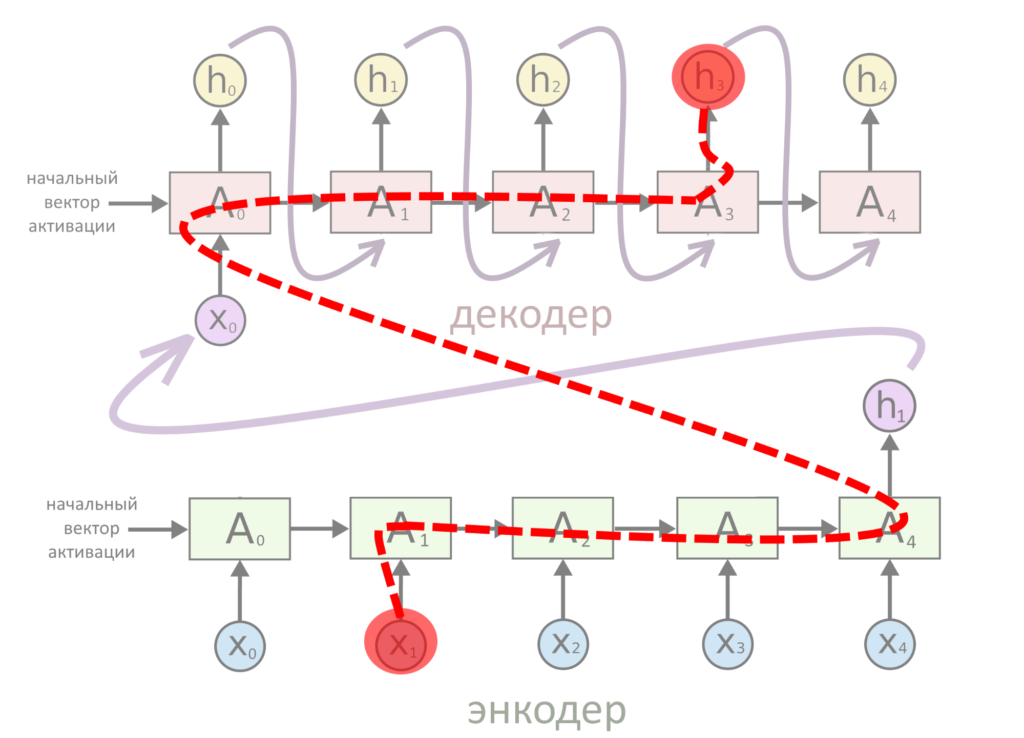 Тут между словами x1 и h3 может быть сколько угодно текста, и через него придется пройти
Тут между словами x1 и h3 может быть сколько угодно текста, и через него придется пройти
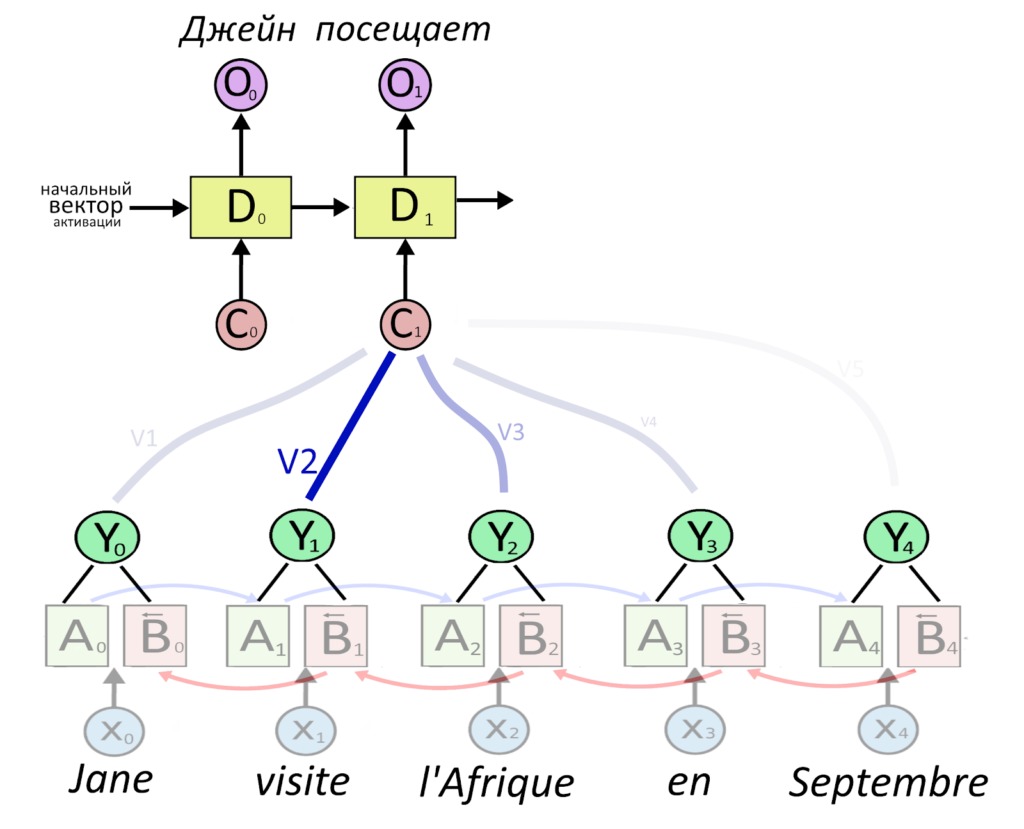 А вот схема нового подхода с использованием механизма внимания трансформеров
А вот схема нового подхода с использованием механизма внимания трансформеров
Тут информация передается с энкодера на декодер напрямую. Механизм внимания смотрит на все слова и говорит, что второе слово оригинала важно для выбора второго слова перевода.
Why didn’t chicken cross the road?
Нейросеть-трансформер может проворачивать хитрые лингвистические трюки! Представим предложение: «Курица не перебежала дорогу, потому что она слишком устала».
Из этого предложения компьютеру (но не читателю!) сложно понять, к какому слову относится «она», ведь информация не закодирована в предложении грамматически, она следует из человеческого знания о мире, дорогах и курицах.
Нейросеть-трансформер справляется с разрешением такой неоднозначности, почему — толком никто не знает, но мы расскажем о технических подробностях того, как она это делает.
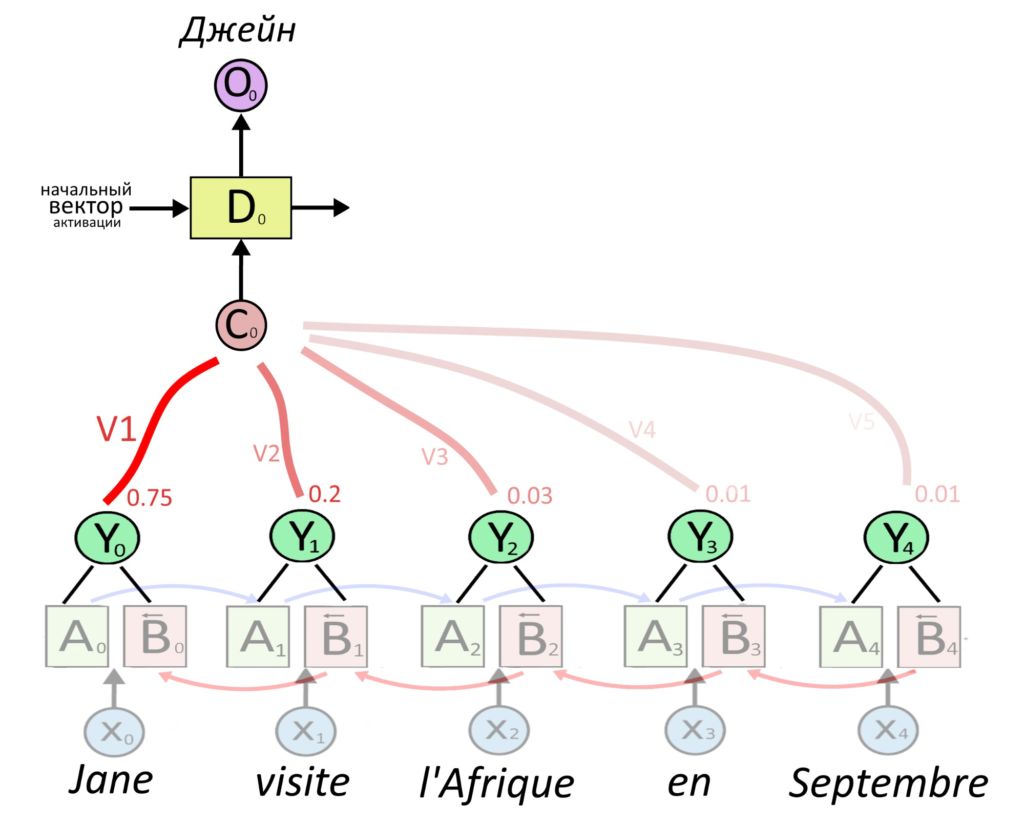
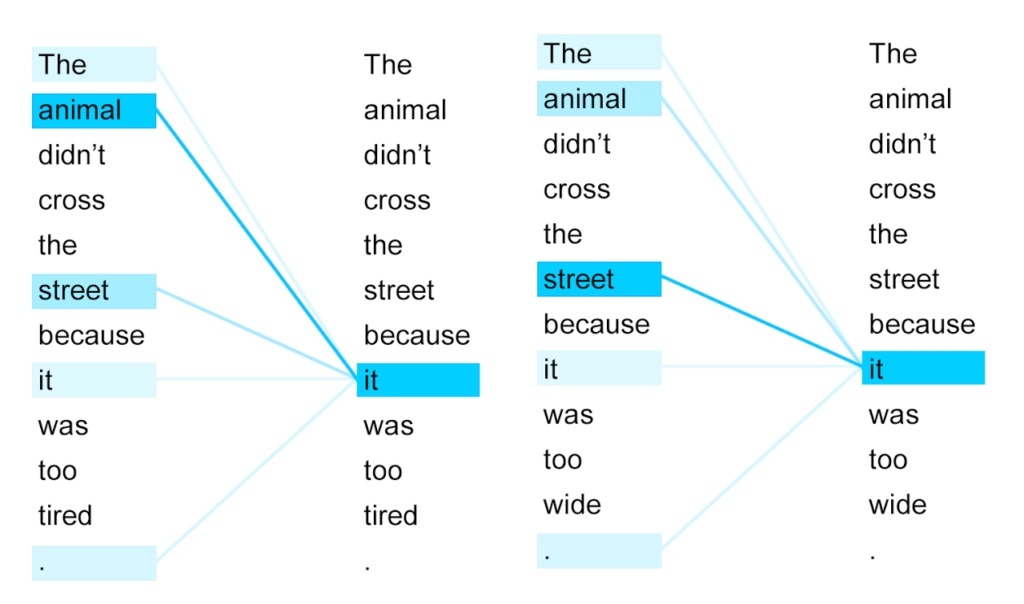 Если в конце стоит “устала”, значит it — про курицу. Если “широкая” — про дорогу. Иллюстрация из статьи в блоге Google AI про трансформеры
Если в конце стоит “устала”, значит it — про курицу. Если “широкая” — про дорогу. Иллюстрация из статьи в блоге Google AI про трансформеры
Так визуализируются веса внимания, которые трансформер присвоил словам при переводе английского предложения на французский. В этой задаче правильно перевести it важно, потому что животное и улица — слова разного рода во французском языке.
Еще трансформер хорош, потому что универсален. Архитектуре неважно, какие вектора перемножать и складывать, лишь бы они были подходящей размерности и лишь бы был датасет, на котором можно обучаться. Поэтому трансформер обрабатывают любые последовательности, которые люди научились кодировать векторами.
Если добавить к трансформеру предобучение (об этой идее расскажем отдельно), получится совсем хорошо — что-нибудь вроде GPT-2 или BERT. Если вы знаете Порфирьевича (умеет дописывать за вас истории) — это как раз нейросеть GPT-2, обученная на текстах на русском.
Нейросеть как большой черный ящик
Черным ящиком иногда можно назвать механизм, который выполняет комплексную работу, если для контекста разговора не важно, как он это делает. На первый взгляд нейросеть-трансформер — это «черный ящик», который, например, неплохо переводит текст на иностранный язык.
 Эта и многие другие иллюстрации взяты из замечательной статьи в блоге Jay Alammar
Эта и многие другие иллюстрации взяты из замечательной статьи в блоге Jay Alammar
Внутри ящика трансформер состоит из двух частей: энкодера и декодера. Энкодер кодирует входную последовательность (например, слов) в вектор (т.е. набор чисел), декодер — декодирует ее в виде новой последовательности (например, слов на другом языке, или ответа на вопрос, который изначально пришел на вход в энкодер — смотря как и для чего обучали нейросеть).
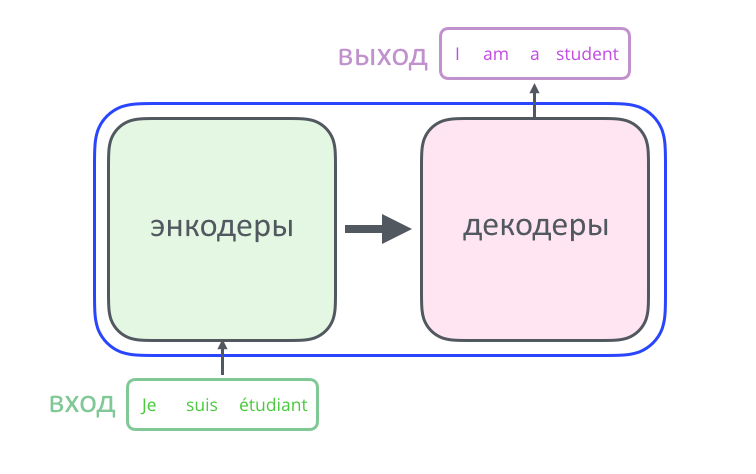
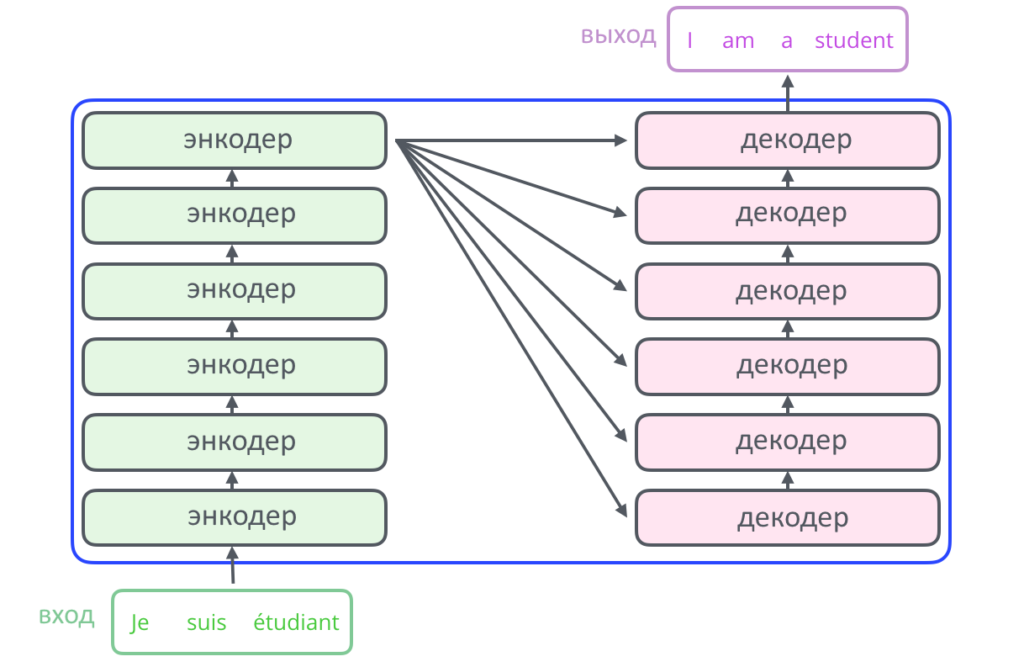
Спустимся на уровень ниже: энкодер и декодер в стандартном трансформере содержат по шесть слоев, то есть наборов математических операций. Эту цифру разработчики подобрали опытным путем, ее можно увеличивать.
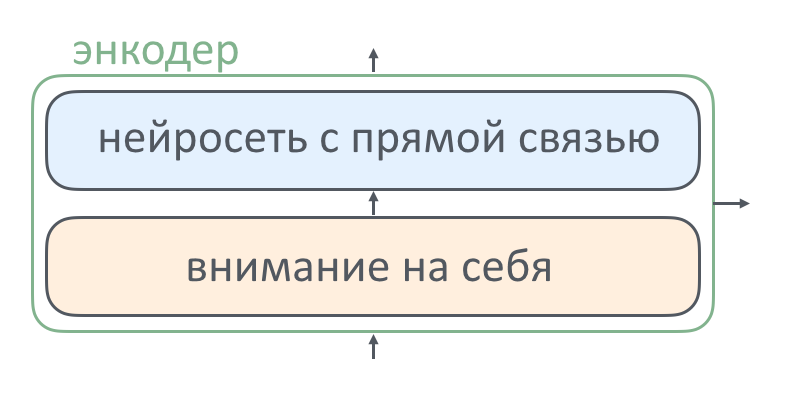
Внутри каждого слоя энкодера есть две составные части: слой внимания и нейросеть с прямой связью. Как работает каждый из элементов и зачем он там нужен, мы расскажем ниже. Декодер в этот текст уже не поместился, про него — в следующей серии.
Внутри каждого слоя энкодера есть две составные части: слой внимания и нейросеть с прямой связью. Как работает каждый из элементов и зачем он там нужен, мы расскажем ниже. Декодер в этот текст уже не поместился, про него — в следующей серии.
Зачем нужен механизм внимания
В тексте про работу механизма внимания мы описали его работу в рекуррентной нейросети. Вектор важного слова умножался на большой «вес», а вектор неважного — на маленький «вес». Вес — это тоже вектор. Взвешенные вектора всех слов складывались и получался вектор контекста, из него делался перевод.
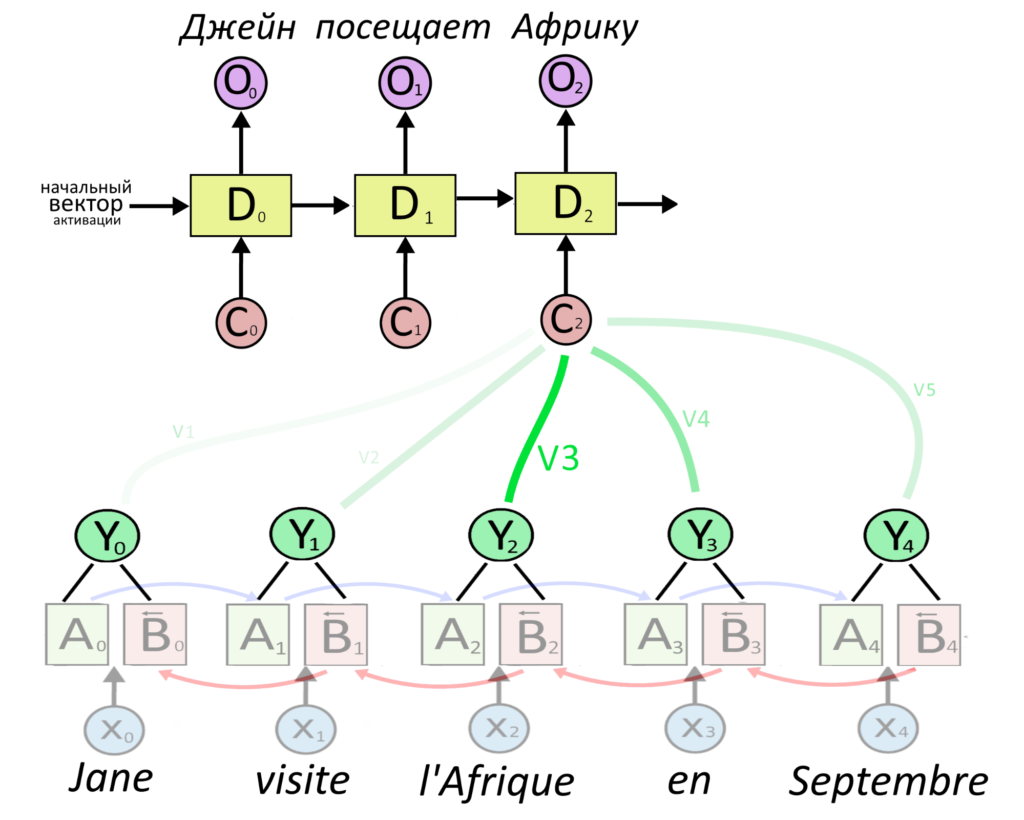 Слово «l’Afrique» важнее всего для перевода «Африки»
Слово «l’Afrique» важнее всего для перевода «Африки»
Чтобы решить, важное слово или нет, активацию энкодера нужно было склеить с прошлой активацией декодера, а потом умножить на матрицу весов внимания: она обучается в процессе тренировки нейросети. В начале обучения в матрице случайные числа.
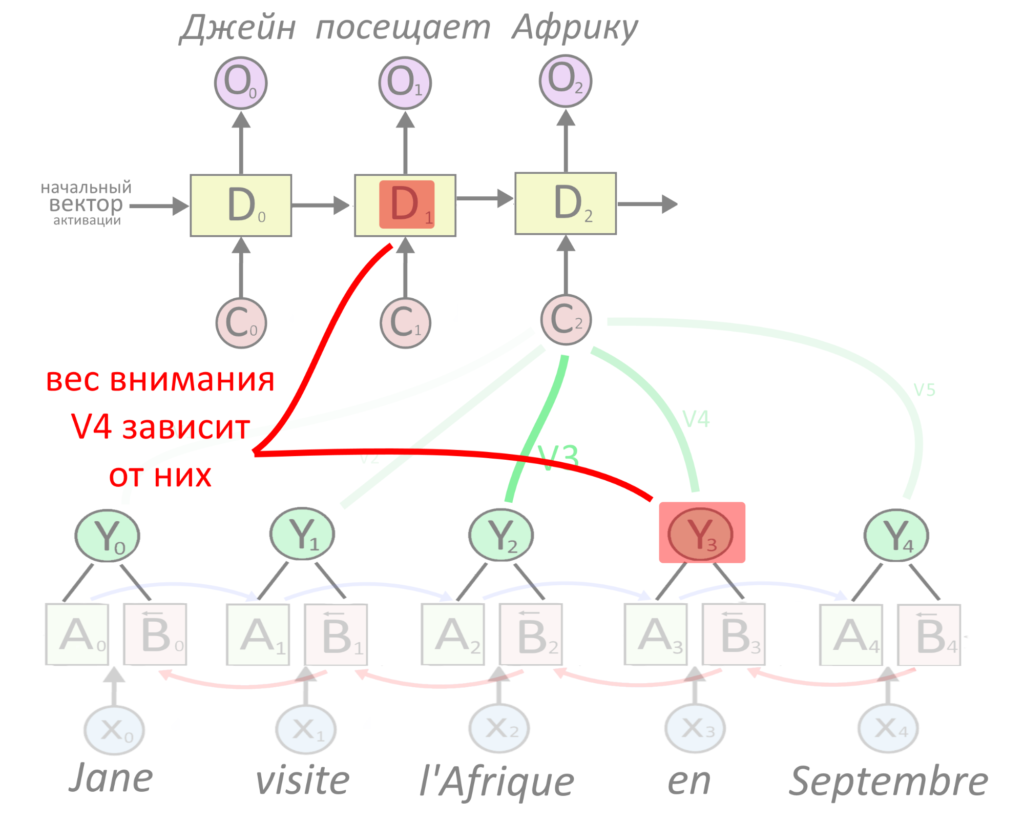 Вот эти подсвеченные значения надо умножить на тренируемую матрицу
Вот эти подсвеченные значения надо умножить на тренируемую матрицу
Произведение проходило через функцию активации Softmax, что делало элементы вектора веса неотрицательными и в сумме дающими единицу. Если вектор слова умножить на вектор после Softmax’a, мы как бы выбираем из семантики слова несколько интересных частей, а остальные умножаем на ноль. Сложим эти смысловые «обрезки» всех слов — получится вектор контекста.
Эти принципы появились в 2014 году в академической статье про нейросетевой машинный перевод. Трансформер появился в 2017, и его авторы придумали свою систему терминов и описание механизма внимания, так что ниже речь пойдет почти о том же самом, но другими словами.
Что поместилось в эту статью
- Расскажем, что такое «внимание на себя» (self-attention) и зачем нужна нейросеть с прямой связью
- Введем новые термины, которые придумали изобретатели трансформера
- Расскажем подробнее о dot product attention, «скалярном внимании», (обычно это название не переводят).
- Расскажем о том, как из «скалярного внимания» сделать «взвешенное скалярное внимание»
- Объясним, зачем одну и ту же операцию «взвешенного скалярного внимания» повторять несколько раз с разными настройками: так получится описание «multi-head attention» — «многоголового внимания». Именно этот механизм задействован в нейросети-трансформере.
Что такое self-attention, внимание на себя
В прошлый раз, когда мы описывали внимание, оно было направлено с одной части нейросети на другую.
 Внимание направлено с декодера на энкодер
Внимание направлено с декодера на энкодер
Декодер переводил фразу и одновременно решал, на какой части оригинала сосредоточиться, чтобы сделать перевод точнее.
В трансформере тоже работает подобное, но не в кодирующей части. Здесь применяется self-attention («внимание на себя»). Внимание энкодера обращено на предыдущий слой энкодера, то есть как бы на себя же, но в прошлом.
На самом первом слое предыдущих нет, поэтому трансформер получает «сырые» вектора слов и концентрирует внимание на некоторых из них. Новый вариант входного предложения, где какие-то слова уже помечены как важные, попадает в нейросеть с прямой связью, зачем она там — в следующем разделе. Оттуда переделанный вектор попадает на следующий слой энкодера, и так повторяется 6 раз.
 Один из слоёв обратил внимание на некоторые слова
Один из слоёв обратил внимание на некоторые слова
Следующий слой снова добавляет веса каким-то словам (но уже другим, потому что у него другие начальные настройки, то есть веса), результат идет дальше.
Смысл повторения — в том, чтобы каждый новый слой энкодера обратил внимание на что-нибудь интересное, но по-своему.
 Два слоя обратили внимание на разные слова
Два слоя обратили внимание на разные слова
Вот иллюстрация: оранжевые связи — работа одного слоя энкодера, зеленые — работа другого. Можно сказать, что один слой понял, что животное — это «оно», а другой — что оно «устало». Вместе получается цельная картинка.
Для чего нужна нейросеть с прямой связью
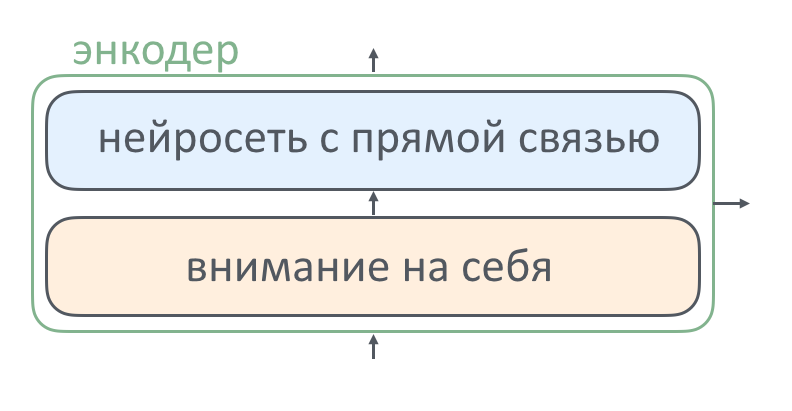
В каждом слое энкодера после слоя внимания идет слой «с прямой связью».
Он нужен, чтобы моделировать более сложные функции. Функции на слое внимания энкодера — линейные. Бессмысленно передавать результат от одной линейной функции к другой по цепочке, добавление новых слоев не усложняет модель и не приближает ее к комплексной реальности. Эта проблема решается, если между линейными слоями внимания добавить слои с нелинейными функциями активации.
В трансформере нейросеть с прямой связью — это матрица весов, на которую надо умножить вектор, нелинейная функция активации, через которую идет результат, и еще одна матрица весов, на которую снова умножается результат. Матрицы весов нужно сначала выучить, в необученной нейросети там случайные числа. После каждого умножения на матрицу добавляется некоторое число, «сдвиг».
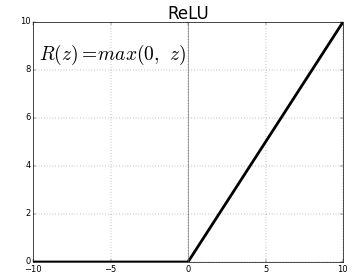
Функция активации может быть разной, но стандартный выбор для трансформера называется ReLU. Эта функция сравнивает элемент вектора с нулем, и если элемент положительный — оставляет, как есть. Если отрицательный — вместо него пишет ноль. График ReLU выглядит вот так:
Нейросеть с прямой связью в трансформере — это умножение на матрицу, «сдвиг», функция ReLU, умножение на вторую матрицу, еще один «сдвиг».
Пока непонятно, как работает механизм внимания, но важно, что после каждого его применения результат проходит через нелинейную функцию. Это происходит несколько раз и усложняет итоговую модель.
Теперь разберемся непосредственно с вниманием.
Новые термины для механизма внимания
В публикации про трансформер авторы вводят три новых понятия: запрос (query), ключ (key) и значение (value).
Есть аналогия, которая поможет лучше понять, зачем нужны «запрос», «ключ» и «значение». Представьте, что вы ищете видео на Ютубе. В базе данных Ютуба хранится видео — это значение, V . Там есть ключи K — это набор тегов к видео. Одному ключу, то есть набору тегов, соответствует одно видео, то есть значение. Есть запрос Q — то, что вы пишете в поисковой строке. Запрос Q сопоставляется со всеми ключами (тегами) K в базе данных, находятся самые близкие к запросу ключи, а пользователь получает значения V (то есть видео), сопоставленные найденным ключам.
Итого: дан запрос Q, ищем самые близкие к нему ключи К и выдаем соответствующие значения V
Скалярное внимание, «dot product attention»
Термин из подзаголовка на русский переводится по-разному и нечасто: в этой статье мы выбрали вариант «механизм внимания на основе скалярного произведения», а для краткости будем писать «скалярное внимание».
В разделе про «self-attention» указано, что «внимание на себя» смотрит на предыдущий слой энкодера. Вот, как именно это происходит.
На каждом слое внимания есть три разных матрицы весов — матрицы веса «запроса», «ключа» и «значения». Они заполняются случайно при первом запуске, и выучиваются во время обучения. На каждом слое они разные: так слои учатся обращать внимание на разные вещи и дополняют друг друга.
Вектор с прошлого слоя энкодера (или вектор самого слова, если слой энкодера — первый) умножается на три этих матрицы и получается вектор «запроса» (Q), вектор «ключа» (K) и вектор «значения» (V).
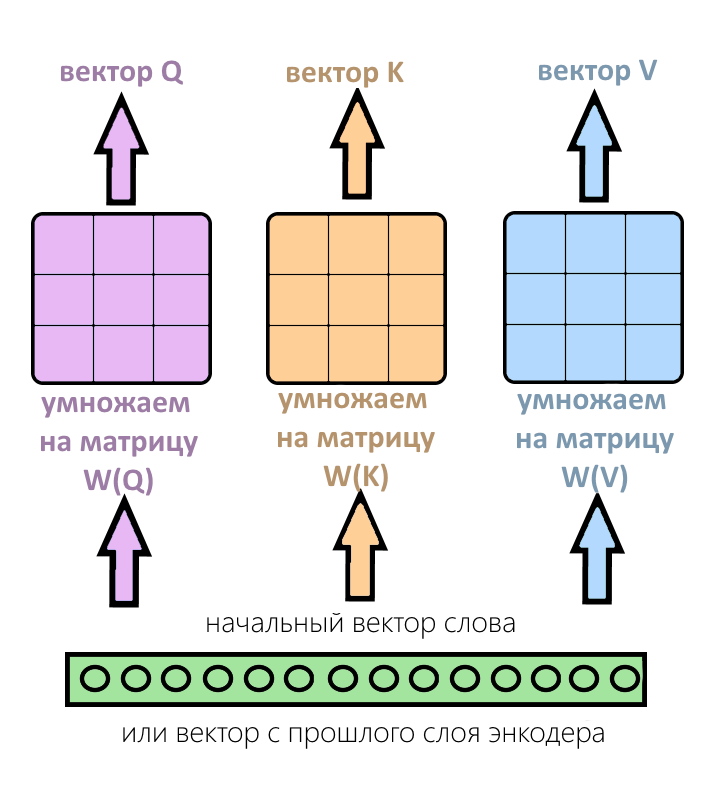
Из входного вектора слова получились три вектора — Q, K, V. Вот, что происходит дальше.
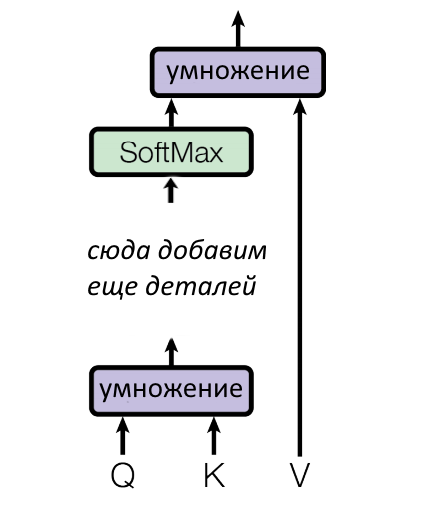
Параллелизация (за которую так любят трансформеры)
В трансформере входные слова обрабатываются параллельно и независимо друг от друга (это одно из важнейших преимуществ по сравнению с рекуррентными нейросетями). Это значит, что у нас только что получилось не одна, а несколько троек Q, K, V — по тройке на каждое входное слово из предложения.
Слова из предложения можно обрабатывать параллельно, если склеить их в матрицы. Один вектор слова — одна строчка. Был вектор слова, стала матрица предложения.
Если надо найти «запрос» Q под каждое входное слово — умножаем матрицу предложения на матрицу весов, и получаем матрицу запросов Q. В ней одна строчка равняется одному запросу, а матрицы умножаются быстрее, чем отдельные вектора по очереди. То же самое работает с матрицами K и V.
Что происходит с матрицами Q и K?
Вспомните аналогию с Ютубом: цель механизма внимания — найти значения V, которые лучше всего подходят под запрос Q конкретного слова.
Для этого матрица с запросами Q умножается на транспонированную матрицу ключей K. Индекс T над K как раз означает транспонирование.
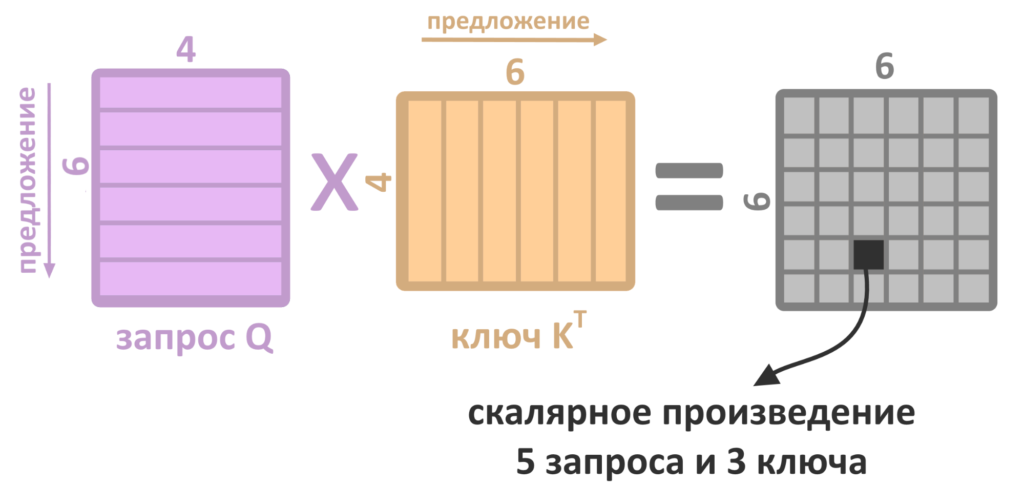 Транспонировать матрицу — значит сделать ряды столбцами, а столбцы — рядами
Транспонировать матрицу — значит сделать ряды столбцами, а столбцы — рядами
Что происходит при произведении матриц?
Каждая строка матрицы Q — «запрос» одного слова, а каждый столбец транспонированной матрицы K — «ключ» одного слова. Скалярное произведение столбца и строки матрицы — число, которое занимает одну ячейку в результирующей матрице.
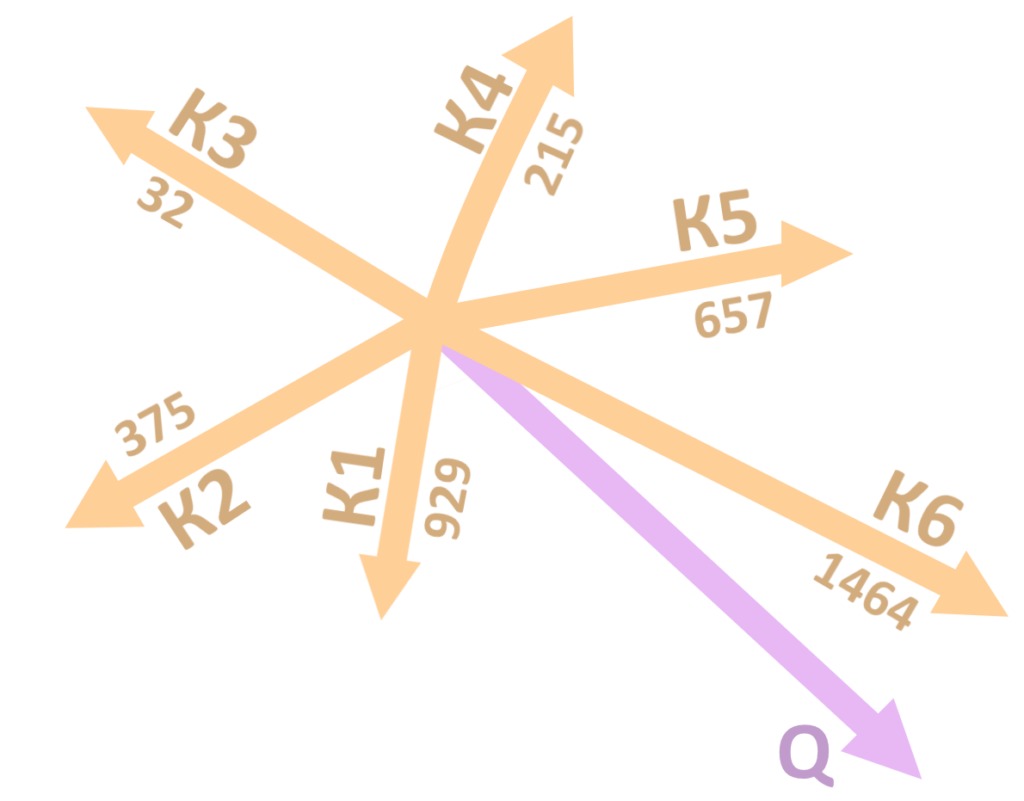
Например, произведение 5 строки Q на 3 столбец K(T) — число, которое займет ячейку в 3 столбце и 5 строке новой матрицы. Строку серой матрицы можно трактовать как набор произведений «запроса» Q одного из слов на каждый из «ключей» K: на первый столбец матрицы К, второй столбец и так далее. Умножать запрос на каждый ключ приходится, чтобы выяснить, какой результат получился самым большим, то есть какой ключ лежит ближе всего к запросу. Но почему большой результат произведения означает, что ключ «близок» запросу?
Вот, в чем дело: большое скалярное произведение получается только у векторов, направленных (примерно) в одну сторону, так работает математика. Запросы и ключи — вектора в многомерном пространстве, почти все они смотрят в разные стороны. Но если направление векторов совпадает хотя бы примерно, скалярное произведение заметно вырастет. Скорее всего, только с одним вектором K скалярное произведение Q получилось большим, а остальные значительно меньше.
Чтобы сильнее подчеркнуть разницу между большим результатом и маленькими, применим Softmax (о том, как работает эта функция, мы рассказывали здесь) к скалярным произведениям данного запроса и всех ключей, то есть к одному ряду серой матрицы.
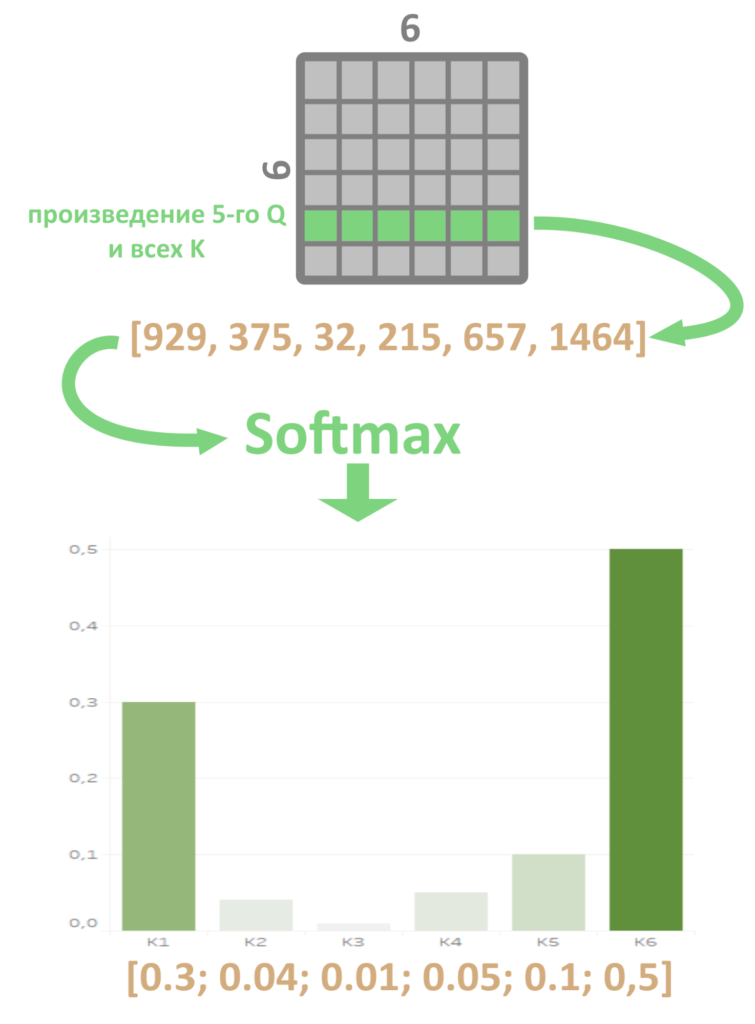
В последовательности было одно большое скалярное произведение и много маленьких. Softmax сделает из такого числового ряда набор неотрицательных чисел, одно из которых (бывшее самое большое) уйдет в отрыв, а все остальные будут плавать возле нуля.
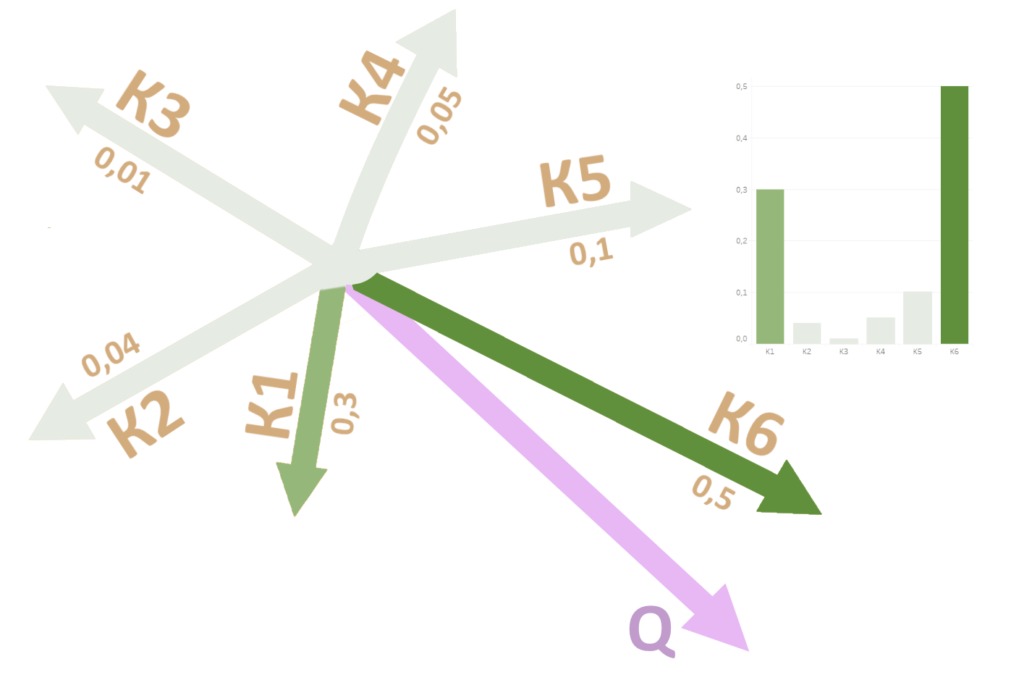
Теперь работу Softmax можно рассматривать как вектор «веса», который выбирает из всех ключей К ближайший к запросу Q. Так компьютер поймет, какие «теги» соответствуют «запросу» В свою очередь выбрать один ключ K — значит выбрать соответствующее ключу значение V. Задача решена, по данному Q нашлось V! Да?
На самом деле не совсем.
Нельзя выбирать единый вектор V из готовых. Их лучше смешать в нужной пропорции, «взвесив» каждое значение V, умножая его на вектор веса из серой матрицы (он получился из произведения Q и К и результата выполнения функции Softmax). Тогда в итоговом векторе внимания Z могут ужиться два или три элемента V, умноженных по степени важности. Вектор внимания Z и есть результат работы скалярного внимания.
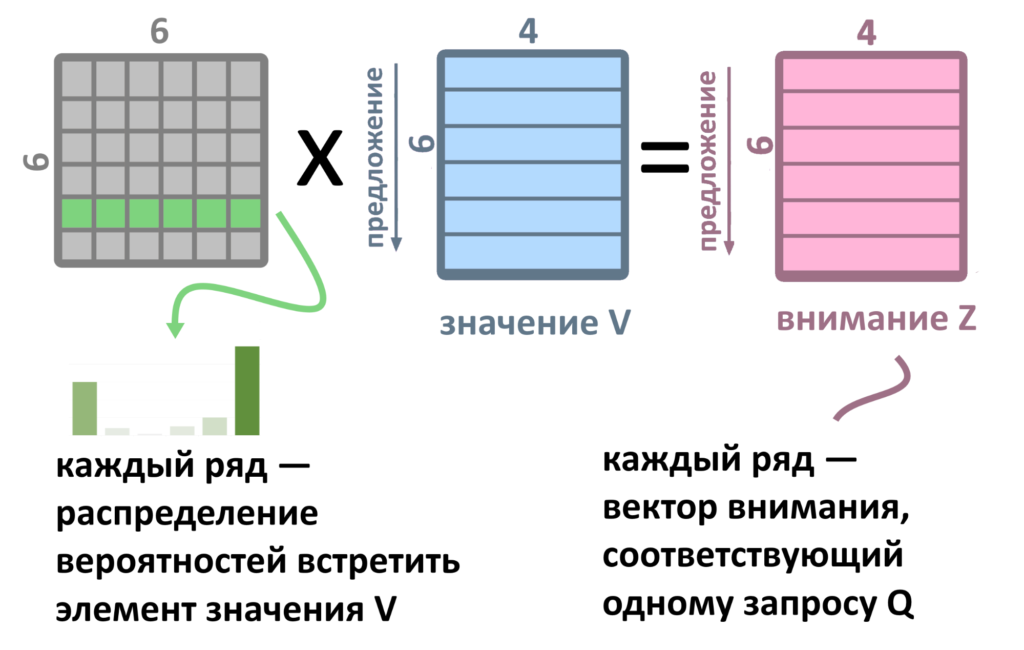
Взвешенное скалярное внимание
Выше мы описали механизм скалярного внимания (dot-product attention). Оно включает в себя перемножение огромной кучи матриц. Чтобы куча матриц перемножалась быстрее, разработчики трансформера добавили операции масштабирования и линейных проекций. Эти уловки позволяют уменьшить размерность матриц.
Чтобы найти ближайшие к запросу ключи, нужно умножить матрицу ключей K на матрицу запросов Q. Этот процесс ускоряется масштабированием (scaling) — делением полученной матрицы (Q*K) на квадратный корень длины одного ключа — d(k).
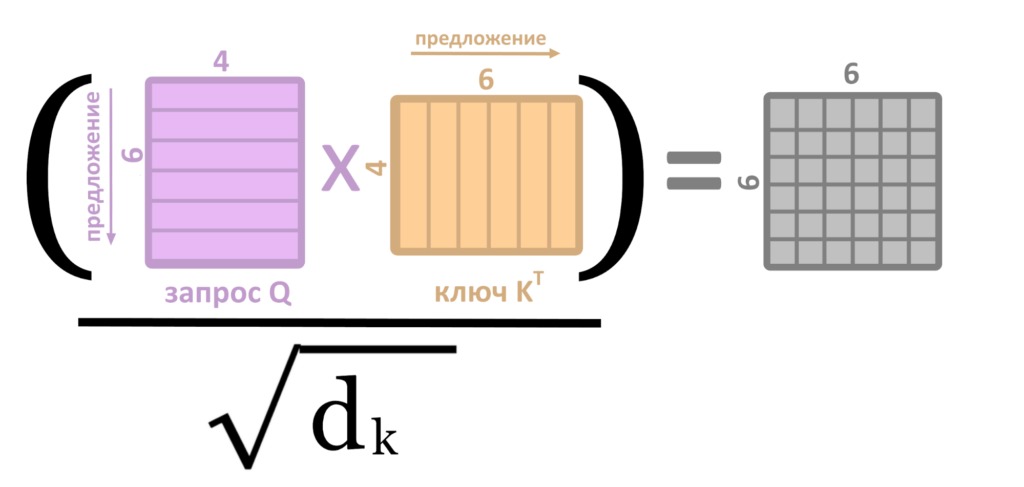 d(k) — длина ключа. В нашем примере d(k) = 4
d(k) — длина ключа. В нашем примере d(k) = 4
Поэтому полная схема работы взвешенного скалярного внимания, приведенная в оригинальной научной работе, выглядит вот так.
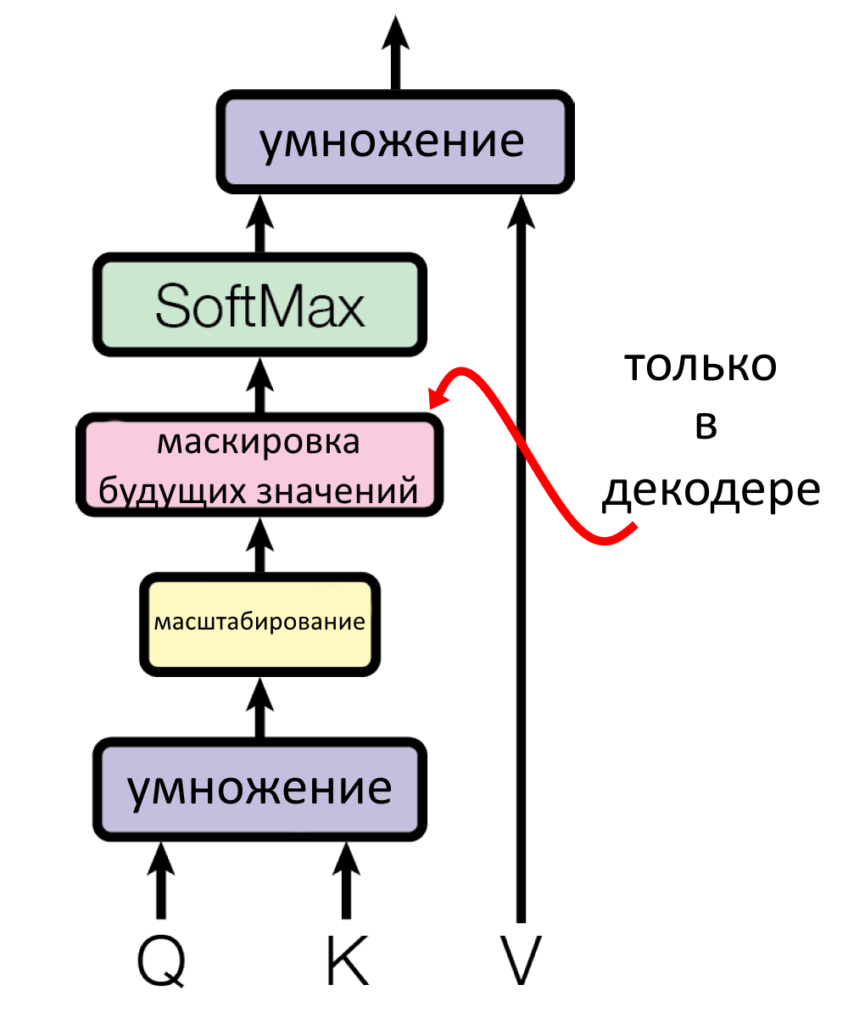
Неразобранным остается только розовый кирпич с маскировкой будущих значений. Он есть только в декодере, который мы пока не рассматривали.
Что такое линейная проекция?
Умножение вектора на матрицу.
Чтобы перенести («спроецировать») начальный вектор слова в пространство ключей, запросов или значений, нужно умножить его на соответствующую матрицу весов (результат умножения матрицы на вектор — вектор). Вектора слов предложения перед умножением объединяются в матрицу (одна строчка — слово), поэтому корректнее будет представить линейную проекцию вот так:
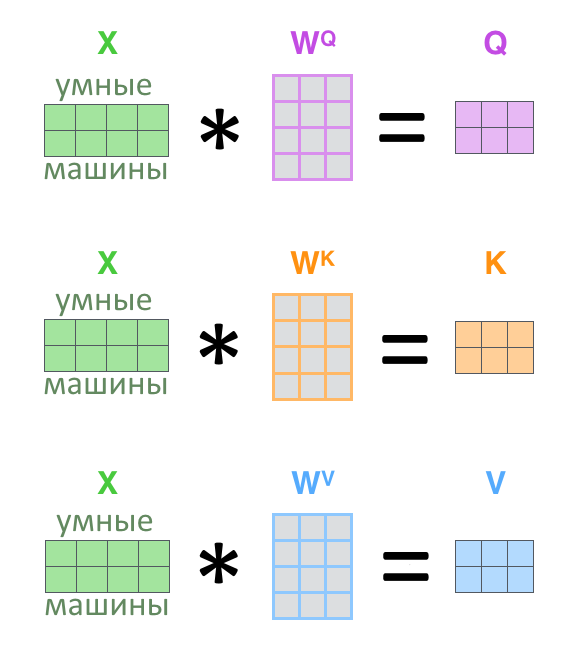 Начальное представление Х здесь больше не вектор, а матрица. Но для простоты можно все равно представлять эту матрицу как набор отдельных строк-векторов
Начальное представление Х здесь больше не вектор, а матрица. Но для простоты можно все равно представлять эту матрицу как набор отдельных строк-векторов
Линейная проекция уменьшает размерность матриц Q, K, V: W(Q), W(K), W(V) нарочно сделаны меньше исходных векторов по размеру.
Три линейных проекции, по одной для Q, K, V, плюс взвешенное скалярное внимание называются «головой внимания» (attention head).
Multi-head attention («многоголовое» внимание)
Разработчики решили, что лучше работать не с одной головой внимания, а с восемью: умножить исходные вектора на восемь разных маленьких матриц весов W(Q), W(K), W(V). Восемь получившихся матриц Q, K, V параллельно проходят через механизм скалярного внимания. В конце их результаты конкатенируются и попадают на слой с нелинейной функцией активации.
Зачем нужно делать несколько «голов»? Рандомизируя начальные веса каждой «головы внимания», можно заставить систему как бы «обратить внимание» на разные аспекты слова и получить восемь его разных «запросов», «ключей» и «значений»: это полезно и повышает качество анализа.
Посмотрите, какое место в multi-head attention занимает взвешенное скалярное внимание.
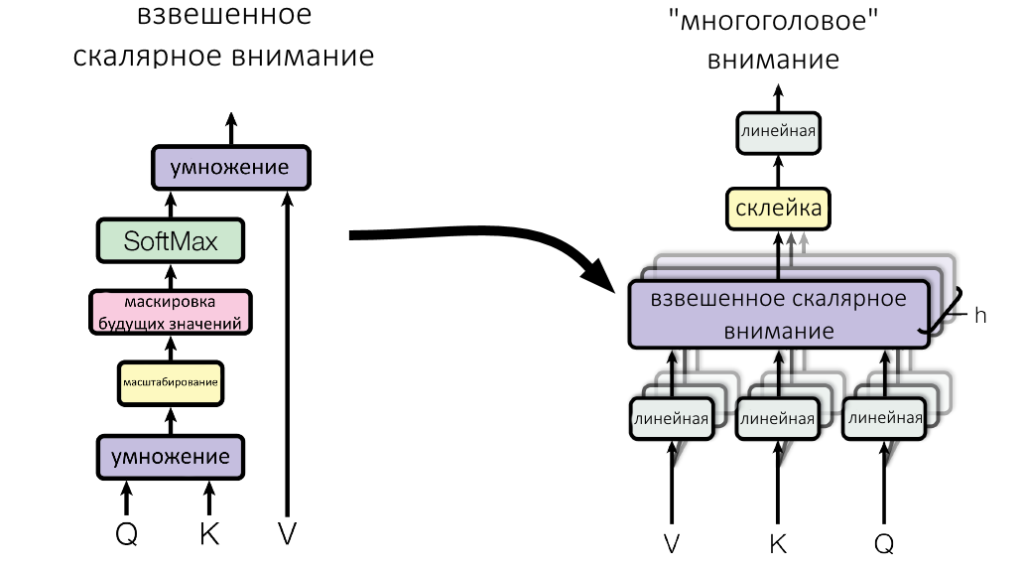 Все, что мы рассмотрели до сих пор, умещается в большом кирпиче цвета баклажана. Исходная матрица векторов слов, либо матрица, поступившая в работу с прошлого слоя, не показана на схеме.
Все, что мы рассмотрели до сих пор, умещается в большом кирпиче цвета баклажана. Исходная матрица векторов слов, либо матрица, поступившая в работу с прошлого слоя, не показана на схеме.
Показанная выше схема окончательно дополняет идею механизма внимания в трансформере.
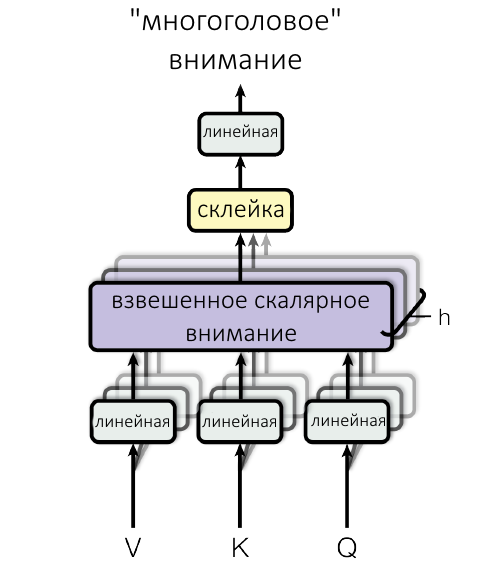
Итак, входные вектора слов, «упакованные» в матрицу, проходят через линейную проекцию h=8 раз (число подобрали эмпирически). Это значит, что исходную матрицу 8 раз умножают на разные маленькие матрицы, получая восемь троек Q, K, V.
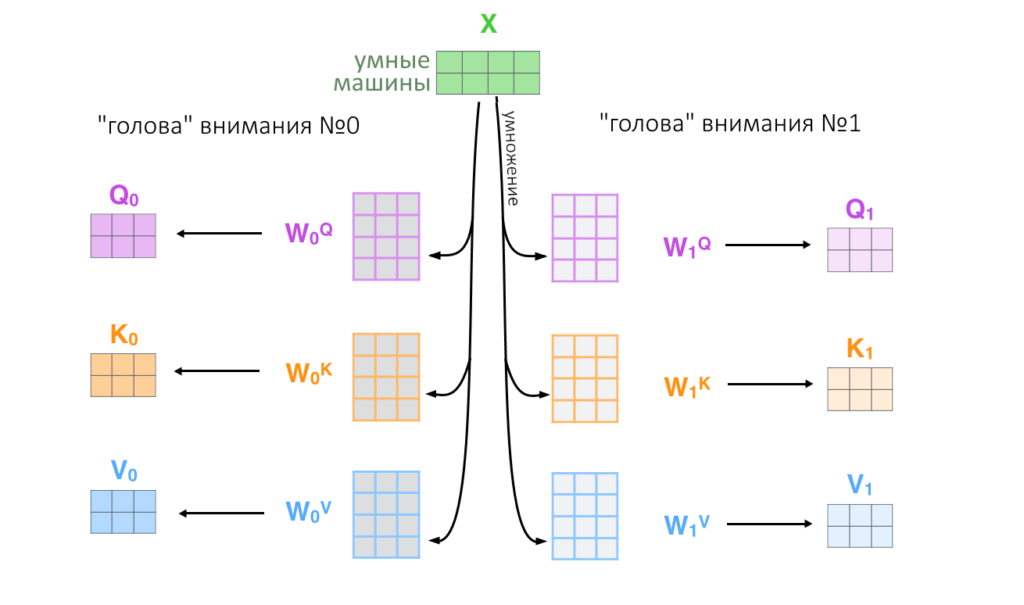 Иллюстрация работы голов внимания
Иллюстрация работы голов внимания
Восемь троек Q, K, V параллельно проходят через механизм взвешенного скалярного внимания (scaled dot product attention), который мы ранее разобрали.

Результат работы всех восьми «голов внимания» (где на выходе каждый раз получается матрица) склеивается («конкатенируется») в одну длинную матрицу и она опять умножается на матрицу весов, которая обучалась вместе с моделью.
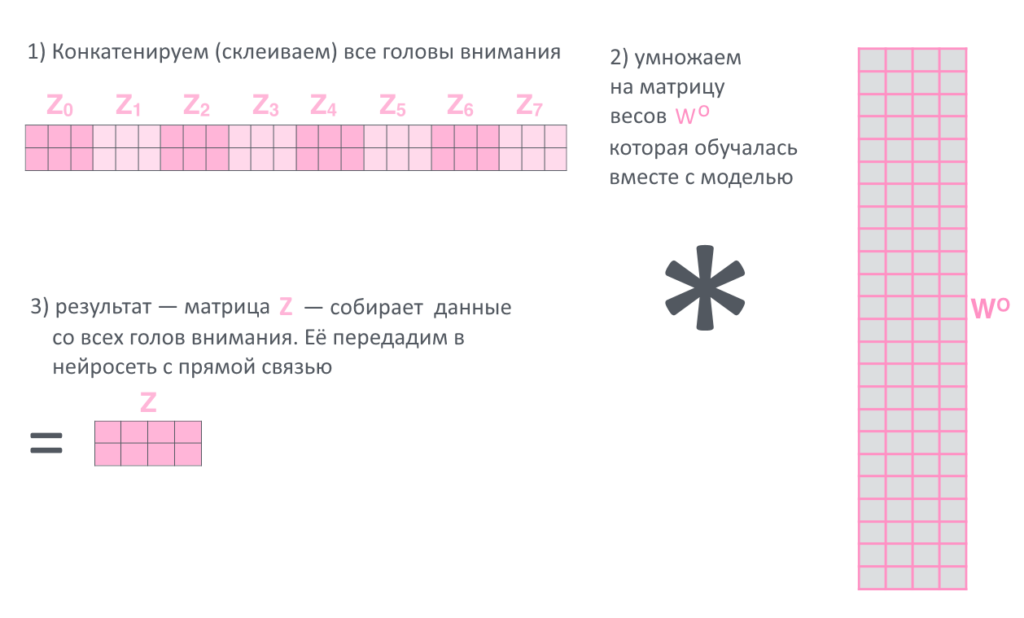
Последняя матрица Z — и есть результат работы большого и сложного слоя «многоголового» внимания энкодера. Этот результат попадет в работу нейросети с прямой связью, а оттуда — на следующий слой энкодера, где снова будет «разбит» на части Q, K и V.
Заключение
Это был механизм внимания кодирующей части трансформера. По сравнению с ней внимание декодера проще разобрать — там почти все то же самое, только некоторые вектора строятся по-другому.
Во второй части этой серии статей мы расскажем о механизме внимания декодера и посмотрим на трансформер с высоты птичьего полета, чтобы понять, как связаны разные его части. Кроме того, расскажем об оставшихся хитрых уловках (там есть еще парочка).
В этом тексте было много технических деталей и умножения матриц. Надеемся, что получилось рассказать о них не слишком сложно — и что принципы работы нейросетей-трансформеров стали вам чуточку понятнее. Оставайтесь с нами!
2020: Экспансия Трансформеров в Компьютерном Зрении. Модель DeiT
![]()
В предыдущие годы трансформеры очень хорошо показали себя в области NLP. Они значительно улучшили качество языковых моделей, а их влияние сегодня сравнимо с тем, что происходило в области обработки изображений, с момента появления на сцене свёрточных нейронных сетей в 2012 году. В конце 2020 года мы наблюдали как CV модели, основанные на трансформерах, входят в топы хорошо-известных бенчмарков, таких как классификация изображений на ImageNet и детекция объектов на датасете COCO.
Продолжая тему предыдущего поста про модели DETR и Sparse R-CNN, основанные на трансформере, в этой статье мы рассмотрим недавно опубликованное совместное исследование Facebook AI и университета Сорбонны “Training data-efficient image transformers & distillation through attention”. В этой статье рассмотрим модель DeiT и поймём, какие научные достижения предвосхитили эту работу.
Архитектура Трансформера
Обзор
Многие улучшения сверточных нейронных сетей для классификации изображений, вдохновлены трансформерами. Например, Squeeze and Excitation, Selective Kernel и Split-Attention Networks используют self-attention mechanism сродни тому, как это происходит в трансформерах.
Представленная в 2017 году статья “Attention Is All You Need” для машинного перевода, сегодня является эталонной моделью для всех задач обработки естественного языка. Такие задачи лежат в основе становящихся всё более распространнёнными домашних помощников и чат-ботов в колл-центрах. Трансформер обладает способностью выучивать зависимости в последовательных данных произвольной длины, значительно не усложняя модель при обработке более длинных последовательностй. Отсюда вытекает его высокая эффективность на задачах sequence to sequence, таких как перевод предложений с одного языка на другой или генерация ответа в зависимости от вопроса.
До трансформеров в этой области применялись рекуррентные нейронные сети. Далее мы рассмотрим, какие недостатки есть у RNN по сравнению с трансформерами. Взглянем на слайд ниже, который взят из лекции Pascal Plupart в университете Waterloo.
Выделяются следующие особенности:
- Чтобы работать с длинными последовательностями и для того, чтобы находить зависимости в таких данных, нужно использовать LSTM или GRU с высокой степенью рекурсии, что на практике означает, что нужно обучать очень глубокую нейронную сеть. С другой стороны, трансфермер может не быть соизмеримо глубоким, чтобы улавливать зависимости в данных на больших расстояниях.
- У трансформеров нет присущей рекуррентным сетям проблемы взрывающихся и затухающих градиентов, поскольку вместо того, чтобы выполнять вычисления линейно (шаг за шагом) для последовательности, трансформер обрабатывает всю последовательность за один проход. А также, потому что трансформер в общем случае менее глубокая сеть, чем RNN.
- Благодаря своей архитектуре, трансформер требует меньше шагов обучения, чем RNN, и отсутствие рекурсии позволяет распараллеливать вычисления. Трансформер может обрабатывать батчи последовательностей.
Структура
Крупным планом трансформер имеет структуру кодирофщика-декодировщика.
Он получает токены на вход энкодера и отдаёт токены из декодера. Обе его половины содержат составные блоки, которые немного отличаются в кодировщике и декодировщике.
Первым элементом блока является self-attention слой, он призван помочь блоку закодировать часть входных данных, учитывая остальные части данных во входе и их позиции. Например, слово внутри одного предложения. Выход из self-attention попадает в feed forward слой, который путём линейных преобразований и функций активации, создает новое представление данных. Блок декодера имеет дополнительный маскирующий слой, который скрывает из видимости self-attention, следующие за сгенерированным токеном элементы последовательности. Декодер принимает не только данные из энкодера, но и также эмбеддинги токенов, которые уже были сгенерированны на предыдущем этапе.
Чтобы лучше понять как устроены трансформеры и какая философия кроется за всеми дизайнерскими решениями в нем, советую посмотреть видео от одного из его авторов и хорошо иллюстрированный пост.
Self-attention
Этот слой очень важен в архитектуре трансформера и модель DeiT также полагается на него.
Крайне упрощенно, можно рассматривать механизм внимания или attention как извлечение значения (value) из некоторой базы, хранящей значения по ключу, т.е. состоящей из пар (key, value), с помощью запроса (query). Возвращаемое значение будет взвешенной суммой значений, где весами выступают меры схожести между данными query и всеми ключами из базы.
Более точно, механизм внимания основан на обучаемой ассоциативной памяти с векторными парами (key, value). Вектор запроса query сопоставляется с набором k ключевых векторов (образующих вместе в матрицу K) с помощью скалярных произведений. Эти произведения, затем масштабируется и нормируются функцией Softmax, чтобы получить k весов. Выходная взвешенная сумма может быть записана в следующем виде:
где Softmax применяется построчно к входной матрице и d — размерность векторов; делим на корень из d в целях нормализации.
Архитектура DeiT
Нейронная сеть, предложенная авторами, является преемником visual transformer (ViT) — модели предложенной в этой статье. Новизна в обозреваемой сегодня статье по существу заключается в следующих трех аспектах:
- Авторы нашли способ обучать visual transformer эффективно без огромного количества размеченных данных, в то время как авторы ViT утверждают обратное.
- В данной статье осуществляются различные эксперименты с тем, как делать дистилляцию на основе знаний из сверточной сети — учителя, поскольку архитектуры сверточных сетей хранят в себе десятилетие тюнинга и оптимизаций.
- И они показывают, что их модель, обученная с дистилляцией, работает лучше в терминах баланса между точностью и количеством обрабатываемых картинок в секунду.
На графике вы можете видеть сравнение по качеству и скорости на ImageNet между вариациями предложенной модели, вариациями ViT и EfficientNet (свёрточная сеть)
Visual Transformer
Visual transformer имеет простую и элегантную архитектуру, которая рассматривает изображение как последовательность из N патчей фиксированного размера 16 на 16 пикселей. Каждый такой патч обрабатывается полносвязным слоем, который принимает на вход вектор размера 3 × 16 × 16 = 768 (где 3 это количество каналов изображения).
Трансформер не знает ничего о порядке этих патчей на картинке, по этой причине к вектору патча добавляется кодирование позиции (positional encoding), оно может быть фиксированным или обучаемым в различных реализациях. Добавление информации о позиции происходит до первого блока кодировщика.
ViT использует токен класса, аналог лейбла при обучении сверточной сети. Такой способ был предложен для классификации текстов в работе BERT.
Авторы DeiT предлагают три версии их модели. Характеристики указаны в таблице ниже:
DeiT-B это ровно такой же ViT, но обученный по-новой схеме. DeiT-Ti и DeiT-S — это просто уменьшенные версии: единственное отличие в них от Deit-B заключается в размере эмбеддингов и количестве голов у multi-head self-attention. Более маленькие модели имеют меньшее число параметров и обрабатывают картинки быстрее. Скорость обработки измерял на картинках размера 224 на 224.
Файн-тюнинг на увеличенном разрешении
Авторы применяют процедуру тюнинга из этой статьи. В ней показано, что желательно использовать меньшее разрешение во время обучения, а файн-тюнинг осуществлять на большем количестве пикселей. Этот подход ускоряет обучение в целом и улучшает точность модели в условиях жесткой аугментации данных, которая имеет место в случае обучения трансформера на относительно небольшом датасете ImageNet1k.
Увеличивая размер входных картинок, авторы сохраняют размер патчей, поэтому длина последовательности из этих патчей изменяется (становится длиннее), чтобы трансформер обработал входную последовательность, она не обязана быть определенной длины, но когда последовательность меняет размер, нужно по-новому кодировать позиции патчей. Чтобы добиться этого, авторы предлагают использовать бикубическую интерполяцию прежних позиций, которая частично сохраняет нормы векторов, которые были до тюнинга сети.
Дистилляция
В дополнение к жесткой аугментации и файн-тюнингу на больших разрешениях, авторы предлагают использовать технику, которая заметно улучшает качество DeiT по сравнению с ViT. Они применяют knowledge distillation из сверточных сетей при обучении DeiT и выдвигают предположение, что так сеть выучивает inductive bias (индуктивное смещение) — феномен описанный в этой статье.
Перед тем, как перейти к сравнительным таблицам, перечислю несколько инсайтов, которые я извлек из статьи:
- Авторы предлагают использовать дистилляционный токен, он имеет такую же природу как и классификационный токен и используется на равне с ним для дачи финального предсказания моделью. Этот токен является эмбеддингом: он подается на вход нейронной сети так же, как и классификационный, взаимодействуя с другими вводными данными (патчами изображения) через self-attention. Разница между токеном класса и дистилляционным токеном заключается в том, что последний получен из предсказания сверточной нейронной сети, а не из ground truth.
- Наряду с токеном дистилляции, авторы пробуют два способа дистилляции с лейблом: soft distillation и hard distillation. Коротко об этих двух подходах: soft distillation стремится минимизировать дивергенцию Кульбака — Лейблера между выходными распределеними учителя и ученика, в то время как hard distillation корректирует лосс ученика таким образом, что ответы учителя трактуются как “true labels”. Авторы показывают, что hard distillation на лейблах плюс токен дистилляции у них работают лучше, чем другие комбинации методов.
Из экспериментов статьи видно, что используя сверточную сеть как учителя, DeiT-B достигает качества выше, чем сам учитель. Например, RegNetY-8.0GF показывает качество на два пункта хуже, чем ее ученик (качество модели в данной статье немногим выше, чем в оригинальной статье, поскольку здесь использовалась другая техника аугментации)
В таблице выше видно, как точность DeiT-B изменяется при переходе от претрейна к файн-тюнингу (3й и 4й столбцы), в зависимости от того, какой алгоритм используется в качестве учителя (варианты учителей расположены по строкам). Точность предобученного учителя указана во втором столбце.
Show me the code!
В этой финальной секции вы можете найти ссылку на код к этой статье. Инженеры из Facebook AI подготовили скрипты с описанием всех трёх DeiT моделей, но к сожалению пока там нельзя найти предлагаемую процедуру дистилляции. Как описано в одном из issue репозитория, этот код должен скоро быть добавлен.
Статья подготовлена и выпущена при участии LabelMe. Мы делаем качественные датасеты в сжатые сроки. Никакой возни с шаблонами. Поручи сбор датасета опытной команде , где есть жесткие критерии качества. Ты можешь сам убедиться в этом, получив бесплатную тестовую разметку уже через 3 часа после оформления заявки на нашем сайте. Или свяжись напрямую с CEO LabelMe Георгием Каспарьянцем: +7 (926)345 53 82.
Transformer — новая архитектура нейросетей для работы с последовательностями
Необходимое предисловие: я решил попробовать современный формат несения света в массы и пробую стримить на YouTube про deep learning.
В частности, в какой-то момент меня попросили рассказать про attention, а для этого нужно рассказать и про машинный перевод, и про sequence to sequence, и про применение к картинкам, итд итп. В итоге получился вот такой стрим на час:
Я так понял по другим постам, что c видео принято постить его транскрипт. Давайте я лучше вместо этого расскажу про то, чего в видео нет — про новую архитектуру нейросетей для работы с последовательностями, основанную на attention. А если нужен будет дополнительный бэкграунд про машинный перевод, текущие подходы, откуда вообще взялся attention, итд итп, вы посмотрите видео, хорошо?
Новая архитектура называется Transformer, была разработана в Гугле, описана в статье Attention Is All You Need (arxiv) и про нее есть пост на Google Research Blog (не очень детальный, зато с картинками).
Сверх-краткое содержание предыдущих серий
Задача машинного перевода в deep learning сводится к работе с последовательностями (как и много других задач): мы тренируем модель, которая может получить на вход предложение как последовательность слов и выдать последовательность слов на другом языке. В текущих подходах внутри модели обычно есть энкодер и декодер — энкодер преобразует слова входного предложения в один или больше векторов в неком пространстве, декодер — генерирует из этих векторов последовательность слов на другом языке.
Стандартные архитектуры для энкодера — RNN или CNN, для декодера — чаще всего RNN. Дальнейшее развитие навернуло на эту схему механизм attention и про это уже лучше посмотреть стрим.
И вот предлагается новая архитектура для решения этой задачи, которая не является ни RNN, ни CNN.
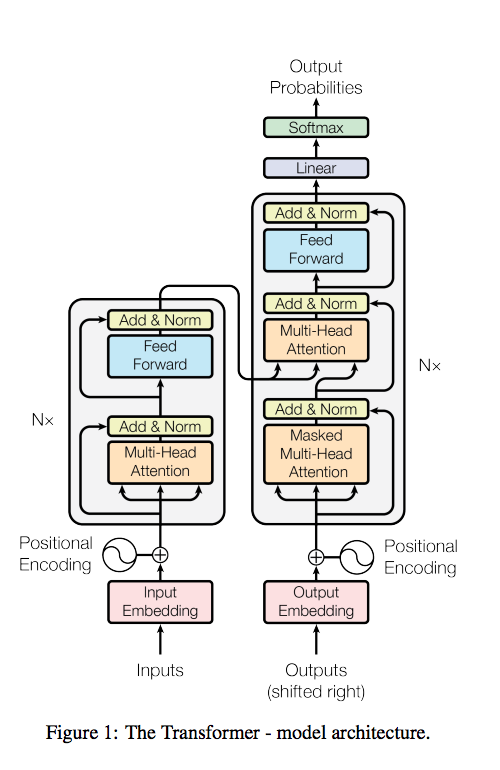
Вот основная картинка. Что в ней что!
Энкодер и Multi-head attention layer
Рассмотрим для начала энкодер, то есть часть сети, которая получает на вход слова и выдает некие эмбеддинги, соответствующие словам, которые будут использоваться декодером.
Вот он конкретно: 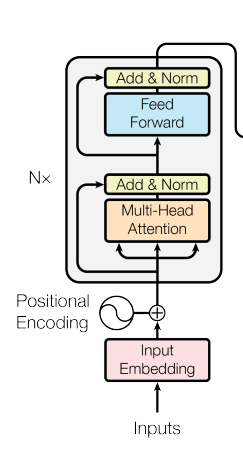
Идея в том, что каждое слово параллельно проходит через слои, изображенные на картинке.
Некоторые из них — это стандартные fully-connected layers, некоторые — shortcut connections как в ResNet (там, где на картинке Add).
Но новая интересная вещь в этих слоях — это Multi-head attention. Это специальный новый слой, который дает возможность каждому входному вектору взаимодействовать с другими словами через attention mechanism, вместо передачи hidden state как в RNN или соседних слов как в CNN.

Ему на вход даются вектора Query, и несколько пар Key и Value (на практике, Key и Value это всегда один и тот же вектор). Каждый из них преобразуется обучаемым линейным преобразованием, а потом вычисляется скалярное произведение Q со всеми K по очереди, прогоняется результат этих скалярных произведений через softmax, и с полученными весами все вектора V суммируются в единый вектор. Эта формулировка attention очень близка к предыдущим работам, где используется attention.
Единственное, что они к нему дополняют — что таких attention’ов параллельно тренируется несколько (их количество на картинке обозначено через h), т.е. несколько линейных преобразований и параллельных скалярных произведений/взвешенных сумм. И потом результат всех этих параллельных attention’ов конкатенируется, еще раз прогоняется через обучаемое линейное преобразование и идет на выход.
Но в целом, каждый такой модуль получает на вход вектор Query и набор векторов для Key и Value, и выдает один вектор того же размера, что и каждый из входов.
Непонятно, что это дает. В стандартном attention «интуиция» ясна — сеть attention пытается выдать соответствие одного слова другому в предложении, если они близки чем-то. И это одна сеть. Здесь тоже самое, но куча сетей параллельно? И делают они тоже самое, а выход конкантенируется? Но в чем тогда смысл, не обучатся ли они в точности одному и тому же?
Нет. Если есть необходимость обращать внимание на несколько аспектов слов, то это дает сети возможность это сделать.
Такой трюк используется довольно часто — оказывается, что тупо разных начальных случайных весов хватает, чтобы толкать разные слои в разные стороны.
Что такое несколько аспектов слов?.
Например, у слова есть фичи про его смысловое значение и про грамматическое.
Хочется получить вектора, соответствующие соседям с точки зрения смысловой составляющей и с грамматической.
Так как на выход такой блок выдает вектор того же размера, что и был на входе, то этот блок можно вставлять в сеть несколько раз, добавляя сети глубину. На практике, они используют комбинацию из Multi-head attention, residual layer и fully-connected layer 6 раз, то это есть это такая достаточно глубокая сеть.
Последнее, что нужно сказать — это что одной из фич каждого слова является positional encoding — т.е. его позиция в предложении. Например, от этого в процессе обработки слова легко «обращать внимание» на соседние слова, если они важны.
Они используют в качестве такой фичи вектор того же размера, что и вектор слова, и который содержит синус и косинус от позиции с разными периодами, чтобы мол было просто обращать внимание по относительным оффсетам выбирая координату с нужным периодом.
Пробовали вместо этого эмбеддинги позиций тоже учить и получилось тоже самое, что с синусами.
Еще у них воткнут LayerNormalization (arxiv). Это процедура нормализации, которая нормализует выходы от всех нейронов в леере внутри каждого сэмпла (в отличие от каждого нейрона отдельно внутри батча, как в Batch Normalization, видимо потому что BN им не нравился).
Попробуем резюмировать работу энкодера по пунктам.
- Делаются эмбеддинги для всех слов предложения (вектора одинаковой размерности). Для примера пусть это будет предложение I am stupid . В эмбеддинг добавляется еще позиция слова в предложении.
- Берется вектор первого слова и вектор второго слова ( I , am ), подаются на однослойную сеть с одним выходом, которая выдает степень их похожести (скалярная величина). Эта скалярная величина умножается на вектор второго слова, получая его некоторую «ослабленную» на величину похожести копию.
- Вместо второго слова подается третье слово и делается тоже самое что в п.2. с той же самой сетью с теми же весами (для векторов I , stupid ).
- Делая тоже самое для всех оставшихся слов предложения получаются их «ослабленные» (взвешенные) копии, которые выражают степень их похожести на первое слово. Далее эти все взвешенные вектора складываются друг с другом, получая один результирующий вектор размерности одного эмбединга:
output=am * weight(I, am) + stupid * weight(I, stupid)
Это механизм «обычного» attention. - Так как оценка похожести слов всего одним способом (по одному критерию) считается недостаточной, тоже самое (п.2-4) повторяется несколько раз с другими весами. Типа одна один attention может определять похожесть слов по смысловой нагрузке, другой по грамматической, остальные еще как-то и т.п.
- На выходе п.5. получается несколько векторов, каждый из которых является взвешенной суммой всех остальных слов предложения относительно их похожести на первое слово ( I ). Конкантенируем этот вректор в один.
- Дальше ставится еще один слой линейного преобразования, уменьшающий размерность результата п.6. до размерности вектора одного эмбединга. Получается некое представление первого слова предложения, составленное из взвешенных векторов всех остальных слов предложения.
Такой же процесс производится для всех других слов в предложении.
В блоге у них про этот процесс визуализируется красивой гифкой — пока смотреть только на часть про encoding:
И в результате для каждого слова получается финальный выход — embedding, на которой будет смотреть декодер.
Переходим к декодеру

Декодер тоже запускается по слову за раз, получает на вход прошлое слово и должен выдать следующее (на первой итерации получает специальный токен <start> ).
В декодере есть два разных типа использования Multi-head attention:
- Первый — это возможность обратиться к векторам прошлых декодированных слов, также как и было в процессе encoding (но можно обращаться не ко всем, а только к уже декодированным).
- Второй — возможность обратиться к выходу энкодера. B этом случае Query — это вектор входа в декодере, а пары Key/Value — это финальные эмбеддинги энкодера, где опять же один и тот же вектор идет и как key, и как value (но линейные преобразования внутри attention module для них разные)
В середине еще просто FC layer, опять те же residual connections и layer normalization.
И все это снова повторяется 6 раз, где выход предыдущего блока идет на вход следующему.
Наконец, в конце сети стоит обычный softmax, который выдает вероятности слов. Сэмплирование из него и есть результат, то есть следующее слово в предложении. Мы его даем на вход следующему запуску декодера и процесс повторяется, пока декодер не выдаст токен <end of sentence> .
Разумеется, это все end-to-end дифференцируемо, как обычно.
Теперь на гифку можно посмотреть целиком.
Во время энкодинга каждый вектор взаимодействует со всеми другими. Во время декодинга каждое следующее слово взаимодействует с предыдущими и с векторами энкодера.
Результаты
И вот это добро прилично улучшает state of the art на machine translation. 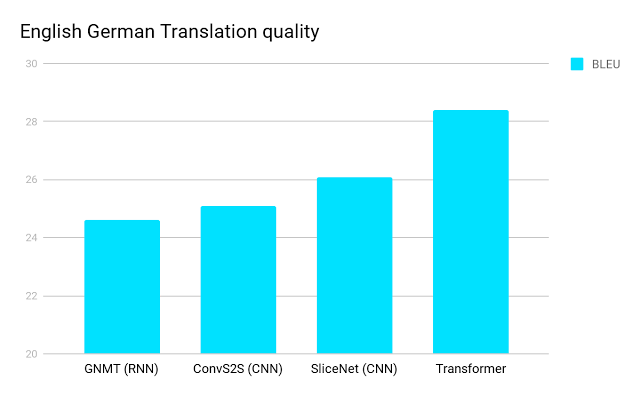
2 пункта BLEU — это достаточно серьезно, тем более, что на этих значениях BLEU все хуже коррелирует с тем, насколько перевод нравится человеку.
В целом, основное нововведение — это использование механизма self-attention чтобы взаимодействовать с другими словами в предложении вместо механизмов RNN или CNN.
Они теоретизируют, что это помогает, потому что сеть может с одинаковой легкостью обратиться к любой информации вне зависимости от длины контекста — обратиться к прошлому слову или к слову за 10 шагов назад одинаково просто.
От этого и проще обучаться, и можно проводить вычисления параллельно, в отличие от RNN, где нужно каждый шаг делать по очереди.
Еще они попробовали ту же архитектуру для Constituency Parsing, то есть грамматического разбора, и тоже все получилось.
Я пока не видел подтверждения, что Transformer уже используется в продакшене Google Translate (хотя надо думать используется), а вот использование в Яндекс.Переводчике было упомянуто в интервью с Антоном Фроловым из Яндекса (на всякий случай, таймстемп 32:40).
Что сказать — молодцы и Гугл, и Яндекс! Очень клево, что появляются новые архитектуры, и что attention — уже не просто стандартная часть для улучшения RNN, а дает возможность по новому взглянуть на проблему. Так глядишь и до памяти как стандартного куска доберемся.