Gentle introduction to GPUs inner workings
This article summarizes some lower level aspect of how GPU executes. Although GPU programming is not that complicated when compared to CPU, it also doesn’t match to what hardware is doing exactly. The reason is that we can’t just program GPU without some API, which is an abstraction over its inner workings. Since few years now, we have modern explicit APIs like DirectX 12 or Vulkan, which shrunken the gap to what is happening with hardware. Yet there still are few low-level bits (pun intended) that are worth explaining.
Note from author: although this post is not about any graphics or compute API, I will use some names that come from Vulkan, mainly because it’s the only modern and multi-platform API out there.
Parts of GPU — quick recap
Let’s list most important parts of GPU at the lowest possible level:
- FP32 units
- FP64 and/or SPU (Specialized Procesing Unit)
- INT32 units
- Registers
- on-chip memory:
- L0$ (rarely in consumer class hardware)
- L1$ used with Shared Memory per compute unit
- L2$ per GPU
All mentioned above are grouped into many hierarchies, of course, that make our graphics cards in the end.
GPU is one big async-await mechanism
At least that’s how you can think about it from CPU point of view. It’s of course much more complicated than anything you can see in CPU side. But still, logic stays. You dispatch some work and await for the results while doing other stuff. You need to ensure some synchronization to whether something is done or not. Fence in Vulkan is the primary mechanism to sync CPU and GPU.
Core in GPU
Well, this might be a surprise for many, but so-called cores in GPUs world are more of a marketing term. Reality is much more complicated. CUDA cores in Nvidia cards or just cores in AMD gpus are very simple units that run float operations specifically. 1 They can’t do any fancy things like CPUs do (e.g.: branch prediction, out-of-order execution, speculative execution/data fetch). At the same time, they can’t run independently. They are tied to a bunch of neigbours (more on that in # Scalar vs Vector paragraph). Let’s call them shading units from now on. Although some can consider them as a very primitive core that can’t run on its own, we should also mention a much bigger hardware construct that encompasses many of such cores: compute unit. This one has a lot more features that usual core of CPU comprise like caches, registers, etc. There are also some GPU specific elements, such a scheduler, dispatcher, ROP, TMUs, interpolators, blenders and many more. While this can resemble CPUs in some ways, at the end of the day neither shading unit nor compute unit should be considered core, as we know from CPU. Shading unit is just too simple, but compute unit is much more.
- Nvidia uses SM (Streaming Multiprocessor)
- AMD uses CU (Compute Unit) and WGP (Workgroup Processor since RDNA architecture)
- Intel uses EU (Execution Unit) and Xe Core (starting from new Arc architecture)
It’s worth mentioning that since Turing architecture there are also 2 new kind of cores: RT Cores and Tensor Cores (AMD has its own RT Cores since RDNA2 architecture too). RT Cores accelerate BVH (Bounding Volume Hierarchy) 2 while Tensor Cores speed up FMA operations on matrices with lower precisions (we can usually neglect 32bit floats for machine learning).
You can use Tensor Cores in Nvidia GPUs directly by VK_NV_cooperative_matrix. It operates on either 32bit or 16bit floats.
- NVML library — Nvidia library shipped with drivers but C header is distributed with CUDA SDK
Concurrency vs Parrallelism
Now that we know what compute unit consists of, let’s talk about 1 misconception that happens within it. I find concurrency and parallelism interchangeable too easily in many articles. In general SPMT (Single Program Multiple Threads) approach doesn’t let us make any use out of this difference — GPU vendors don’t expose what is inside SM/CU (with small exception to shared memory size and workgroup size), especially how many shading units are there. That’s the main reason why using those words interchangeably doesn’t make any difference from shader writer point of view. But let’s shed some light on what is actually happening when dispatching work to GPU. We will use a diagram of Streaming Multiprocessor from Nvidia’s Turing architecture:
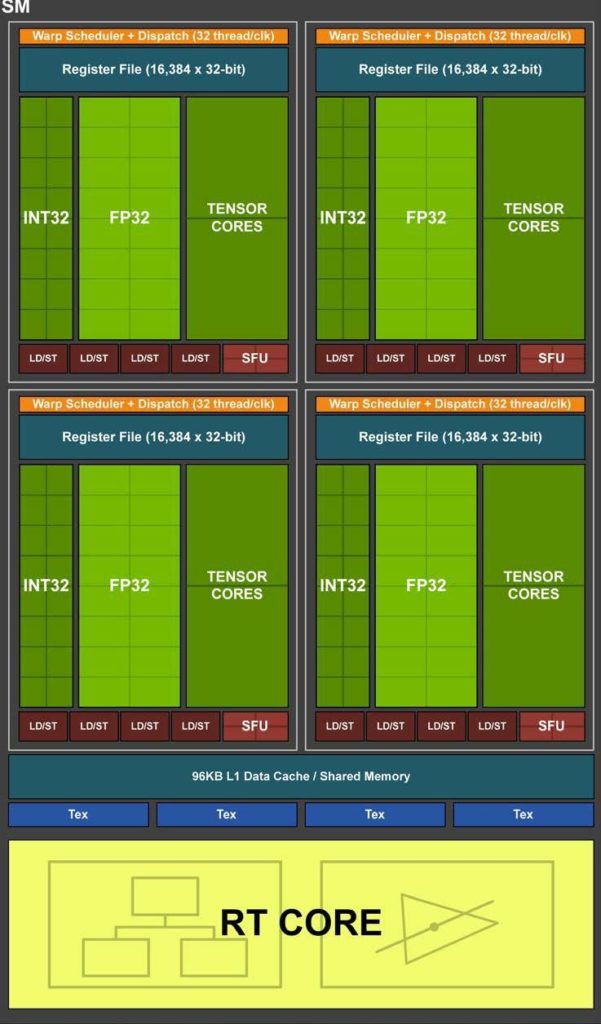
As you can see, each one of such SM has 64 FP32 shading units. At the same time, look at how big registers are. Now let’s use a little contrived example and assume we dispatch work of 4 independent Subgroups (128 threads) containing single precision floating numbers only. First and second Subgroup (64 threads) can execute in parallel because there are enough hardware shading units to cover them. Third and forth will be fetched into register and wait until previous is done/stalled. If stalling is the case, third and forth will be executed concurrently to first and second. It might happen of course that e.g. only 2nd Subgroup will stall, then 1st and 3rd might execute in parallel. This distinction does not give you any advantage when writing code in most cases, but it should be clear now that both — parallel and concurrent — cases happen on GPU and mean different things.
If you are coming from CPU world, then concurrency on GPU is a similar concept to SMT and Hyper Threading but with different scale.
Smallest unit of work
Once we prepare our data, we can dispatch it into Workgroup. Workgroups are construct that encompass at least 1 unit of work (that matches to 1 hardware thread) that is submitted as a one. It can be 1 operation or thousands. But for GPU, it doesn’t matter how much of data we provide because it’s all split into groups that match underlying hardware…
Smallest unit of execution is not smallest unit of work
…and those groups have different names per vendor:
- Warp — on Nvidia
- Wave(fronts) — on AMD
- Wave — when using DX12
- Subgroup — when using Vulkan (since 1.1)
Subgroups length varies per hardware supplier. AMD had 64 floats on Vega cards and now with Navi, it uses 32/64 combination. Nvidia uses 32 floats. Intel, on the other hand, can operate in 8/16/32 configurations. 3 Those Subgroup sizes are crucial to understand the difference: while the smallest unit of work is indeed a 1 thread, our GPU will run at least workgroup size of threads to execute it! It might sound suboptimal to say at least, but given GPUs are made for a huge amount of data, this is actually very fast. All not optimal data combinations that don’t match Subgroup perfectly are mitigated by a mechanism called latency hiding.
- smaller subgroups means smaller divergence cost but also reduced memory coalescence (efficiency)
- bigger subgroups means costly divergence but increase memory coalescence (flexibility)
Register file vs cache
But before we describe what latency hiding is, we need to understand 1 crucial hardware aspect: register size. If there was only 1 fact that I can use to let somebody understand the difference between GPU and CPU it would be this: on GPU register file is bigger than cache! Let’s use an example of RTX 2060 from Nvidia. Per every SM there is a register of size 256KB, meanwhile L1/shared memory per this exact SM is only 96KB.
Latency hiding
Knowing how big are GPU registers, we can now understand how it is that GPUs are so efficient with a truckload of data. Most of the work is executed concurrently. Even if just 1 thread in Subgroup must wait for something (e.g.: memory fetch) then GPU does not wait for it. Whole Subgroup is marked as stalled. Another eligible Subgroup is executed from the pool of Subgroups stored in registers. As soon as the previous one finishes the operation that stalled it, it’s re-run once more to finish the job. And in real case scenarios, it happens with thousands of Subgroups. Ability to switch immediately to another Subgroup if we wait for something (latency) is crucial to GPU. It hides the wait times by rolling another set of eligible Subgroups.
- active Subgroup — one that is being executed
- resident Subgroup/Subgroup in flight — it’s stored in registers
- eligible Subgroup — it’s stored in registers and marked as ready to run or re-run
Occupancy
Short version: ratio of how good we saturate our GPU.
Occupancy is not how good we utilize GPU! It’s how many resident Subgroups are there (opportunities to hide latency). ALUs can be stressed to the max even with low occupancy, though in that case we will lose good utilization fast.
Long version: let’s assume that some compute unit can have 32 resident Subgroups (full capacity of register file). Now let’s dispatch 32 fully independent Subgroups of work to saturate it fully. Given 32 possible Subgroups even if 31 are stalled, we still have opportunity to hide latency by executing 32nd. This is basically it: ratio of how many independent Subgroups you dispatched per all possible Subgroups in-flight.
Now let’s assume you dispatch 8 shaders, each using 128 threads (covers 4 Subgroups in hardware). But this time these shaders need to be treated together (if they would be fully independent, then driver will split those in 4 separate Subgroups effectively creating exactly the same situation as above). In other words, every thread this time needs 4 registers. Our compute unit stays the same, so it still has only 32 possible Subgroups in flight. What happens now is that there are 4 times less possibilities to hide latency (switch to another 4 Subgroups) because every Workgroup is now 4 times bigger. This means our occupancy is only at 25% right now. There is important notion to remember here: increased register usage per Subgroup decreases overall occupancy. Of course, unless you have very well structured data, shaders that need to be dispatched almost never ends with 100% occupancy levels. Taking it to extreme: if you dispatch 1 big shader that fills whole register size of compute unit, then there is nothing to switch when something stalls (no latency hiding possibilities).
Register Pressure and Register Spilling
Let’s take the previous example even further. What if every thread needs even more register space? Every time we increase thread requirements measured in register space needed, we also increase register pressure. Low register pressure is nothing to worry about, we will just decrease occupancy (which is also not bad until there is always work to hide latency). But as soon as we start increasing register usage per thread, we will inevitably hit pressure level that driver might consider spilling. Register spilling is the process of moving data that should normally be stored in registers into L1/L2 cache and/or off-chip memory (device memory in Vulkan). Driver might decide to do so if occupancy is really low to maintain some hiding latency opportunities at the cost of slower memory access.
As a side note: while spilling to on-chip memory may actually increase performance 4 this is less obvious in spilling to off-chip memory.
Scalar vs Vector
One of previous paragraph stated we can’t execute work smaller than workgroup size. There is actually more to that. AMD hardware is a vector in nature. That means it has separate units for vector operations and scalar operations. Nvidia on the other hand is scalar in nature which means Subgroups can handle a mix of other types (mostly combination of F32 and INT32). Wait, so the previous paragraph was a lie and we can actually execute work smaller than Subgroup? Correct answer is: we can’t, but scheduler can. Dividing work that needs to be executed is up to scheduler. It also does not change a fact that scheduler will still take scalars amount of at least Subgroup size, it just won’t use it for anything. In the same scenario, AMD must use whole vector but not needed operations will be zeroed and discarded. 5 Intel takes this solution one step further even, as vector size can really vary!
From our perspective, previous paragraphs still hold. Unless you are doing micro-optimizations of your data layout that is fed to GPU, the difference can be neglected. AMD approach should give really good results if data is well structured. For more random data, Nvidia would probably take a lead.
Using types non native to hardware
We have two cases here:
- Using types bigger that common native size
- Using types smaller than common native size
Most consumer-class GPUs use 32 float units as the most common native size. So what happens if we use double precision float (64 bit)? Unless there are too many of those dispatched at the same time, nothing bad happens other than highest register usage (registers in GPUs use 32bit elements, so 64 floats take 2 of those). Most graphics vendors provide separate F64 units or Special Purpose units to handle more precise operation.
Using smaller than native sizes is more interesting. First, we actually may have hardware that can handle those (at least nowadays). Second lower precision floats are in high demand since few years now. Not only because of machine learning but also for game specific purposes. Turing is very interesting architecture here as it splits GPUs to GTX and RTX variants. The former doesn’t have RT cores and Tensor cores, while the latter has both of those. RTX’s Tensors are special FP16 units that can also handle INT8 or INT4 types. They are specialized in FMA (Fused Multiply and Add) matrix operations. Main purpose for Tensor cores is to use DLSS 6 but I’m blindly guessing here that driver can decide to use them for other operation as well. GTX version of Turing architecture (1660, 1650) has no Tensor cores, instead it has freely available FP16 units! They are no more specialized in matrix ops, but scheduler can use them at whim if needed.
16bit-sized floats are also known as half-floats.
What happens if we use F16 on GPU that doesn’t have hardware equivalent, neither by Tensor core nor separate FP16 units? We still use FP32 units to handle and what’s more important, we would waste register space because no matter the size of our type we still put it in 32bit element. But there is 1 big improvement also: decreased bandwidth.
Branching is bad, right?
You probably heard it many times but the correct answer is: it depends. When somebody is talking about branching in a negative way, he or she means it’s happening within Subgroup. In other words intra-subgroup branching is bad! But this is only half of the story. Imagine you are running Nvidia GPU and dispatching 64 threads of work. If 32 consecutive threads end in 1 path while other 32 end in another, then branching is perfectly fine. In other words inter-subgroup branching is totally fine. But if only one thread will branch within those 32 packed floats, then other will wait for it (marked as inactive) and we end with intra Subgroup branching.
L1 cache vs LDS vs Shared Memory
Depending on nomenclature you can see LDS (Local Data Storage) and Shared Memory — they actually both denotes to exactly same thing. LDS is a name used by AMD while Shared Memory is term coined by Nvidia.
L1$ and LDS/Shared Memory are different things but both occupy same space in hardware. We don’t have any explicit control over L1 cache usage. It’s all managed by the driver. The only thing we can program is Local Data Storage that shares space with L1 cache (with configurable proportions). Once we start using shared memory, we may step into some problems…
Memory Bank conflicts
Shared memory is divided into banks. You can think of banks as orthogonal to your data. How each bank is mapped to memory access depends on a number of banks and size of word. Assuming 32 banks with 4-bytes long word — if you have an array of 64 floats then only 0th and 32nd element will end in bank1, 1st and 33rd will end in bank2, etc. Now if every thread from Subgroup is accessing unique bank, then this is ideal case scenario as we can do it in one load instruction. Bank conflict occurs if 2 or more threads are requesting different data from single memory bank. This means that access to those data cells needs to be serialized, which is just pure evil. In the worst-case scenario, you can end with all threads accessing one memory bank but fetching 32 different values — which effectively means that it could take 32 times more time. 7
Accessing particular value from the same bank by many threads is not a problem. Let’s take it to the extreme: if all threads access 1 value in 1 bank then it’s called broadcasting — under the hood it’s only 1 shared memory read and this value is broadcasted to all threads. If some (but not all) threads access 1 value from a specific bank, then we have multicast.
- Optimal shared memory access:
- Bank conflict:
- Broadcast:
Due to latency hiding and shared memory speed, bank conflicts might actually be irrelevant. Until some Subgroup figures out conflicting access, scheduler can switch to another one.
Bank conflicts may happen only within Subgroups! There is no such thing as bank conflict between Subgroups.
Register Bank conflict may arise as well.
Shader process compilation is similar to… Java
What? Modern APIs like Vulkan and DX12 let us offload shader compilation from running graphics/compute application. We compile GLSL/HLSL into SPIR-V beforehand and keep it as an intermediate representation (bytecode) only to be later consumed by driver. But driver takes it (possibly with last-minute changes — like constant specialization) and compiles it once more to vendor and/or hardware specific code. Logic here is very similar to what happens with managed languages like C# or Java, where we compile our code into IL, which is then compiled/interpreted by CLR or JVM on particular hardware.
Instruction Set Architecture
If you want to go deeper, how does GPU execute instruction sets are really excellent read. There are 2 companies that shares ISAs freely for theirs particular hardware:
Bonus — Linux vendor drivers names
My main OS is Linux for over 6 years now. As always, driver situation can surprise many people coming from Windows so let’s dive in into complicated political situation of Vulkan drivers.
For the Nvidia we have 2 choices:
-
— usable for usual day to day job like office or watching youtube but not gaming or computing, development hindered by some Nvidia decissions
- Nvidia proprietary driver — way to go in most cases, works flawlessy but without code access
-
— open source version — 3D library that provides open source radv driver, most popular choice when it comes to AMD
- AMD Proprietary AMDGPU-PRO
-
— similarly to AMD, driver is open and part of this library
Footnotes
What RT Core does is actually BVH traversal, box intersection test, triangle intersection test and unlike all other execution patterns in GPU, which are SIMD-alike, RT core is MIMD type inside. ↩
Newer architectures — for example Turing — can have separate execution cores for int32 type ↩
This flexibility results in really interesting advantage over AMD and Nvidia ↩
If shared memory/L1 or L2 caches are under-initialized ↩
AMD usually compensates this architectural choice by using bigger registers and caches. ↩
Deep Learning Super Sampling can be misleading. While you can use Tensor Cores for deep learning, what happens during a running game is merely inferencing from already generated data. This data is not computed on our GPU, but rather inside nexus of connected Nvidia beefy accelerators and later stored inside driver blobs. ↩
This situation might be mitigated by having many LD/ST units per scheduler that can dispatch more than 1 instruction per cycle (the more the merrier) ↩
ROPS TMUS: что это и как оно работает?
Rops tmus — это инновационный подход, который помогает улучшить работу бизнеса и достигнуть максимальной эффективности. Данный подход предлагает совместное использование коллективного опыта и сожмения времени путем обмена информацией. Он также позволяет улучшить качество производства и снизить издержки.
Rops tmus подходит для любого типа бизнеса. Он успешно применяется там, где нужно связать воедино всех участников и оптимизировать процессы. Rops tmus также прекрасно подходит для управления командой и увеличения ее производительности. Он позволяет ускорить принятие решений и повысить эффективность действий команды в целом.
В этой статье вы узнаете, что такое Rops tmus и каким образом он может помочь улучшить работу вашего бизнеса. Мы обсудим основные преимущества данного подхода и его применение в разных отраслях.
Что такое Rops tmus и как он функционирует
Rops tmus – это технология, которая может помочь в управлении вашим бизнесом. Оно позволяет собирать информацию о производительности вашей компании и анализировать ее, чтобы вы могли принимать лучшие решения.
Rops tmus использует различные методы сбора данных, включая мониторинг производственных процессов, опросы сотрудников и анализ отзывов клиентов. После сбора данных алгоритм Rops tmus производит анализ и выдает отчеты, которые помогают увидеть точки роста и определить проблемные области.
Например, Rops tmus может помочь в определении того, какие продукты наиболее популярны у ваших клиентов и какие виды рекламы наиболее эффективны. Анализ данных Rops tmus также может показать, где находятся узкие места производственных процессов и какие шаги необходимо предпринять, чтобы улучшить их производительность.
В целом, Rops tmus представляет собой инструмент, который помогает бизнесу повысить свою эффективность и прибыльность путем управления и анализа данных. Он может быть особенно полезен для компаний, которые сталкиваются с конкуренцией на рынке и нуждаются в постоянном улучшении своих процессов.
Что такое Rops tmus
Rops tmus – это инновационная технология, предназначенная для автоматизации и оптимизации бизнес-процессов любого предприятия. Он включает в себя набор инструментов и функций, которые обеспечивают эффективное управление, улучшение производительности и сокращение издержек.
Этот инструмент основан на анализе данных и процессов, которые используются в вашей компании, и позволяет выявить возможности для улучшения работы процессов, принятие правильных решений и увеличение оперативности при выполнении задач.
Rops tmus – это не просто инструмент для управления процессами, он позволяет также проводить анализ эффективности вашего бизнеса в реальном времени. Данные, которые собираются с помощью Rops tmus, помогают выявлять проблемы, разработать более эффективные стратегии и планирование для достижения успеха.
Использование Rops tmus может помочь вам упростить бизнес-процессы, повысить продуктивность и улучшить качество ваших продуктов и услуг. Этот инструмент, безусловно, позволит вашему бизнесу оставаться более конкурентоспособным и успешным на рынке.
Как Rops tmus может помочь вашему бизнесу
Rops tmus — это программное обеспечение, которое позволяет автоматизировать и упростить управление бизнесом. Оно может быть полезно для различных типов компаний, независимо от их размера и отрасли.
С помощью Rops tmus вы можете:
- Оптимизировать бизнес-процессы и сократить время на их выполнение;
- Улучшить качество услуг и товаров, которые вы предлагаете;
- Сократить расходы на персонал и повысить эффективность их работы;
- Получить точную и актуальную информацию о состоянии дел в вашей компании;
- Улучшить взаимодействие с клиентами и увеличить их удовлетворенность;
- Анализировать данные и принимать более обоснованные решения.
Rops tmus также обеспечивает высокий уровень безопасности ваших данных и помогает соблюдать все необходимые законодательные требования.
Rops tmus — это инструмент, который поможет вам эффективно управлять вашим бизнесом и добиваться больших результатов. Если вы ищете способ автоматизировать и оптимизировать управление вашей компанией, то Rops tmus — отличный выбор для вас.
Преимущества использования Rops tmus
Rops tmus – это инструмент, который помогает улучшить работу любого бизнеса. Он предоставляет информацию о том, какие мероприятия необходимо проводить, чтобы повысить эффективность и прибыльность компании.
Среди наиболее значимых преимуществ использования Rops tmus можно выделить следующие:
- Анализ данных. Инструмент предоставляет возможность анализировать большое количество информации о работе бизнеса, что позволяет выявлять проблемные моменты и разрабатывать стратегии их решения.
- Планирование деятельности. Благодаря Rops tmus вы можете создать план деятельности, который поможет определить приоритеты и действия, необходимые для достижения поставленных целей.
- Контроль за исполнением плана. Инструмент позволяет контролировать выполнение задач и достижение целей, что обеспечивает эффективное управление бизнесом.
- Автоматизация бизнес-процессов. Rops tmus предоставляет возможность автоматизировать большое количество рутинных задач, что позволяет сократить затраты на персонал и повысить эффективность работы бизнеса.
Таким образом, использование Rops tmus позволяет оптимизировать работу бизнеса, достигать поставленных целей и увеличивать прибыльность компании.
Увеличение производительности и эффективности
Как владелец бизнеса, вы, вероятно, ищете способы улучшить работу компании. Один из способов — использование программы Rops tmus. Она позволяет автоматизировать задачи, что увеличивает производительность и эффективность вашей компании.
Кроме того, Rops tmus предоставляет информацию о том, как можно улучшить и оптимизировать процессы. Используя эти данные, можно принимать более эффективные решения и повышать эффективность бизнеса.
Использование Rops tmus также позволяет сократить время, затрачиваемое на выполнение повторяющихся задач. Программа может автоматизировать их и освободить время сотрудников для выполнения более важных задач.
В итоге, использование Rops tmus может значительно повысить производительность и эффективность вашей компании, что приведет к увеличению прибыли.
Уменьшение времени, затраченного на рутинные задачи
Хорошо оптимизированный бизнес должен стремиться ускорять и упрощать выполнение рутинных задач, чтобы сотрудники могли сконцентрироваться на более важных заданиях. Система Rops tmus может существенно ускорить и оптимизировать процессы, связанные с выполнением рутинных задач, таких как заполнение отчетов и анализ финансовой отчетности.
Использование системы Rops tmus позволяет высвободить много времени и сократить сроки выполнения рутинных задач. Благодаря автоматизации этих задач, сотрудники могут сосредоточиться на других важных делах, что положительно влияет на производительность бизнеса.
- Система Rops tmus может помочь вам:
- Оптимизировать процессы. Поскольку система Rops tmus позволяет автоматически выполнять многие рутинные задачи, процессы становятся более эффективными и менее трудоемкими. Это может помочь вам сэкономить много времени и ресурсов на выполнении рутинных задач.
- Повысить точность и качество работы. В отличие от людей, система Rops tmus не допускает ошибок при выполнении задач, что может существенно улучшить точность и качество работы. Это позволяет предотвратить потери и убытки, связанные с ошибками, избежать недопонимания и повысить степень уверенности в результатах работы.
- Сэкономить время. Использование системы Rops tmus позволяет моментально выполнять многие рутинные задачи, которые обычно занимают много времени. Это может существенно сэкономить время вашей компании и вовлеченных сотрудников, а также помочь выполнить больше задач в определенный промежуток времени.
Сокращение затрат на персонал
Рops tmus — это инновационный инструмент, способный существенно сократить затраты на персонал в вашем бизнесе. С помощью этой технологии вы сможете автоматизировать повторяющиеся задачи и оптимизировать рабочие процессы.
Это позволит освободить время ваших сотрудников для выполнения более качественной и творческой работы, на которую может быть направлен больший объем средств.
Также использование Rops tmus поможет снизить количество ошибок, связанных с человеческим фактором, что в свою очередь сэкономит время и ресурсы на исправление проблем. Это важно для любого бизнеса, который стремится к эффективности и оптимизации производственных процессов.
Инвестирование в Rops tmus — это шаг в будущее вашего бизнеса и значительное сокращение затрат на персонал, что позволит вывести вашу компанию на новый уровень.
Автоматизация процесса отчетности и анализа
В рамках оптимизации бизнес-процессов, автоматизация процесса отчетности и анализа играет значимую роль. Ранее, для подготовки отчетов и анализа данных необходимо было тратить много времени и ресурсов, что занимало слишком длительный период времени и снижало производительность компании.
Однако, благодаря использованию Rops tmus возможно значительно ускорить этот процесс. Программа позволяет автоматизировать процессы по сбору, анализу и формированию отчетности в режиме реального времени.
Благодаря новому инструменту возможно значительно сократить временные затраты на фиксацию и обработку данных, сократить количество ошибок и сделать этот процесс более удобным и прозрачным. Это приводит к повышению эффективности работы компании в целом и усилению конкурентоспособности на рынке.
Также стоит отметить, что Rops tmus обладает возможностью автоматического формирования оперативной отчетности, причем для любого периода времени, что значительно облегчает контроль и анализ за текущей деятельностью компании.
В заключение стоит сказать, что использование Rops tmus — это необходимый шаг на пути к оптимизации производственным процессам и повышению эффективности работы компании в целом.
Лучшая работа команды благодаря единому рабочему пространству
Современный бизнес требует высокой гибкости и мгновенной реакции на изменяющуюся ситуацию. Работа в команде играет важную роль в достижении успеха, но для этого необходимо, чтобы каждый член команды имел быстрый доступ к релевантной информации и мог обмениваться идеями эффективно.
Для запуска хорошо организованной командной работы необходимо создание единого рабочего пространства (Rops tmus). Он позволяет хранить всю информацию в одном месте и обмениваться ею между участниками команды. Каждый член команды может легко находить необходимую информацию и вносить нужные изменения в единой базе данных.
Единое рабочее пространство делает командную работу проще, развивая культуру совместной работы. Кроме того, оно позволяет отслеживать ход работы по каждому проекту и распределять задачи между членами команды в режиме онлайн, что повышает эффективность работы и уменьшает количество ошибок.
В результате, использование Rops tmus помогает повысить коммуникацию, координацию и планирование в командной работе, а также уменьшить количество ошибок, повышая при этом эффективность ведения бизнеса.
Как начать использовать Rops tmus?
Шаг 1: Зарегистрироваться
Первым шагом для использования Rops tmus является регистрация на платформе. Для этого вам необходимо зайти на официальный сайт Rops tmus и создать аккаунт. Регистрация является бесплатной, все, что вам нужно сделать, это заполнить форму регистрации и подтвердить свой адрес электронной почты.
Шаг 2: Добавить свою компанию
После регистрации на платформе Rops tmus, вы можете добавить свою компанию. Для этого перейдите в раздел «Мои компании» и выберите опцию «Новая компания». Заполните форму, указав название компании, ее описание и другие необходимые данные. Вы также можете добавить логотип и фотографии, чтобы привлечь внимание потенциальных клиентов.
Шаг 3: Создать список услуг
Для того чтобы привлечь больше клиентов, вам необходимо создать список услуг, которые вы предлагаете. Перейдите в раздел «Услуги» и добавьте все услуги, которые ваша компания предоставляет. Убедитесь, что вы дали подробное описание каждой услуги, указали цены и добавили фотографии.
Шаг 4: Привлечь новых клиентов
После того, как вы добавили свою компанию и список услуг, вы можете начать привлекать новых клиентов. Рops tmus предоставляет множество инструментов для продвижения вашей компании, в том числе: размещение объявлений, участие в конкурсах и акциях, участие в сообществах и т.д. Также вы можете подключить свою компанию к социальным сетям и добавить ссылки на свой профиль Rops tmus на свой веб-сайт.
Шаг 5: Следить за отзывами и рейтингом
Чтобы улучшить репутацию вашей компании и увеличить число клиентов, важно следить за отзывами и рейтингом. Вы можете получать отзывы от клиентов, а также оставлять комментарии и отвечать на вопросы. Важно отвечать на отзывы максимально оперативно и вежливо, даже если они отрицательные. Также важно повысить свой рейтинг, чтобы привлечь больше внимания потенциальных клиентов.
Регистрация и настройка учетной записи
Шаг 1. Регистрация
Первым шагом необходимо зарегистрироваться на платформе Rops tmus. Для этого нужно заполнить форму с указанием основных данных о вашем бизнесе, включая название, адрес и контактную информацию.
После отправки заявки на регистрацию, на вашу электронную почту придет письмо с подтверждением и инструкциями по дальнейшим действиям.
Шаг 2. Настройка профиля компании
После успешной регистрации необходимо заполнить информацию о компании в своем профиле Rops tmus. Это поможет сделать вашу компанию более привлекательной для потенциальных клиентов и партнеров.
В настройках профиля вы можете указать описание компании, логотип, контактную информацию, портфолио и другую информацию, которая поможет более полно представить ваш бизнес на платформе.
Шаг 3. Настройка учетной записи
Для удобства работы вам следует настроить параметры вашей учетной записи в Rops tmus. Настройки аккаунта позволяют изменить пароль, установить аккаунт на паузу, изменить адрес электронной почты и многое другое.
Кроме того, вы можете настроить оповещения о новых заказах и сообщениях, чтобы оперативно реагировать на важные события на платформе Rops tmus и не пропустить важные деловые возможности.
Добавление пользователей и настройка доступа
Один из важных аспектов управления Rops tmus — это возможность добавления новых пользователей и настройки их доступа к определенным функциям системы. При этом, каждый пользователь может иметь индивидуальные права доступа в зависимости от его роли в компании.
Для добавления нового пользователя необходимо заполнить определенные поля, такие как имя, фамилия, адрес электронной почты и т.д. После этого нужно указать роль пользователя в системе и установить права доступа, которые он получит после регистрации в системе.
Права доступа могут быть настроены на уровне отдельных разделов системы, что позволяет предоставлять определенные права только для определенных групп пользователей. Таким образом, вы можете настроить доступ для каждого пользователя таким образом, чтобы он имел доступ только к необходимым ему функциям и разделам системы.
- Редактирование профиля пользователей. Пользователь может редактировать свой профиль в системе.
- Доступ к информации о клиентах. Пользователь может просматривать данные о клиентах, но не может изменять или удалять их.
- Создание новых задач. Пользователь может создавать новые задачи и назначать их сотрудникам.
Таким образом, настройка доступа и добавление новых пользователей может значительно улучшить работу вашего бизнеса, увеличив эффективность и улучшив общую координацию работы коллектива.
Импорт данных в Rops tmus
Rops tmus – это инновационное программное обеспечение для управления процессами бизнеса. Для начала работы с этой системой необходимо импортировать данные о компании и ее работниках.
Существует несколько способов импорта данных в Rops tmus:
- Импорт через файл Excel – в этом случае необходимо подготовить таблицу с данными согласно требованиям системы и загрузить ее в программу;
- Импорт через API – вы можете интегрировать свои базы данных с помощью API-интерфейсов, это обеспечит более быстрый и гибкий обмен информации;
- Ручной ввод данных – в некоторых случаях необходимо импортировать данные вручную, например, при первом запуске системы или при небольшом количестве информации.
После импорта данных в Rops tmus вы сможете увидеть их в соответствующих разделах системы. Например, данные о сотрудниках можно увидеть в разделе «Персонал», а финансовые данные – в соответствующем разделе. Каждый раздел имеет свой набор функций, которые позволяют управлять данными и процессами внутри организации.
Импорт данных в Rops tmus – это важный этап на пути к автоматизации бизнес-процессов. Благодаря использованию этой системы вы сможете значительно улучшить работу своей компании и повысить эффективность работы сотрудников.
Улучшение работы бизнеса с помощью настройки рабочих процессов и задач
Настройка процессов
Одним из ключевых аспектов улучшения работы бизнеса является настройка его рабочих процессов. Для этого необходимо внимательно изучить каждый этап процесса и выявить проблемные моменты. Как правило, при анализе процесса можно обнаружить ненужные этапы и повторяющиеся действия, которые занимают много времени и ресурсов.
Путем удаления ненужных этапов, оптимизации процедур и использования автоматизации можно значительно ускорить время выполнения процесса и снизить затраты на его выполнение. Более того, настройка процессов позволяет минимизировать количество ошибок и их последствий, что улучшает качество работы бизнеса.
Задачи и планирование
Второй важный аспект для улучшения работы бизнеса – это планирование и настройка задач. Для этого необходимо определить важность каждой задачи и временные рамки их выполнения.
Эффективное планирование задач позволяет усилить эффективность командной работы, увеличить производительность и уменьшить время выполнения проектов. Более того, планирование задач позволяет более точно определить объем ресурсов, необходимых для успешного выполнения проекта.
- Преимущества настройки рабочих процессов и задач:
- Ускорение времени выполнения процессов
- Снижение затрат на выполнение процесса
- Минимизация количества ошибок и их последствий
- Усиление эффективности командной работы
- Увеличение производительности
- Более точное определение ресурсов, необходимых для проекта
Обучение и поддержка пользователей
Для успешного использования Rops tmus необходимо обучить пользователей этому инструменту. Компания предоставляет обширный набор инструкций и видеоуроков, а также техническую поддержку на всех этапах работы с программой.
Обучение поможет вам использовать Rops tmus наиболее эффективно, что в свою очередь улучшит работу вашего бизнеса. Сотрудники, обученные использованию всех возможностей программы, смогут использовать ее для управления процессами, оценки эффективности работ, анализа отчетности и многих других операций.
Поддержку пользователей предоставляют опытные специалисты, которые всегда готовы помочь в технических вопросах и при возникновении любых проблем. Благодаря этому вы можете быть уверены, что работа с программой будет комфортной и эффективной для всех сотрудников вашей компании.
- Инструкции: Руководства по использованию Rops tmus доступны на сайте компании и содержат подробную информацию о возможностях программы и ее функциональных возможностях.
- Видеоуроки: Видеоматериалы помогут быстрее разобраться с программой и начать использование ее в работе.
- Техническая поддержка: Специалисты компании всегда доступны для консультации и помощи в работе с программой. Вы можете обращаться за помощью круглосуточно.
Отзывы пользователей о Rops tmus
Андрей Иванов, руководитель отдела продаж:
- Раньше у нас были проблемы с организацией рабочего процесса, но благодаря Rops tmus мы смогли значительно улучшить его. Теперь все задачи распределены равномерно между командой и мы всегда знаем, кто отвечает за что.
- Очень удобный интерфейс, который не требует дополнительного обучения, все понятно и интуитивно. Большой плюс этой системы — возможность отслеживать прогресс выполнения задач.
Ольга Петрова, HR-менеджер:
- Rops tmus стала нашим главным инструментом в работе с персоналом. Теперь мы можем контролировать рабочее время сотрудников, начислять зарплату на основе отработанных часов и следить за своевременностью выхода на работу.
- Очень удобная функция напоминаний о важных датах, таких как день рождения сотрудников или срок окончания договора. Использование Rops tmus помогло нам добиться высокой эффективности в работе отдела.
Дмитрий Сидоров, IT-специалист:
- Для нашей IT-команды Rops tmus стал необходимым инструментом в планировании и организации работы. Система позволяет нам удобно контролировать прогресс выполнения задач и объективно оценивать результаты.
- Нам очень понравилась возможность интеграции с другими приложениями и использование API для автоматизации рутинных процессов. Считаю, что Rops tmus — отличное решение для управления проектами в IT-компаниях.
Итог: Rops tmus — это удобная и эффективная система, которая поможет улучшить работу вашего бизнеса и оптимизировать рабочий процесс.
Примеры внедрения Rops tmus в бизнес
Пример 1: Улучшение работы системы управления складом
Компания XYZ, занимающаяся продажей электроники, столкнулась с проблемой недостаточной точности ведения учета товара на складе. После внедрения Rops tmus для системы управления складом, достигнуты следующие результаты:
- Точность учета товара повысилась на 90%
- Время на ручной учет сократилось на 50%
- Количество ошибок при отгрузке товара снизилось на 75%
Пример 2: Автоматизация финансовых процессов
Компания ABC, специализирующаяся на услугах бухгалтерии, столкнулась с проблемой ручного ввода данных в финансовую систему. Внедрение Rops tmus для автоматизации финансовых процессов привело к следующим результатам:
- Точность данных повысилась на 95%
- Время на ручной ввод данных сократилось на 70%
- Количество ошибок при обработке данных снизилось на 80%
Пример 3: Управление производственными процессами
Компания DEF, занимающаяся производством стальных конструкций, столкнулась с проблемой недостаточной эффективности производственных процессов. После внедрения Rops tmus для управления производственными процессами, достигнуты следующие результаты:
- Производительность повысилась на 80%
- Время на ручной контроль снизилось на 60%
- Количество ошибок при производстве снизилось на 70%
Как Rops tmus помог улучшить работу бизнеса
Оптимизация производственных процессов
С помощью Rops tmus вы можете эффективно контролировать производственные процессы и улучшить их качество. Платформа позволяет автоматизировать производственные процессы, уменьшить количество ошибок и снизить затраты на производство продукции. Вы сможете увеличить производительность и прибыльность вашего бизнеса.
Управление поставками и складскими запасами
Rops tmus также помогает в управлении поставками и складскими запасами. Платформа позволяет автоматизировать процессы поставок и отслеживать остатки товаров на складе. Вы сможете контролировать сроки годности и уменьшать количество убыточных запасов.
Анализ и прогнозирование
Rops tmus обеспечивает анализ и прогнозирование результатов деятельности вашего бизнеса. С помощью платформы вы сможете анализировать продажи, операционные затраты и прибыльность. Это позволит вам принимать решения на основе конкретных данных и управлять своим бизнесом более эффективно.
Улучшение взаимодействия с клиентами
С помощью Rops tmus вы сможете улучшить взаимодействие с клиентами. Платформа позволяет отслеживать контакты с клиентами и анализировать обратную связь о продуктах и услугах. Это помогает улучшить качество продукции и услуг, удовлетворить потребности клиентов и повысить лояльность.
Сокращение времени на выполнение задач
Rops tmus позволяет сократить время на выполнение задач и упростить процессы работы. Платформа позволяет автоматизировать многие процессы, такие как планирование задач, управление документами и процессы утверждения. Это позволяет сэкономить время и ресурсы на выполнение задач и быстрее достигать поставленных целей.
Сравнение Rops tmus с другими системами управления проектами
Существует множество систем управления проектами на рынке, которые имеют свои преимущества и недостатки. Однако, Rops tmus — это система, которая выделяется на фоне других своей эффективностью и удобством использования.
Например, Rops tmus позволяет управлять не только проектами, но и задачами, а также имеет встроенные функции контроля времени и расходов. Это позволяет легко отслеживать выполнение задач и контролировать затраты, что облегчает процесс управления проектами.
Кроме того, Rops tmus обеспечивает многоуровневую систему доступа, что позволяет регулировать уровень доступа к информации в зависимости от роли участника проекта. Это позволяет избежать конфиденциальной информации, а также контролировать участие каждого участника проекта в его выполнении.
С другой стороны, многие системы управления проектами имеют проблемы с соединяемостью, что может приводить к потере информации и снижению эффективности. Rops tmus предоставляет мощный интерфейс, который позволяет легко соединять и синхронизировать несколько проектов.
В целом, система Rops tmus является оптимальным выбором для тех, кто ищет систему управления проектами, сочетающую в себе высокую производительность и удобство использования.
Обзор основных конкурентов Rops tmus
1. Salesforce CRM
Один из главных конкурентов Rops tmus в области клиентских отношений. Salesforce CRM предоставляет широкий набор функциональных возможностей, включая управление продажами, маркетингом и службой поддержки клиентов. Однако, по мнению экспертов, пользователи часто жалуются на высокую стоимость этой системы и сложность в использовании ее интерфейса.
2. HubSpot CRM
HubSpot CRM – это еще один значимый конкурент Rops tmus. Она предоставляет средства для управления продажами, маркетингом и службой поддержки клиентов и обеспечивает бесплатный пакет базовых функций. Однако она может быть слабой в области настраиваемости и интеграции с другими системами.
3. Zoho CRM
Zoho CRM является еще одним конкурентом Rops tmus с более доступными ценами и полным набором функций. Она обеспечивает управление продажами, маркетингом, службой поддержки клиентов и управлением проектами. Однако, ее интеграционные возможности могут быть ограничены, особенно в отношении усовершенствованных инструментов аналитики.
4. Microsoft Dynamics 365
Microsoft Dynamics 365 предоставляет своим пользователям широкий набор функций, включая управление продажами, маркетингом, службой поддержки клиентов и управлением проектами. Однако, она может стать дорогой для небольших компаний и иногда кажется сложной для использования.
5. Freshsales CRM
Одна из наиболее доступных CRM-систем на рынке, которая предлагает управление продажами, маркетингом, службой поддержки клиентов и аналитикой. У этой системы есть бесплатный тариф, который может быть особенно полезным для малых бизнесов. Однако, она не может похвастаться такими настраиваемыми возможностями, как Rops tmus, и не всегда способна интегрироваться с другими системами.
Сравнение возможностей и функционала Rops tmus и конкурентов
Rops tmus vs. Trello
Rops tmus: визуальное отображение задач и их степени завершенности, возможность прикреплять файлы, отслеживать отчеты по времени выполнения задач.
Trello: табличный формат, возможность создания карточек, добавления комментариев и проверки списка задач.
Rops tmus vs. Asana
Rops tmus: возможность создания проектов и подпроектов, использование шаблонов задач, настройка отчетов уровня проекта.
Asana: гибкие настройки уведомлений, возможность прокладывания маршрутов исполнения задач.
Rops tmus vs. Jira
Rops tmus: быстрое создание задач с помощью горячих клавиш, интеграция с Slack и Google Drive.
Jira: мощная функциональность при работе с Agile, использование собственных скриптов для настройки.
Rops tmus vs. Monday.com
Rops tmus: возможность ведения двух и более проектов одновременно без переключения, персонализация фильтров для быстрого доступа к задачам.
Monday.com: широкие возможности визуализации данных, интеграция с видеоконференциями.
Вопрос-ответ
Что такое Rops tmus?
Rops tmus — это методика управления проектами, основанная на когнитивно-психологической теории, которая позволяет организовать работу команды таким образом, чтобы достичь максимальной эффективности в кратчайшие сроки.
Каким образом Rops tmus помогает улучшить работу бизнеса?
Rops tmus помогает улучшить работу бизнеса тем, что он позволяет управлять проектами более эффективно. С помощью этой методики можно наладить коллаборацию между участниками команды, распределить задачи таким образом, чтобы каждый член команды смог сделать то, что у него получается лучше всего, и при этом не терять связь между этими задачами.
Какие есть основные принципы методики Rops tmus?
Основными принципами методики Rops tmus являются: когнитивно-психологическая теория, коллаборация, распределение задач, постоянное обновление и улучшение методики, использование современных инструментов для управления проектами и постоянное обучение участников команды.
Какие типичные проблемы бывают у бизнесов, которые могут быть решены с помощью Rops tmus?
Типичными проблемами бывают: неэффективное управление проектами, конфликты внутри команды, недостаточно грамотного распределения задач, излишнее давление на членов команды, нерациональное использование ресурсов бизнеса, низкая производительность, недостаточно эффективные инструменты для управления проектами.
Каким образом можно начать использовать Rops tmus в своем бизнесе?
Для начала использования Rops tmus в своем бизнесе нужно изучить эту методику и ознакомиться с ее основами. Затем нужно внедрить эту методику в работу компании и обучить участников команды таким образом, чтобы все они могли работать эффективно внутри этой системы. Можно также обратиться к специалистам, которые помогут внедрить Rops tmus в бизнес и обучить коллектив внутри компании работать по этой методике.
О понимании технических характеристик видеокарт (или непреходящие ценности и ретро)
Вопрос не такой простой, поскольку тесно связан не только с оценкой технических показателей устройства, но и с вопросом цены. В сети немало материалов на эту тему, но мы все же обратимся к ней еще раз и постараемся рассмотреть ее комплексно, учесть наиболее важные факторы и их взаимосвязи. Чтобы извлечь из этого максимум пользы, возьмем отстраненный от сегодняшнего дня пример, видеокарту, которая уже стала историей: Sapphire Radeon X1650 PRO (RV535). Этот пример уже не может вызывать бурных споров, цена устройства тоже теперь не имеет значения, поэтому на него можно смотреть достаточно трезво.
В этом разговоре мы остановимся на технических характеристиках и их значении. Мы не станем вдаваться в нюансы, а сосредоточимся на главном. При этом постараемся рассмотреть это кратко и просто. Тех, кто помнит и знает, я приглашаю к ностальгической рефлексии и вспомнить, как это было, кто не помнит или не знает — узнать, а всех вместе — задуматься над тем, как же должно все-таки быть. Одновременно не будем забывать о важности вопроса стоимости характеристик видеокарт, который отложим на будущее.
Ответ на поставленный в первом абзаце вопрос определяется множеством характеристик видеокарты. Кроме того, видеокарта — это не вещь в себе, она является частью более сложной системы — компьютера. Несбалансированные характеристики системы (наиболее типичный источник проблем), даже если сами по себе выглядят привлекательно, могут в итоге оказаться дорогим и малополезным решением. Как известно, наиболее удачное приложение для просмотра характеристик видеокарты — GPU-Z. Используем его для наглядности.
На примере этого рисунка разберем по порядку ключевые характеристики выбранной для примера видеокарты. Для ясности будем указывать в скобках конкретные значения параметров, списывая их с рисунка.
ЧАСТЬ 1
GPU Clock (594 MHz) — тактовая частота видеочипа в герцах. Чем выше, тем производительнее карта.
Memory Clock (1391 MHz) — тактовая частота видеопамяти. Влияние на производительность такое же.
Memory Type (GDDR3) — тип видеопамяти. Чем новее тип, тем выше частота памяти.
Memory Size (256 MB) — объем памяти (здесь — в Мбайтах). Чем выше значение, тем больше текстур сможет хранить видеокарта в собственной памяти. Если ширина шины видеокарты шире ширины шины интерфейса подключения видеокарты к компьютеру (см. ниже), то этот параметр оказывает очень заметное влияние на производительность. Если ширина шины видеокарты такая же, или даже ниже, чем у интерфейса подключения, то влияние малозначительно.
Bus Width (128 bit) — ширина внутренней шины видеокарты. Очень важный параметр. Чем шире шина, тем выше ее пропускная способность, т. е. способность пропустить через себя определенное количество информации. Сегодня 128 бит — это минимум, необходимый для комфортной работы с CG и игр. С этой ширины начинаются решения среднего класса. Предпочтительно выбирать карты с внутренней шиной 192, 256 и более бит. Сегодня предлагается очень много видеокарт с шириной шины 64 бита. Часто такие карты снабжаются высокопроизводительными памятью и процессором, большим объемом видеопамяти, но по существу их покупать для задач CG и игр не следует. Это бюджетные решения (хотя порой они могут стоить не так уж и мало), которые являются хорошим вариантом для домашнего и офисного компьютера, нетребовательных игр и просмотра фильмов. В этом плане заметным преимуществом таких устройств может стать их абсолютная бесшумность (зачастую они не снабжаются кулерами).
Bandwidth (44,5 GB/s) — пропускная способность шины видеокарты. Этот параметр производен от частоты и ширины шины видеопамяти: ширина * частота / 8. В нашем случае 128 * 1400 / 8 = 22 400 (т. е. 22,4 GB/s; как видно, GPU-Z тут ошибается, выдавая 44,5 GB/s). Чем больше пропускная способность, тем выше производительность видеокарты.
Bus Interface (AGP 8x @ 8x) — интерфейс подключения видеокарты к материнской плате. Мы говорили о нем выше. Его характеристики следует сравнивать с пропускной способностью шины самой видеокарты. Интерфейс AGP сегодня устарел и в новых машинах его нет. Однако принципы оценки интерфейса для современных карт те же, что и для AGP, и для любых других интерфейсов. Разберем наш пример. AGP 8x работает на частоте 66 MHz и обладает шириной шины 32 бита. Это немного, однако благодаря ряду хитрых решений AGP 3.0 (он же 8x) может передавать 2 GB/s. И все равно этого мало. Как видно, это в 10 раз меньше, чем пропускная способность шины обсуждаемой видеокарты. Значит, в нашем конкретном случае объем видеопамяти является критичным. Это означает, что на данном интерфейсе карта с теми же характеристиками, но бо’льшим объемом видеопамяти будет значительно производительнее.
Почему это так? В общем виде все достаточно просто. Когда видеокарте не хватает собственной памяти для хранения данных (например, текстур), они хранятся в системной памяти. Мы помним, что в нашем примере обмен данными с системной памятью идет на скорости 2 GB/s, а с видеопамятью — на скорости 22,4 GB/s. Поэтому очевидно, что при визуализации конкретной трехмерной сцены обращение не к видео-, а к системной памяти снизит скорость обработки данных примерно в 10 раз. Именно поэтому видеопамяти должно быть достаточно много. Точности ради надо заметить, что такой линейной зависимости вы все равно почти никогда не обнаружите, потому что реальная схема обмена процессора с памятью не так груба, как в нашем рассуждении. Однако общая схема не меняется: а) карта должна получить некоторое количество данных из системной памяти; б) карта должна заполнить этими данными видеопамять; в) видеочип будет работать с этими данными, пока не потребуются другие данные; г) порядок обмена данными с системной памятью и видеопамятью определяет общую скорость и логику обработки данных.
В современных компьютерах используется шина PCI-Express. Пропускная способность ее последней версии достигает 64 GB/s. Видеокарта из нашего примера (а похожих решений для PCI-Express достаточно много, поэтому пример вполне актуален) просто не даст раскрыться возможностям такой шины. Видеокарта будет работать на пределе, а процессор, системная шина и память будут «недозагружены».
Наш вывод на этом этапе: главное — сбалансированность характеристик компонентов системы. Если ее не будет, это означает, что вы переплатили либо за материнскую плату, либо за видеокарту. При этом одно устройство будет «недорабатывать», а другое — работать на пике своих возможностей, что сделает всю систему менее стабильной и сократит срок жизни отдельных ее компонентов. Никто, кроме нас самих (ни тематический форум, но оценки потребителей, ни тесты на производительность, ни критические или хвалебные обзоры, ни авторы компьютерных сборок в магазинах) — никто на самом деле не заинтересован в том, чтобы проследить сбалансированность характеристик нашей машины. Это только наша задача. Что хорошо на одной машине и для одних целей, то вполне может быть плохо в других условиях.
ЧАСТЬ 2
На нашем рисунке осталось еще несколько не рассмотренных позиций.
DirectX Support (9.0c / SM3.0) — пункт показывает, какую версию DirectX и модель шейдеров (SM) поддерживает видеокарта. Чем старше версия, тем лучше. DirectX — это совокупность библиотек обработки мультимедиа контента, в том числе звука и видео. От версии библиотек зависит производительность системы и качество картинки в видеоиграх. Разные версии DirectX сориентированы на разные процессорные архитектуры и операционные системы. Например, 10 версия DirectX практически не работает с WindowsXP, хотя при желании из нее (из DirectX) можно вытащить ряд библиотек, совместимых с XP (народным умельцам это удалось). А вот DirectX 11 ни в каком виде на этой операционной системе работать не будет. В свою очередь, производители программ тоже ориентируются на возможности DirectX со всеми вытекающими из этого последствиями. Шейдерная модель (SM) видеокарты взаимодействует с DirectX. Шейдеры — это специализированные инструкции/процессоры видеокарты, выполняющие те или иные виды обработки картинки.
Shaders (12 Pixel / 5 Vertex) — количество шейдерных процессоров на видеокарте. В современных видеокартах уже не используется специализация шейдеров на пиксельных (Pixel Shader обрабатывает цвет и глубину пикселей) или вершинных (Vertex Shader обрабатывает вершины, т. е. геометрию объектов) выборках, а применяются универсальные процессоры. В ходе обработки данных видеокарта сама определяет, как перераспределить задачи между шейдерными процессорами. В нашем примере мы имеем всего 17 шейдерных процессоров. По современным меркам это, конечно, неприлично мало. У разных производителей шейдерные процессоры устроены по-разному, поэтому сравнивать чипы Ati и Nvidia между собой по количеству шейдеров некорректно. Но в пределах решений одного производителя работает правило — чем больше шейдерных процессоров, тем выше производительность видеокарты.
Pixel Fillrate (2.4 GPixel/s) — количество пикселей, которые может отрендерить видеокарта за 1 секунду. Эта характеристика определяет максимально возможное разрешение, при котором видеокарта теоретически обеспечит необходимую частоту смены кадров. Считается, что для человека комфортной является смена кадров с частотой не менее 24/s. Исходя из этого определим количество пикселей на 1 кадр: 2.4 / 24 = 0.1 GPixel. Это 100 MPixel. Остается узнать, какое это разрешение. К примеру, FullHD это 1920 * 1080 = 2 073 600 Pixel, т. е. округленно это 2 MPixel. Получается, что в «запасе» у нас еще 98 Mpixel на каждый кадр. С этим карта справится без проблем, но только в том случае, если мы не будем иметь в сцене никаких текстур. Однако на каждый объект послойно спроецированы карты текстур, а каждый слой — это плоское изображение определенного разрешения (растр), отвечающее за какой-либо визуальный эффект (основной цвет, неровности, блики и пр.). Таким образом, видеокарта обрабатывает геометрию объектов (по вершинам) и информацию о цвете и глубине пикселей, получаемую из различных карт текстур, для попиксельной отрисовки и раскраски объектов сцены. Поэтому надо различать пиксели как часть результирующего растра (кадра) и пиксели как составные элементы текстур объектов (тексели).
(Между прочим, не будем забывать также, что комфортность восприятия частоты смены кадров зависит от выводящего картинку устройства. Для старых ламповых мониторов нормальной считалась частота развертки в районе 80 — 100 Гц. В современных жидкокристаллических мониторах в качестве стандарта используется частота 60 Гц. Поскольку частота развертки — это количество обновлений экрана в секунду, очевидно, что наилучшее восприятие движущейся картинки будет обеспечено, если частота смены кадров кратна частоте развертки. Например, для частоты 60 кадров наибольший комфорт будет достигнут при частоте 30 и 60 кадров в секунду. Частота в 15 кадров тоже кратна 60, но она заметно ниже комфортных для глаза 24 кадров в секунду. Частота выше 60 кадров не имеет смысла, если монитор не способен ее поддерживать. Более того, любой выход за пределы кратности будет неизбежно приводить к дефектам изображения, так как какие-то кадры будут «выпадать» и не выводиться монитором. Поэтому наилучшим выходом является принудительный рендеринг с жестко заданной частотой, который в настройках видеокарты получил название «вертикальная синхронизация». Существуют и некоторые другие нюансы, связанные с технологией обновления жидкокристаллического экрана, которые снижают комфорт от просмотра даже тогда, когда видеокарта уверенно «держит планку» в 60 кадров, заведомо превышающую комфортные для глаза 24 кадра в секунду. Выражается это в том, что обновление экрана происходит не мгновенно, и предыдущий кадр как бы растворяется в последующем. При ближайшем просмотре глаз это фиксирует и воспринимает как размытость кадров. Поэтому для игровых мониторов стандарт частоты развертки увеличивается, поэтому и VR требует как минимум стабильных 90 кадров в секунду. Ведь матрица в шлеме находится очень близко от глаз и эффекты размытия чрезвычайно заметны и даже способны приводить к нежелательным последствиям, таким как головокружение, тошнота и пр.)
Вернемся к пикселям и текселям.
Texture Fillrate (2.4 GTexel/s) — количество текселей, обрабатываемых картой за 1 секунду. Надо учитывать, что количество текселей отнюдь не равно количеству пикселей на экране. Разберем простой пример. Допустим, что мы видим кадр в разрешении FullHD, ПОЛОВИНУ которого занимает стена. При этом положим, что текстура стены тоже сделана в разрешении FullHD. Означает ли это, что видеокарте надо отренедрить текстуру стены в каком-то «половинном» разрешении (т. е. FullHD/2)? Нет! Если в сцене мы наблюдаем две стены, каждая из которых занимает половину экрана и «покрыта» текстурой FullHD, видеокарта будет рендерить 2*FullHD текселей. И так со всеми объектами, а их в сцене сотни. Предположим условно, что надо отрендерить 100 объектов, для каждого из которых используется по одной текстурной карте с разрешением 1024х1024. Тогда получим 104 857 600 текселей, или округленно 0,1 GTexel (на каждый кадр). Значит, наша карта сможет обеспечить для такой сцены частоту 2.4 / 0,1 = 24 кадра в секунду. Таким образом, мы нашли верхний предел возможностей карты обеспечить более-менее комфортное восприятие движущейся картинки. Разумеется, здесь речь не идет о комфортном выводе изображения на жидкокристаллический монитор (60 кадров) или в шлем VR (90 кадров).
Проблема ограничения возможностей карты по количеству обрабатываемых текселей в секунду остроумно решается в играх с открытым миром (например, от Bethesda), где необходимо выводить на экран огромные пространства и тысячи объектов. Для человека естественно видеть то, что находится далеко, размытым и нечетким. Столь же естественно просто терять из виду мелкие объекты. Поэтому очевидным было решение скрывать удаленные мелкие объекты, а текстуры высокого разрешения заменять на текстуры низкого разрешения, что и обеспечивает возможность одновременно вывести на экран сотни объектов, уложив их обработку в некий заданный пользовательскими настройками текстур лимит Texture Fillrate. Для поддержки высокой частоты кадров при обработке вершин (выполняемой шейдерными процессорами) используется аналогичное решение — заменять геометрию удаленных объектов с детальной на упрощенную.
Из всего сказанного выше можно сделать простой практический вывод. Основные ресурсы видеокарты уходят на обработку геометрии и вычисление проекционных координат текстур и их визуализацию. Поэтому скорость отрисовки трехмерной сцены зависит не столько от разрешения результирующего кадра (см. «запас» Pixel Fillrate), сколько от количества и размера карт текстур и сложности топологии объектов. Миллионы пикселей (текселей) больших карт занимают в памяти много места (1024 * 1024 = 1 048 576 пикселей) и требуют много процессорного времени для обработки. Более частая, густая сетка каркаса объекта содержит больше вершин — следовательно, опять же больше данных для обработки.
ROPs / TMUs (4 / 4) — количество блоков растеризации / текстурирования, отвечающих за отправку просчитанных кадров в буфер видеокарты (т. е. уже в сторону вывода на экран) и их постобработку / выборку данных из памяти. Количество блоков в видеокарте влияет на ее производительность. В частности, число ROP определяет Pixel Fillrate, а от числа TMU зависит скорость выборки текстур из памяти и, соответственно, показатель Texture Fillrate . Исходя из того, что мы уже сказали про оба показателя, можно сделать вывод, что наиболее критичным является Texture Fillrate и, следовательно, количество блоков TMU.
ВМЕСТО ЗАКЛЮЧЕНИЯ
Итак, мы обсудили все ключевые параметры видеокарты и постарались ясно описать их взаимосвязь между собой и с другим оборудованием компьютера.
В следующем разговоре мне хотелось бы перейти к финансовой стороне вопроса и описать методику сопоставления стоимости характеристик видеокарт, которая позволяет взвесить характеристики разных видеокарт и соотнести их (характеристики) с ценами на устройства.
В заключение приглашаю отдать дань ретро-устройствам и полюбоваться на дизайн видеокарты, которая верно послужила нам в качестве примера (на фотографии слева).
Любое использование данной статьи должно содержать ссылку на эту публикацию.
Что важнее ROP,TMU или потоковые процессоры на видеокарте?А также еще есть унифицированные шейдерные блоки.
В нете ищу но и тут тоже собираю информациюю.
Пока узнал что филрейт (скорость заполнения пикселов) зависит от числа ROP помноженых на тактовую частотту GPU.
ROP отвечают за запись пикселей в память.
TMU отвечают за скорость наложения текстур.Понятно что ето важно и чем больше тем быстрее они наложатся.
Универсальные процессоры что то обьединяют (называется T&L).Как бе заполнения вершын и текстур?Лично моя практика показывает что: 1 идут ROPs, 2 TMUs и 3 Шейдеры унифицированные (они кстати в основном важны в рендеринге видео), а ROP и TMU больше для игр важны и желательно что бы их было примерно одинаковое колличество, а не так как у меня 16 ROPs и 96 TMUs. В итоге моим TMU не на что накладывать текстуры 🙂
P.S. А вообще, я бы лучше не на ROPs и TMUs смотрел а на Pixel и Texture Fillrate. У меня PF 16, TF 96 и этого маловата, если TF еще нормально (желательно выше 100 сейчас, для 1920×1080 разрешения) то PF не менее 20 это точно.