NVIDIA Turing
Архитектура NVIDIA Turing ™ стала крупнейшим прорывом со времен изобретения GPU NVIDIA ® CUDA ® в 2006 году. Она совмещает в себе технологии трассировки лучей в реальном времени, моделирование, растеризацию и искусственный интеллект, кардинально изменяя компьютерную графику.
ТРАССИРОВКА ЛУЧЕЙ В РЕАЛЬНОМ ВРЕМЕНИ В ПРОФЕССИОНАЛЬНОЙ ГРАФИКЕ
Архитектура Turing оснащена ядрами RT для ускорения трассировки лучей и новыми тензорными ядрами для инференса искусственного интеллекта. Вместе эти технологии впервые позволяют осуществлять трассировку лучей в реальном времени, открывая потрясающие возможности для творчества, которые до настоящего момента, казалось, могут стать осуществимыми лишь в далеком будущем.
ИННОВАЦИИ TURING
ЯДРА RT ДЛЯ ТРАССИРОВКИ ЛУЧЕЙ В РЕАЛЬНОМ ВРЕМЕНИ
Архитектура Turing оснащена специальными процессорами для трассировки лучей – ядрами RT. Они ускоряют расчеты перемещения света и звука в 3D-средах до 10 миллиардов лучей в секунду. Turing позволяет осуществлять трассировку лучей в реальном времени до 25 раз быстрее по сравнению с предыдущим поколением GPU NVIDIA Pascal™, а финальный рендеринг эффектов в фильмах более чем 30 раз быстрее по сравнению с CPU.
ТЕНЗОРНЫЕ ЯДРА ДЛЯ УСКОРЕНИЯ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Turing оснащена новыми тензорными ядрами; эти процессоры ускоряют тренировку и инференс глубоких нейронных сетей, обеспечивая до 500 трлн тензорных операций в секунду. Данный уровень производительности существенно ускоряет такие функции на базе искусственного интеллекта, как шумоподавление, масштабирование разрешения и изменение скорости видео, а также позволяет быстрее создавать приложения с новыми производительными возможностями.
НОВЫЙ ПОТОКОВЫЙ МУЛЬТИПРОЦЕССОР
Архитектура Turing существенно улучшает производительность растеризации по сравнению с предыдущим поколением GPU Pascal благодаря улучшенным процессам обработки графики и программируемым технологиям шейдинга. Технологии включают в себя Variable-Rate Shading, Texture-Space Shading и Multi-View Rendering, которые обеспечивают более гибкую интерактивность работы с большими моделями и сценами, а также улучшенными возможностями в VR.
Архитектура Turing и особенности новых видеокарт GeForce RTX
Жизненный срок видеокарт семейства Pascal оказался довольно долгим. Старшие модели продержались на рынке более двух лет и еще будут присутствовать некоторое время в продаже. В течение этого периода мы увидели новые решения на архитектуре Volta, которые остались уделом специализированных ускорителей вычислений. Единственным игровым продуктом семейства Volta стал TITAN V, выпущенный небольшим тиражом при чрезвычайно высокой цене. Но теперь настал момент старта нового поколения, которое должно изменить все. Новые видеокарты на архитектуре Turing не просто привносят очередное повышение производительности, они несут в себе ряд технологических инноваций и являются первыми игровыми решениями, которые поддерживают трассировку лучей в реальном времени. Поэтому даже привычное название GeForce GTX было изменено на GeForce RTX. В данном обзоре мы поговорим об особенностях архитектуры Turing и технических параметрах новых GPU. Практическому знакомству с видеокартами, включая тестирование и сравнение со старыми моделями NVIDIA, будут посвящены следующие обзоры.

Видеокарты GeForce RTX
В семействе Turing можно выделить несколько ключевых изменений. Это абсолютно новая архитектура GPU, появление новых вычислительных блоков — тензорных и RT ядер, ускоренная обработка шейдеров.

На данный момент представлено три видеокарты — GeForce RTX 2080 Ti, GeForce RTX 2080 и GeForce RTX 2070. Все они базируются на разных GPU Turing. Топовая модель получила самый мощный процессор TU102, кристалл которого изображен ниже на слайде.

Вначале приведем блок-схему каждого нового GPU, опишем общие характеристики видеокарт, а потом детально рассмотрим архитектурные изменения. Все процессоры производятся по технологии 12-нм FinFET. Они сохраняют кластерную структуру, когда GPU состоит из нескольких GPC, и, меняя количество таких кластеров, масштабируется производительность каждого конкретного чипа.
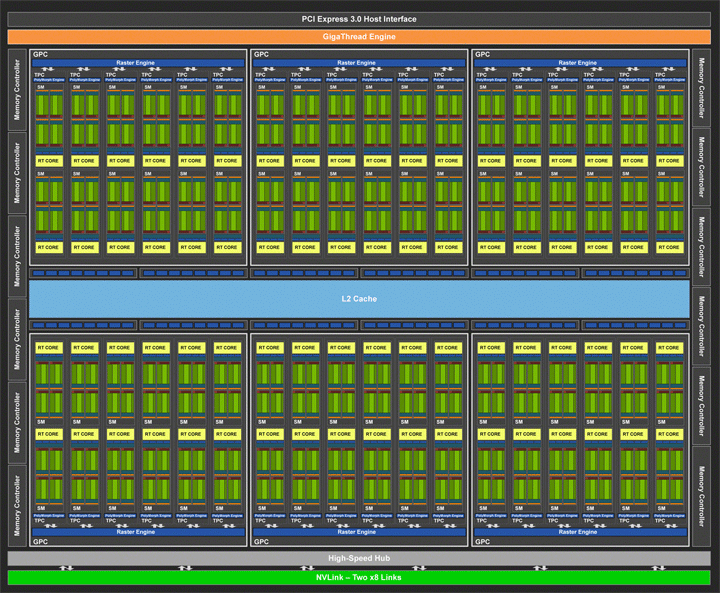
TU102 (GeForce RTX 2080 Ti)
Старший графический процессор TU102 состоит из 18,6 миллиардов транзисторов при площади кристалла 754 кв.мм. Если сравнить его с GP102 (GeForce GTX 1080 Ti), то площадь нового чипа и количество транзисторов выросло на 55–60%. У TU102 всего шесть кластеров GPC, каждый содержит по шесть текстурно-процессорных кластеров TPC, объединяющих мультипроцессорные блоки SM. Последние заметно реорганизованы и включают новые блоки, о чем подробнее будет сказано ниже. Каждый SM-блок насчитывает 64 основных вычислительных блока (CUDA-cores). При 72 SM всего получается 4608 потоковых процессоров. Однако GPU GeForce RTX 2080 Ti (как в свое время и у GeForce GTX 1080 Ti) немного урезан. У топовой видеокарты отключены два SM, в итоге общее количество потоковых процессоров равно 4352. Также у данного решения имеется 544 новых тензорных ядра и 68 RT-ядер, 272 текстурных блока и 88 блоков растеризации ROP.
Для сравнения можно напомнить, что GeForce GTX 1080 Ti на базе GP102 оперировал только 3584 ядрами CUDA при 224 текстурных блоках. Так что наращивание потенциала у нового TU102 весьма значительное. Шина памяти осталась 352-битной, но используются новые микросхемы памяти GDDR6 с эффективной частотой обмена данными, эквивалентной значению 14 ГГц. Объем памяти 11 ГБ на уровне старого флагмана, и это вполне достаточно для современных игр в высоких разрешениях.
Судя по блок-схеме у процессора TU102 всего 12 контроллеров памяти разрядностью 32 бита. Поэтому чип может работать с 384-битным интерфейсом. Возможно, мы увидим такую шину вместе с 4608 потоковыми процессорами в новых Titan. Кэш L2 у GeForce RTX 2080 Ti достигает 5632 КБ. Очевидно, что полный объем L2 равен 6 МБ, но он немного порезан вместе с шиной.
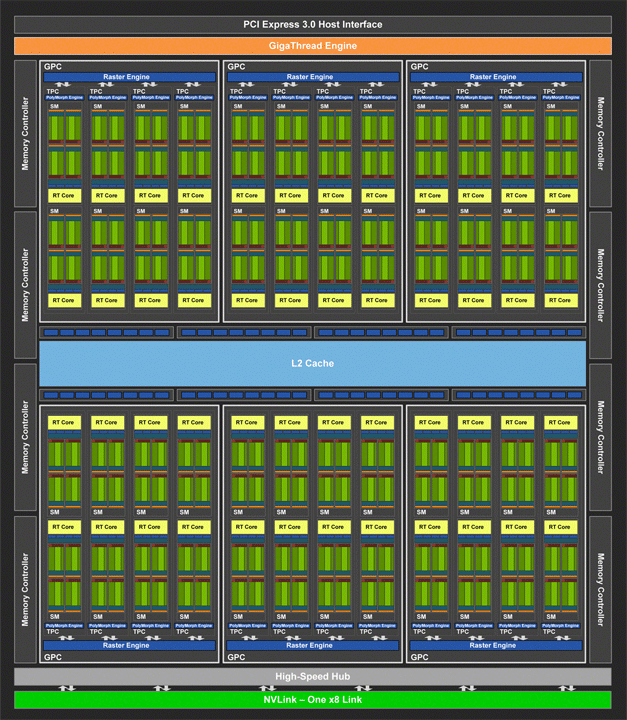
TU104 (GeForce RTX 2080)
Следующий в иерархии процессор TU104 имеет конфигурацию из шести кластеров GPC по четыре TPC. В прошлом поколении Pascal сохранялась идентичность внутренней структуры кластеров для решений среднего и топового уровня, лишь в бюджетных GPU уменьшалось количество TPC. Вероятно, такая конфигурация TU104 является оптимальной для сохранения некоего баланса производительности и гибкого управления ресурсами — число кластеров на уровне топового GPU, но они слабее. При этом задействовано 46 SM-блоков из 48, что дает 2944 активных вычислительных ядер CUDA, 368 тензорных ядер, 46 ядер RT и 184 текстурных блока. Объем кэш-памяти L2 равен 4 МБ, что вдвое выше объема L2 у GP102 (GeForce GTX 1080).
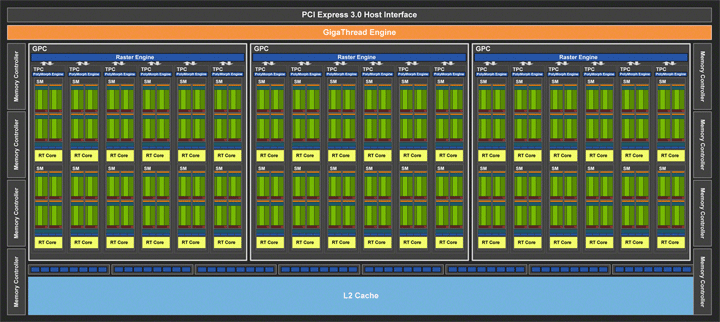
TU106 (GeForce RTX 2070)
Неожиданностью стала премьера третьего чипа для GeForce RTX 2070. По аналогии с прошлыми поколениями можно было ожидать простого урезания блоков на процессоре старшей видеокарты. Но основой GeForce RTX 2070 стал GPU TU106 с тремя стандартными кластерами по шесть TPC. Общее количество потоковых процессоров 2034, тензорных блоков 288, блоков RT 36, текстурных блоков 144. При прямом сравнении GeForce RTX 2070 с GeForce RTX 2080 получается разница 28% по вычислительным блокам. Кэш-память L2 осталась на уровне 4 МБ.
TU104 и TU106 обладают 256-битной шиной памяти (8 контроллеров разрядностью 32 бит). При этом видеокарты используют память GDDR6 с эффективной частотой 14 ГГц, что обеспечивает рост пропускной способности памяти относительно прошлого поколения.
Как видим, общая конфигурация вычислительных блоков даже у младшего GPU достаточно мощная, не говоря уже о топовом TU102. А ведь в них еще появились и новые функциональные блоки. Поэтому чипы Turing являются сложными и довольно крупными кристаллами. TU102 состоит из 18,6 млрд. транзисторов, TU104 из 13,6 млрд., а TU106 насчитывает 10,8 млрд. транзисторов. В итоге даже при переходе на 12-нм техпроцесс мы не видим роста рабочих частот. Если говорить, о GeForce RTX 2080 Ti, то тут вообще заявлено базовое значение в 1350 МГц при Boost Clock до 1635 МГц. Для младших GPU рабочие частоты выше, но они примерно на уровне моделей Pascal.
С частотами связан один интересный момент. Впервые NVIDIA вводит разные Boost-частоты при одинаковых базовых значениях. В официальных спецификациям мы видим более высокие значения Boost для моделей Founders Edition производства самой NVIDIA. При этом остальные карты тоже обозначены как Reference, что вводит в заблуждение, поскольку именно референсные версии мы привыкли ассоциировать с Founders Edition. У нас была возможность быстро сравнить видеокарту от NVIDIA с моделью другого производителя, и в реальности разница по частотам минимальная. Так что не стоит бояться разных характеристик. При наличии хорошего охлаждения производительность всех GeForce RTX одной серии будет схожей. Хуже остальных могут оказаться те редкие модели с кулером турбинного типа, которые анонсировали некоторые партнеры.
| Видеоадаптер | GeForce RTX 2080 Ti | GeForce RTX 2080 | GeForce RTX 2070 |
|---|---|---|---|
| Ядро | TU102 | TU104 | TU106 |
| Количество транзисторов, млн. шт | 18600 | 13600 | 10800 |
| Техпроцесс, нм | 12 | 12 | 12 |
| Площадь ядра, кв. мм | 754 | 545 | 445 |
| Количество потоковых процессоров CUDA | 4352 | 2944 | 2304 |
| Количество тензорных ядер | 544 | 368 | 288 |
| Количество ядер RT | 68 | 46 | 36 |
| Количество текстурных блоков | 272 | 184 | 144 |
| Количество блоков рендеринга | 88 | 64 | 64 |
| Частота ядра Base, МГц | 1350 | 1515 | 1410 |
| Частота ядра Boost, МГц (Reference) | 1545 | 1710 | 1620 |
| Частота ядра Boost, МГц (Founders Edition) | 1635 | 1800 | 1710 |
| Шина памяти, бит | 352 | 256 | 256 |
| Тип памяти | GDDR6 | GDDR6 | GDDR6 |
| Частота памяти, МГц | 14000 | 14000 | 14000 |
| Объём памяти, ГБ | 11 | 8 | 8 |
| Поддерживаемая версия DirectX | 12 | 12 | 12 |
| Интерфейс | PCI-E 3.0 | PCI-E 3.0 | PCI-E 3.0 |
| Мощность, Вт | 250/260 | 215/225 | 175/185 |
| Официальная стоимость | MSRP $999 Founders $1199 |
MSRP $699 Founders $799 |
MSRP $499 Founders $599 |
TDP новых видеокарт остался примерно на старом уровне. Так, для GeForce RTX 2080 Ti Founders Edition заявлено 260 Вт и 250 Вт для партнерских версий. Для GeForce RTX 2080 это 225 и 215 Вт, что выше TDP серии GeForce GTX 1080, но в целом приемлемо для топовых продуктов.
После общего обзора новых GPU поговорим непосредственно об инновациях архитектуры Turing.
Особенности архитектуры Turing
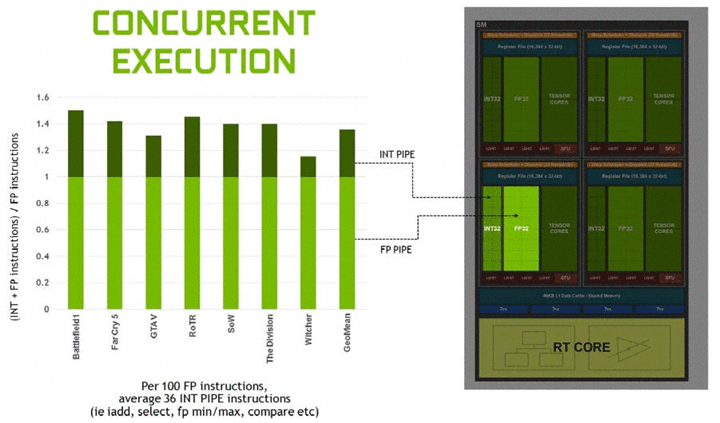
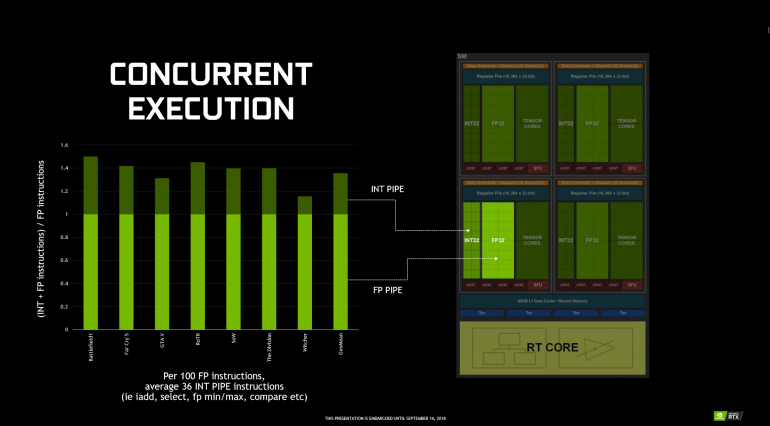
Важные изменения произошли на уровне мультипроцессорных блоков SM, которые имеют стандартную структуру во всех вариантах GPU Turing. Новая архитектура наследует возможности вычислительной архитектуры Volta и игровой архитектуры Pascal. Все вычислительные блоки внутри SM сгруппированы в четыре массива обработки данных со своей управляющей логикой (данные регистров, планировщик). В одном SM насчитывается 64 потоковых процессора. И эти вычислительные блоки теперь умеют одновременно выполнять целочисленные операции (INT32) и операции с плавающей запятой (FP32). Кстати, на схеме SM они обозначены, как разные функциональные блоки. Интересно, что у Pascal было по 128 ядер CUDA в SM, но расчеты формата INT и FP производились в последовательном порядке.
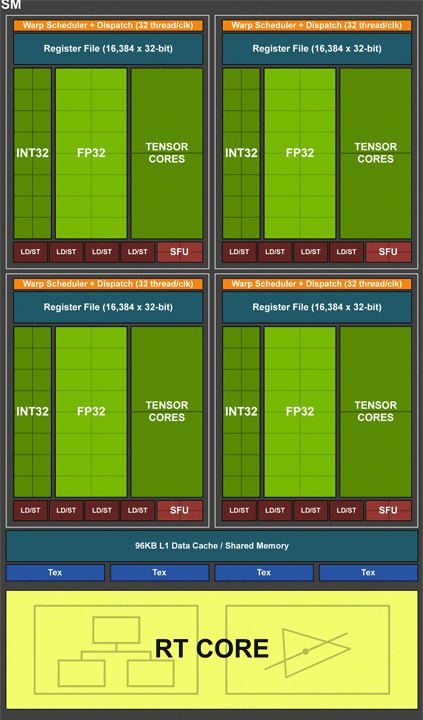
Согласно данным NVIDIA в современных приложениях при выполнении игровых шейдеров целочисленные вычисления занимают до 36%. И выполнение операций двух типов в один поток значительно ускорит общие вычисления. Тут заодно можно сказать о некоем дисбалансе, поскольку полное дублирование INT32 и FP32 не нужно. Но такая структура может быть актуальной для неигровых вычислений и задач.
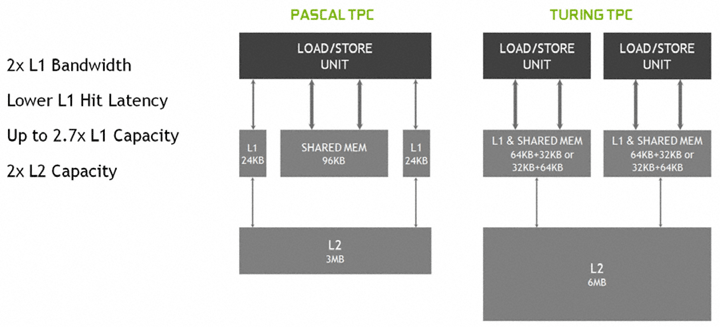
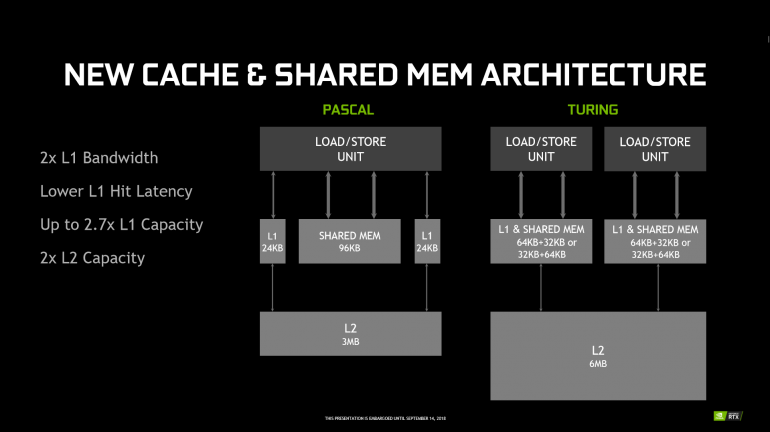
Обновленная унифицированная структура кэша L1 позволяет конвейеру TPC эффективнее работать с ним. При сохранении общего объема кэша L1 на уровне 96 КБ меньше латентность, а общая пропускная способность может вырасти до двух раз. Также во всех процессорах увеличен объем общего кэша L2. К примеру, в GPU TU102 это 6 МБ вместо 3 МБ у старого GP102.
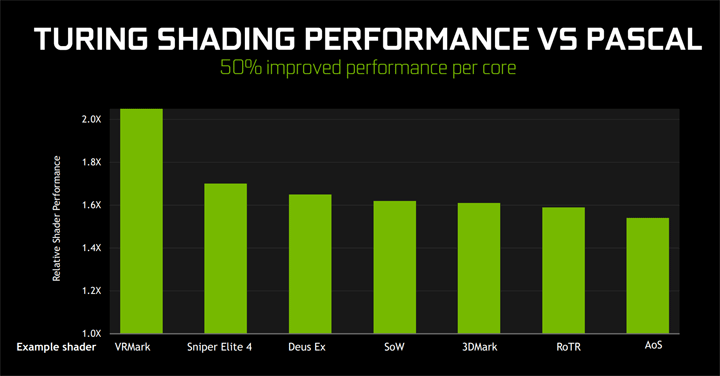
Появились и абсолютно новые блоки. Это восемь тензорных ядер для математических операций машинного обучения и один блок RT (Ray-tracing) для расчетов трассировки лучей. Но даже без учета новых блоков и новых возможностей рендеринга NVIDIA говорит о среднем росте шейдерной производительности около 50%, что звучит весьма внушительно. В виртуальной реальности VR этот прирост двукратный и даже выше. Это выглядит очень оптимистично, и походу статьи мы раскроем много нюансов, которые дают такой комплексный эффект.
В очередной раз улучшены алгоритмы сжатия данных в буфере кадра, что уменьшает количество обращений к внешней памяти. В сочетании с чипами GDDR6, которые работают при 14 Гбит/с, утверждается о росте эффективной пропускной способности до 50%. Отдельных пользователей насторожило, что GeForce RTX 2080 Ti сохранил объем в 11 ГБ, а GeForce RTX 2080/2070 получили по 8 ГБ памяти, ведь это на уровне существующих моделей Pascal. Однако такого объема сейчас хватает для высоких разрешений, а Turing в теории еще более эффективно работает с памятью.
Чипы Turing получили поддержку новых feature level из Direct 12. Улучшены асинхронные вычисления. Также новая архитектура имеет ряд улучшений для ускоренной обработки шейдеров.
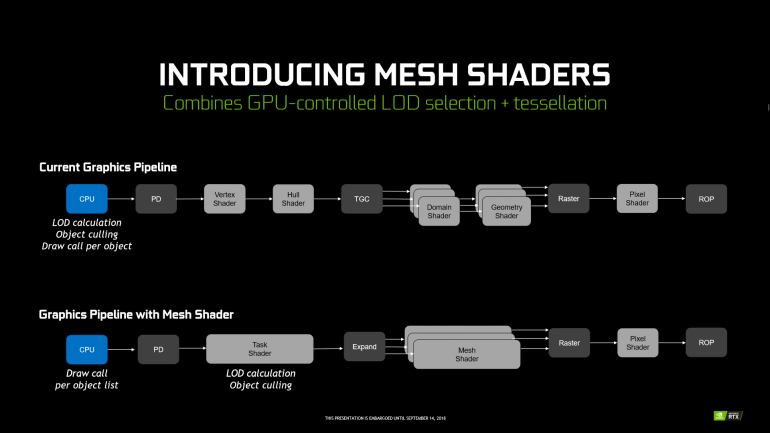
Mesh Shading предлагает новый единый конвейер геометрии, заменяя вершинные, геометрические шейдеры и тесселяцию. Это более гибкий в управлении конвейер с новым типов шейдеров Task Shaders и Mesh Shaders, который позволяет одновременно работать с геометрией группы объектов, уменьшая общее количество draw calls.

Mesh Shading будет эффективен в сценах со множеством объектов и сложной геометрией, позволяя более гибко управлять LOD. На уровне DirectX 12 его можно реализовать через NVAPI. Также поддержку Mesh Shading добавят в OpenGL и Vulkan.

Перспективно выглядит технология Variable Rate Shading (VRS). Этот метод позволяет регулировать качество шейдинга в семплах 4×4 пикселя. Это дает возможности для гибкой оптимизации. Например, на периферии изображение может быть размыто эффектами Motion Blur и высокая точность проработки семплов тут не имеет значения. Это весьма актуально для гоночных игр, где дорога и окружение на периферии кадра часто смазываются.

Три алгоритма используют VRS:
- Content Adaptive Shading — уменьшает скорость шейдинга для зон со слабо изменяющимся цветом;
- Motion Adaptive Shading — вариативное качество для движущихся объектов;
- Foveated Rendering — снижение качества для областей вне зоны фокусировки.

Все это требует внедрения со стороны разработчиков. Однако VRS может реально улучшить производительность. Также это один из факторов, снижающих нагрузку на видеопамять.
Turing поддерживает новую модель Texture Space Shading (TSS). Значения шейдерных данных хранятся в памяти в специальном текстурном пространстве, откуда потом могут повторно вызываться. TSS позволяет использовать такие тексели для временного рендеринга и разных систем координат.
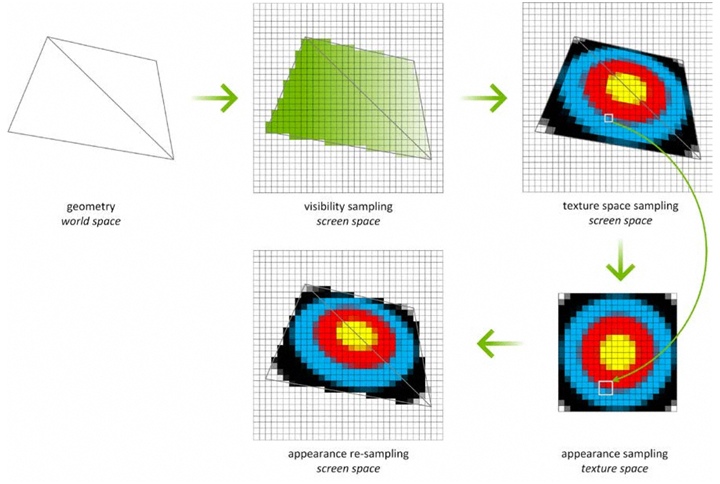
TSS является одним из элементов ускорения обработки VR. Каждый глаз видит похожее изображение. При визуализации кадра правого глаза используются данные из кадра левого глаза, а заново обработаны будут только те текстели, где нет подходящих образцов.

Тензорные ядра Turing являются улучшенными ядрами Volta. Они нужны для выполнения задач с применением искусственного интеллекта. Эти блоки поддерживают расчеты в режимах INT8, INT4 и FP16 при работе с массивами матричных данных для глубокого обучения в реальном времени. Каждое тензорное ядро выполняет до 64 операций с плавающей запятой, используя входные данные формата FP16. То есть один SM с восемью ядрами обрабатывает 512 операций FP16 за такт. Вычисления INT8 проходят на удвоенной скорости 1024 операций, а для INT4 выполняется 2048 операций за такт. И топовый GPU TU102 способен обеспечить пиковую тензорную производительность до 130,5 TFLOPS (Quadro RTX 6000).

Компания NVIDIA давно работает в области искусственного интеллекта. Однако до недавнего времени все технологии на базе обучаемых нейросетей казались уделом каких-то узкоспециализированных областей и больших дата-центров. С появлением Turing ситуация меняется, ведь мы получаем не только аппаратную платформу, но и новые программные возможности. Для интеграции возможностей искусственного интеллекта используется NVIDIA NGX (Neural Graphics Acceleration), позволяя задействовать возможности глубокого обучения для улучшения графики и визуального отображения.

На базе NGX уже реализована технология повышения разрешения изображения AI Super Rez, технология InPainting для восстановления фрагментов фотографий и некоторые другие интересные функции.

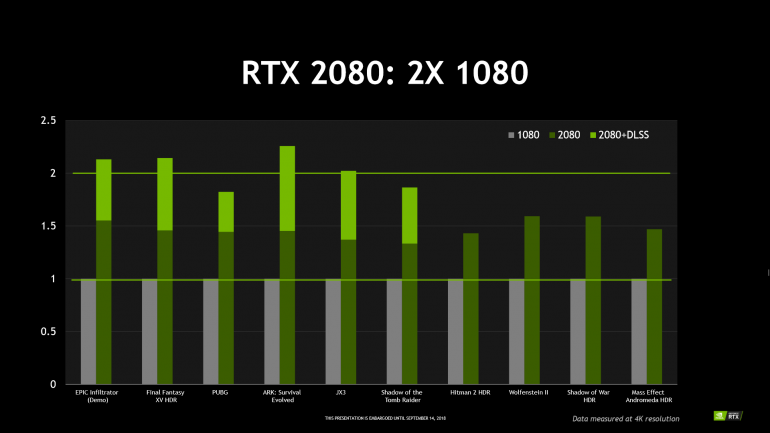
Но самым важным является сглаживание Deep Learning Super-Sampling (DLSS). Это развитие Temporal AntiAliasing (TAA) с использованием новых интеллектуальных возможностей Turing. Сейчас TAA является самым распространенным методом сглаживания, который дается с мизерными потерями производительности в несколько процентов. TAA использует данные прошлого кадра для семплов нового. При хорошем результате сглаживания краев этот метод дает определенное смазывание и дрожание картинки, особенно в динамике. DLSS использует специально обученную нейронную сеть для более быстрой и качественной выборки. Новый метод дает четкую картинку при еще меньших затратах производительности.


Сглаживание DLSS выглядит очень перспективно, причем оно легко интегрируется в игры, что упростит его популяризацию. Интересно, что на графиках NVIDIA показан весьма значительный рост fps при активации DLSS. Причина в том, что при DLSS возможны разные методы выборки, и в некоторых режимах речь, по сути, идет о реконструкции финального изображения из меньшего. То есть это действительно может ускорять рендеринг. Также надо понимать, что многие игры сейчас используют технологии адаптивного разрешения со сглаживанием через TAA. Не каждый пользователь в курсе таких тонких настроек. И если ему при автоматической настройке будет выставлен режим DLSS, то он получит заметное улучшение качества картинки при реальном росте быстродействия.
На данный момент известно об интеграции DLSS в движки Unreal Engine и Unity. А список игр, в которые добавят это сглаживание, постоянно растет.

Трассировка лучей
Также технологии нейронных сетей нужны для очистки изображения от шумов при рендеринге с использованием трассировки лучей. И тут мы подбираемся к главной особенности Turing — поддержке трассировки лучей в реальном времени. По сути, мы имеем первое поколение видеокарт, которое поддерживает новый метод рендеринга. Сейчас используется метод растеризации: объекты проецируются на плоскость экрана с последующей обработкой пикселей с учетом расстояния до плоскости проекции и наложения текстур. Поскольку индустрия развивалась много лет, то эффективность современных методов визуализации на актуальных GPU достаточно высокая. Трассировка лучей использует метод построения изображения, приближенный к реальному, имитируя прохождение лучей света в окружающей среде. При трассировке для каждого пикселя строится луч, определяющий его видимость. Далее строятся вторичные лучи от точки пересечения к источнику света для определения освещенности точки.
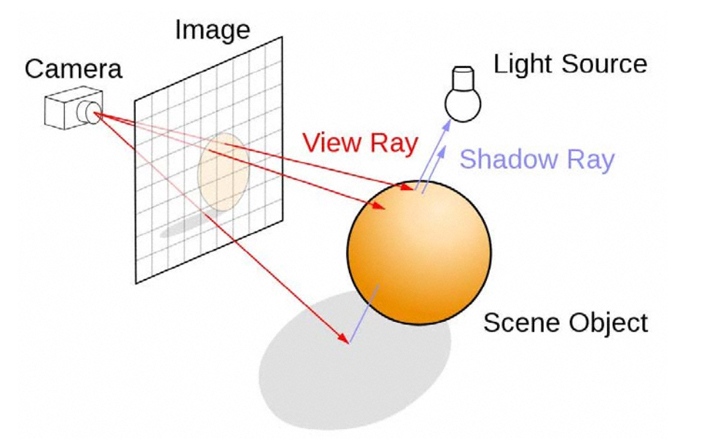
При трассировке можно корректно просчитывать не только освещенность каждой точки, но и взаимное влияние объектов друг на друга с учетом их материалов. При стандартных методах рендеринга мы видим качественную симуляцию, где правильное затенение или какие-то особенности освещения воссоздаются с использованием определенных упрощений, используются заранее подготовленные отражения, карты теней и разные методы симуляции глобального затенения. Трассировка лучей позволяет сделать все это более достоверным, лучше учитывая особенности окружающей среды и материалов объектов. И чем сложнее сцена, тем более очевидны будут преимущества трассировки.

К примеру, с трассировкой можно создавать корректные отражения с учетом всего окружения. При обычных методах лишние объекты вне зоны кадра просто отсекаются. Также лучше учитываются особенности преломленного и отраженного света, который определяется взаимным влияниеем объектов. Проще воссоздавать полупрозрачные объекты. Сейчас это неплохо симулируется, но не всегда картинка выглядит корректно во всех нюансах.
Трассировка позволяет воссоздавать реалистичные тени, учитывая направленность света и его рассеянность. Мы получим более точные контуры тени и реалистичное размытие по мере удаленности от источника освещения. Кстати, похожий эффект работает с технологией мягких теней NVIDIA HFTS.


Ну и ключевым моментом является воссоздание реалистичного объемного освещения и затенения. Многие преимущества рендеринга с использованием трассировки хорошо показаны в нижнем видеоролике.
Главным препятствием по внедрению трассировки были высокие требования к производительности системы, ведь еще недавно для этого требовались мощные графические фермы. С момента разработки этого алгоритма прошли десятки лет. Сейчас трассировка активно используется в киноиндустрии, а с выходом Turing начинается путь по внедрению данной технологии в игровую индустрию. Все понимают, что это первые шаги в данном направлении. Поэтому о полноценной трассировке пока речь не идет. NVIDIA внедряет гибридный метод рендеринга, который позволяет совмещать растеризацию с трассировкой для некоторых эффектов.

И среди новых игр, где уже заявлена поддержка трассировки, мы видим упоминание лишь некоторых эффектов. Так, в Shadow of the Tomb Raider будут реализованы реалистичные тени, в Battlefield V более качественные отражения, а в Metro Exodus реалистичное глобальное затенение.
Проект Atomic Heart обещает сразу несколько эффектов. Тут будет как реалистичное затенение, так и корректные отражения. Обратите внимание на рекурсию отражений в зеркальной поверхности в конце ролика — выглядит действительно круто.
И это лишь первая волна игр и первое поколение ускорителей GeForce RTX, которые могут обрабатывать трассировку в реальном времени.
Подробнее поговорим о технической реализации гибридного рендеринга. Процессоры Turing могут одновременно сочетать работу конвейера растеризации и трассировки. Растеризация быстрее для определения видимости объекта. Вторичные лучи при трассировке могут уже использоваться для создания качественных отражений, теней и прочих эффектов. Разработчики получат возможность регулировать степень покрытия отраженными лучами нужной поверхности. В целом же количество первичных и вторичных лучей зависит от сложности сцены и многих иных параметров.
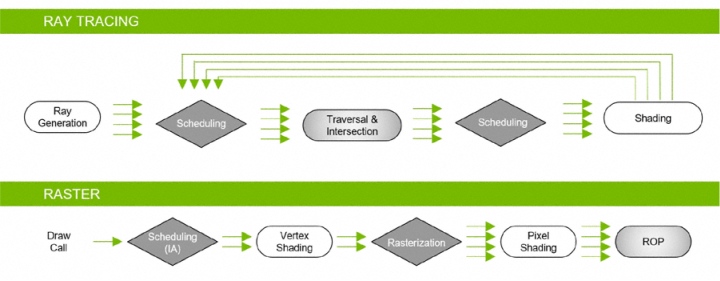
Сама трассировка не является некоей эксклюзивной особенностью NVIDIA. Компания Microsoft уже приняла расширение DirectX Raytracing (DXR) для DirectX 12. API определяет команды на выполнение, не ограничивая аппаратное устройство в методах их исполнения. Технология NVIDIA RTX предлагает сочетание программных алгоритмов и аппаратных возможностей для реализации трассировки. Естественно, что NVIDIA RTX работает в среде DirectX 12, но также NVIDIA работает над стандартизацией и внедрением технологии в Vulkan API. По слухам трассировку в среде Vulkan добавят в Final Fantasy XV: Windows Edition.
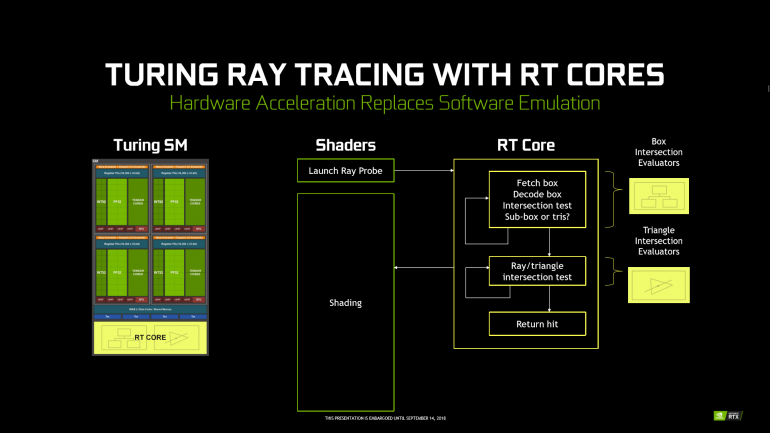
Одним из методов ускорения трассировки является применение алгоритма Bounding Volume Hierarchy (BVH). Он предполагает разбиение сцены на структуру иерархически связанных блоков, в которые входят разные геометрические примитивы. Каждый луч тестируется, проходя по этому дереву, пока не встретит на своем пути примитив. Создание иерархической структуры BVH избавляет от лишних тестов для луча.

Специальные RT-ядра берут на себя аппаратные расчеты по алгоритму BVH. Без этих блоков процессор вынужден выполнять тысячи лишних операций и расчетов.
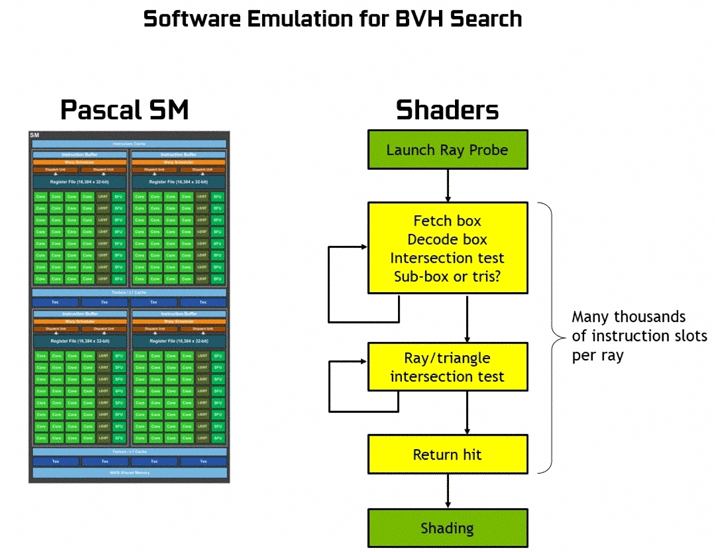
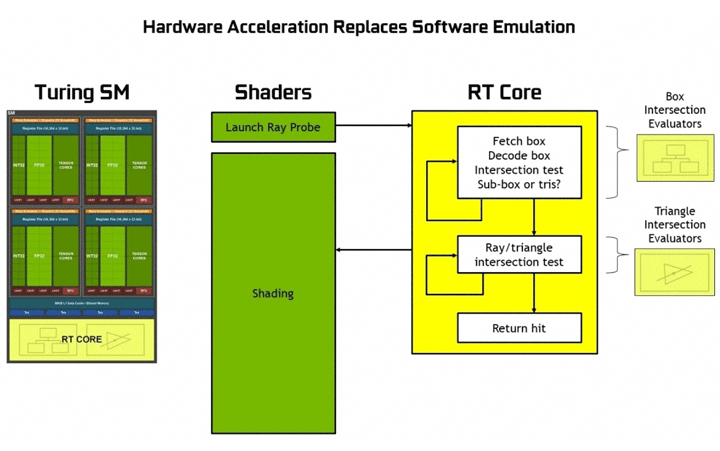
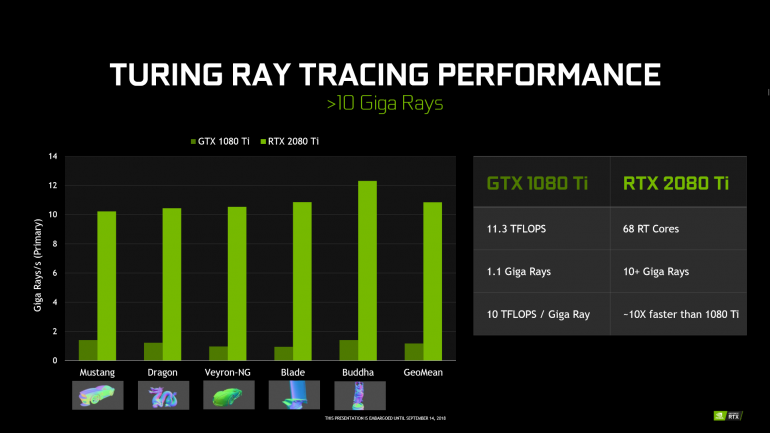
Pascal не имеет таких блоков и его производительность в трассировке значительно ниже. Для GeForce GTX 1080 Ti озвучивается цифра в 1,1 гигалучей в секунду (Giga Rays/s). GeForce RTX 2080 Ti с RT-блоками обрабатывает 10 гигалучей в секунду. Разница огромная.
При использовании трассировки лучей на изображении образуется шум, который убирается специальными фильтрами. У Turing используется аппаратное шумоподавление на основе интеллектуальных алгоритмов с использованием глубокого обучения, обеспечивая работой тензорные блоки.
С переходом к гибридному рендерингу получается разная нагрузка на определенные блоки GPU. Нижняя схема показывает примерное распределение нагрузки для вывода одного кадра. При использовании DLSS около 20% времени кадра нужно для тензорных вычислений, а 80% — для обычного рендеринга с использованием ядер CUDA. При этом трассировка требует примерно половину времени от обработки шейдеров FP32, т.е. ядра RT занимают 40% времени кадра. И еще 28% уходит на операции INT32.
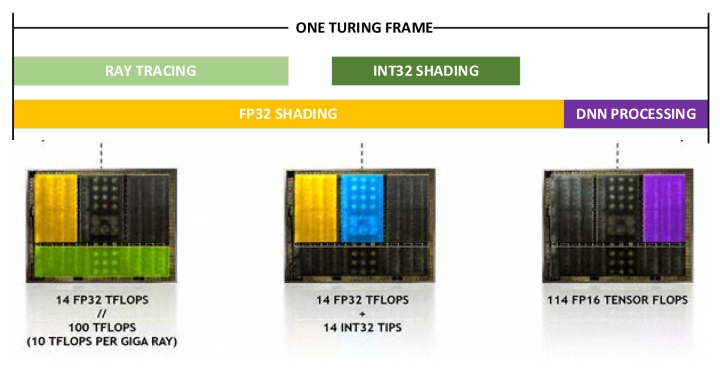
Из этого всего NVIDIA выводит новую метрику измерения комбинированной производительности в гибридном рендеринге:
RTX-OPS = TENSOR * 20% + FP32 * 80% + RTOPS * 40% + INT32 * 28% (Tera-OPS)
Для GeForce RTX 2080 Ti это 76–78 Tera-OPS, для GeForce RTX 2080 это 57–60 Tera-OPS, а для старого флагмана GeForce GTX 1080 Ti лишь 11,3 Tera-OPS.
Для наглядности приведем таблицу, в которой сведены вместе данные по скорости выполнения разных вычислений. Это пиковые показатели, с учетом небольшого различия в частотах Boost Clock.
| GeForce RTX 2080 Ti | GeForce RTX 2080 | GeForce RTX 2070 | GeForce GTX 1080 Ti | |
|---|---|---|---|---|
| RTX-OPS (Tera-OPS) | 76–78 | 57–60 | 42–45 | 11,3 |
| Rays Cast (Giga Rays/s) | 10 | 8 | 6 | 1,1 |
| FP32 TFLOPS | 13,4–14,2 | 10–10,6 | 7,5–7,9 | 16,3 |
| INT32 TIPS | 13,4–14,2 | 10–10,6 | 7,5–7,9 | н/д |
| FP16 TFLOPS | 26,9–28,5 | 20,1–21,2 | 14,9–15,8 | н/д |
| FP16 Tensor TFLOPS совместно с FP16 | 107,6–113,8 | 80,5–84,8 | 59,7–63 | н/д |
| FP16 Tensor TFLOPS совместно с FP32 | 53,8-56,9 | 40,3–42,4 | 29,9–31,5 | н/д |
| INT8 Tensor TOPS | 215,2–227,7 | 161,1–169,6 | 119,4–126 | н/д |
| INT4 Tensor TOPS | 430,3–455,4 | 322,2–339,1 | 238,9–252,1 | н/д |
Виртуальная реальность
Ускорители Turing станут самым быстрым решением для виртуальной реальности VR. Поддерживается технология Multi-View Rendering, которая является развитием Simultaneous Multi-Projection (Pascal). Это метод отрисовки изображения для разных проекций (вплоть до 32) с просчетом геометрии одновременно для нескольких проекций. Новый метод предусматривает возможность большего смещения точек обзора, позволяя работать в VR с большим углом обзора, вплоть до 200 градусов.

Из-за особенностей линз в очках виртуальной реальности на периферии качество изображения ниже, и тут можно снизить качество рендеринга. Для ускорения можно применить Foveated Rendering. Также важную роль в виртуальной среде играет правильное позиционирование звука. Качество объемного звука улучшит технология NVIDIA VRWorks Audio, которая использует метод трассировки для просчета пути звуковой волны. А поскольку теперь есть специальные блоки трассировки, то такие вычисления заметно ускорились.

Среди прочих достоинств новые видеокарты NVIDIA поддерживают VirtualLink USB Type-C для коммутации устройств VR через один интерфейс без лишних проводов.
Блок вывода изображения
Turing получил новый блок вывода изображения с интегрированной поддержкой HDR и более высоких разрешений. Появилась поддержка DisplayPort 1.4a с возможностью передавать картинку 8K при 60 Гц, плюс технология сжатия данных без потерь VESA Display Stream Compression (DSC) 1.2. Turing могут управлять двумя дисплеями 8K при частоте 60 Гц с HDR. Для сохранения оригинальных цветов рекомендуется подключать HDR-мониторы стандарта BT.2100. Всего же у видеокарт три порта DisplayPort. Еще есть один HDMI 2.0b с поддержкой HDCP 2.2.
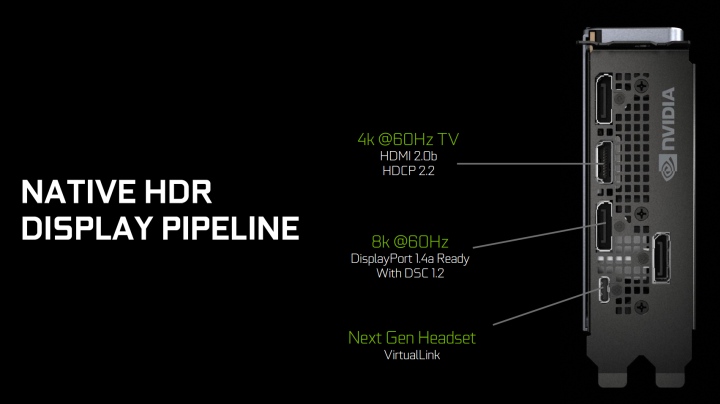
Упомянутый VirtualLink тоже позволяет подключать 8K-мониторы. Физически он выполнен в виде порта USB Type-C. Изначально интерфейс разработан для простого подключения гарнитур VR.
В процессорах Turing улучшен блок кодирования видео NVENC. Появилась поддержка кодирования H.265 8K при 30 кадрах. Заявлена некая экономия битрейта до 25% для HEVC и до 15% для H.264, что, вероятно, стоит понимать, как повышение качества кодирования относительно прошлого поколения видеокарт. При этом аппаратный кодер работает заметно быстрее программного x264, обеспечивая минимальную нагрузку на CPU при стриминге даже в 4K. Кроме качественного стриминга можно ожидать и новые возможности для обычного захвата видео. При наличии аппаратного 8K-кодировщика функция захвата в 8K должна появиться и в Shadowplay, хотя пока она не заявлена.
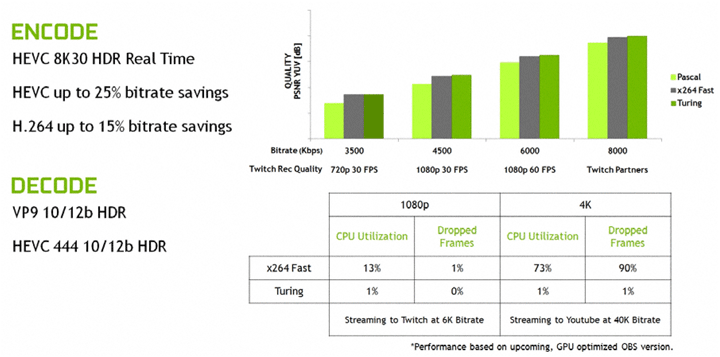
Обновлен и декодер видео для воспроизведения видеоконтента: поддерживается декодирование HEVC YUV444 10/12b HDR с частотой 30 кадров в секунду, H.264 8K и VP9 10/12b HDR.
Технология SLI
В поколении Pascal была улучшена пропускная способность в SLI-режиме благодаря использованию двух разъемов MIO с парой соответствующих мостиков. В новых процессорах Turing TU102 и TU104 используется интерфейс NVLink второго поколения для обмена данными между GPU. В TU102 реализовано две линии x8 второго поколения NVLink, а в TU104 одна линия x8. Двунаправленная пропускная способность одной такой линии составляет 50 Гбайт/с. Благодаря новому интерфейсу SLI поддерживаются новые высокие разрешения. Для GeForce GTX 2080 в SLI доступен режим 8K, 4K Surround 144 Гц или 5K при 75 Гц. GeForce GTX 2080 Ti поддерживает даже 8K Surround.
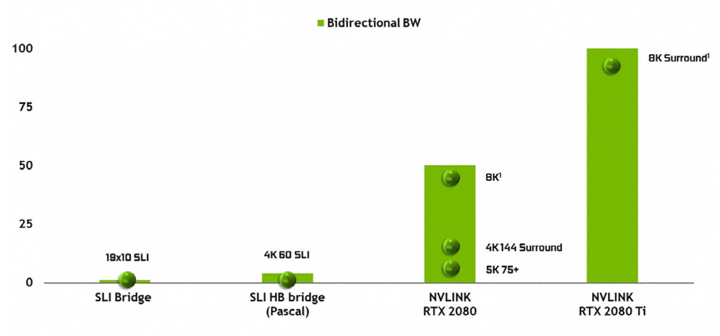
SLI позволяет объединять только две видеокарты. И сам этот режим доступен лишь на GeForce GTX 2080 Ti и GeForce GTX 2080. Стоимость нового мостика SLI на официальном сайте 79 долларов.
Новые возможности GeForce Experience
Появление новых аппаратных возможностей позволило расширить функциональность программного приложения GeForce Experience. В частности, владельцам новых видеокарт будет доступен Ansel RTX.

В новом Ansel можно создавать скриншоты с трассировкой лучей. Причем в режиме паузы качество трассировки будет выше, чем в игре в режиме реального времени.

Технология нейронных сетей позволит делать скриншоты повышенного разрешения с лучшим качеством и проработкой.

Плюс возможность обрабатывать снимки, накладывая разные изображения друг на друга, добавлять стикеры. Будут новые фильтры. Интеграцию Ansel получат многие новые игры, хотя не везде доступны абсолютно все функции. Среди громких релизов осени с Ansel подружатся Battlefield V, Hitman 2, некоторые функции будут в Metro: Exodus.
GPU Boost 4.0 и разгон
В видеоадаптерах NVIDIA давно применяется технология GPU Boost, которая регулирует и повышает частоты ядра. Это ускорение со множеством промежуточных значений, где ключевым является удержать видеокарту в определенных рамках мощности и температур. В очередной раз напомним, что NVIDIA указывает базовое (минимальное) значение частоты и среднее значение Boost Clock. При определенных условиях в игровой нагрузке частоты будут выше заявленного Boost. При хорошем охлаждении так зачастую и происходит. И это отличается от системы обозначений частот у видеокарт AMD, где вплоть до семейства Vega указывалось максимальное значение частоты ядра.
Алгоритм работы GPU Boost постоянно совершенствуется. В прошлом поколении был реализован GPU Boost 3.0, где впервые ппользователь получил возможность настроить кривую частот через через программные настройки специальных утилит. В новом GPU Boost 4.0 пользователю доступно еще больше возможностей для тонкой настройки, где можно контролировать вторую точку целевой температуры и определять время работы при достижении температурных лимитов.

Новые функции настройки Boost с гибким подбором параметров температурной кривой доступны в утилите EVGA Precision X1.
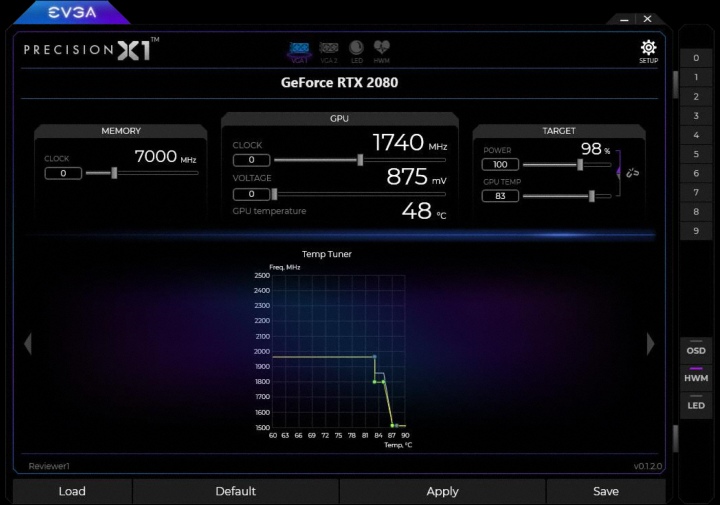
Также в Turing появилась функция автоматического подбора частот для разгона. NVIDIA Scanner запускает специальный тест для проверки на стабильность при постепенном повышении частот. Такое сканирование и тест занимают 20 минут, но довольно точно определяют потолок максимальных частот, избавляя пользователя от лишних тестов. Очень удобно, особенно, для тех, кто слабо разбирается в этой теме. Поддержка NVIDIA Scanner есть в новой версии MSI Afterburner и EVGA Precision X1.
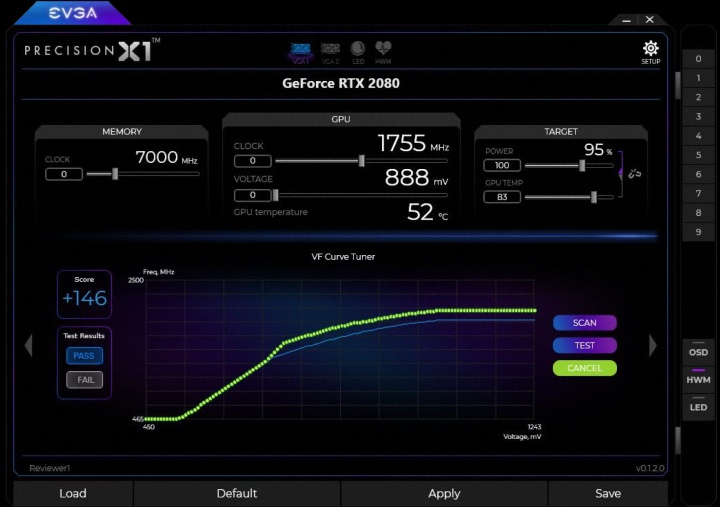
Если производитель дает некие возможности для ускорения видеокарт, то он уверен в качественной реализации питания и дополнительном потенциале охлаждения для таких манипуляций.
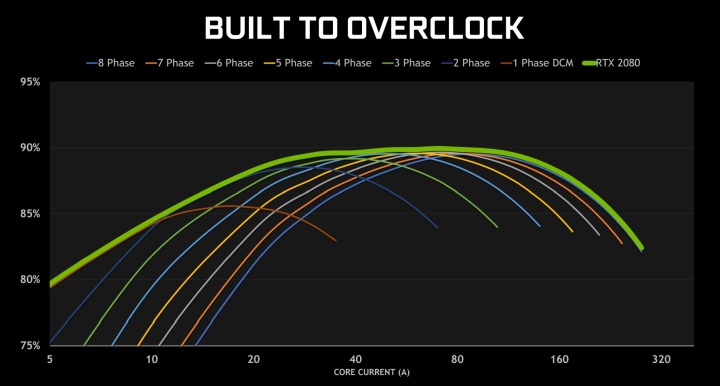
Не случайно установлены столь высокие цены на версии Founders Edition. Если в прошлом поколении это казалось переплатой исключительно за раннюю доступность на рынке и эксклюзивность, то теперь чувствуется серьезный основательный подход. Видеоадаптеры Turing получили новое охлаждение с большим радиатором, испарительной камерой и двумя вентиляторами. Даже по весу чувствуется, что это качественный продукт с мощным охлаждением.

Впервые референсные карты от NVIDIA не требуют компромиссов, а сразу обеспечивают отличные температурно-шумовые характеристики. Плюс изначально прошиты более высокие частоты Boost, и есть все возможности для реализации разгона без замены охлаждения.
Подробнее о конкретных экземплярах GeForce RTX мы поговорим в будущих обзорах.
Выводы
NVIDIA Turing — передовая графическая архитектура, которая расширяет возможности привычного рендеринга, добавляя трассировку лучей в реальном времени и возможность использовать нейронные сети для вспомогательных функций. Новые аппаратные возможности обеспечивают поддержку совершенно новых технологий и графических эффектов. Появление Turing стало знаковым событием, которое обозначает старт новой эры и постепенную интеграцию трассировки в игровую индустрию. Уже есть первые проекты, где будет поддержка эффектов на базе трассировки NVIDIA RTX. Еще больше игр получат поддержку нового сглаживания NVIDIA DLSS. Также в Turing есть много улучшений для ускорения традиционного рендеринга. Даже без учета трассировки вы изначально получаете самые быстрые игровые видеокарты с потенциалом для наращивания производительности после внедрения новых технологий.
Наряду со своей технологичностью новое поколение радует качественным подходом к проектированию конечных устройств. Референсные ускорители GeForce RTX перешли на новое охлаждение, есть функции для более простого разгона. Все сделано для того, чтобы удовлетворить запросы самого требовательного пользователя и оправдать высокую стоимость видеокарт.
О производительности GeForce RTX 2080 и GeForce RTX 2080 Ti в существующих играх мы поговорим в следующих обзорах, которые выйдут в ближайшие дни. Оставайтесь с нами и следите за новостями!
NVIDIA Turing — An Overall Perspective
![]()
When NVIDIA released the new RTX 20 and GTX 16 series cards, they fundamentally changed the way graphics would be delivered in the future. They touted a promising future of hitting the ‘Holy Grail’ of photorealism and accuracy for our games like we have never seen, with the promise to deliver real-time ray tracing at 60 frames per second in-game. They would deliver this promise via their new graphics architecture entitled “Turing”, named after the famous English mathematician and computer scientist, Alan Turing. Today, we’re going to dive a bit deeper on the Turing architecture, the GTX 16 and RTX 20 series graphics cards from NVIDIA and how they stack up to their main competitor, AMD, in the industry.
Now I understand not everyone here is going to totally understand the ramifications of what NVIDIA has set forward with Turing, nor do I expect everyone to understand technical terms like “ray tracing” and “GDDR6”, so I will try and keep things simple here for most people to understand. I make this guide for layman who might play games on his PC, but who doesn’t have expertise in understanding graphics. So, let’s get started.
What is Turing?
“Turing” is the new codename for NVIDIA’s latest graphics micro-architecture. In a simple way, a ‘graphics architecture’ or ‘micro-architecture’ is the fundamental underlying technical design of a set of semi-conductors or computer chips. I will use these terms interchangeably, but they mean the same thing. Computer chips are known as “microprocessors” and graphics chips are most commonly known as “GPUs”. This isn’t the most technical set of definitions, it’s not even really that accurate, but that’s the best way of wrapping your head around it without too much detail to muddy the waters. Essentially, it’s how a computer chip is designed from the ground up and it contains how the computer interacts with the computer chip/microprocessor.
How a micro-architecture works is not that hard to explain. But I must first explain “instruction sets”. Instruction sets are kind of like a “recipe” for making a cake. You need to have the right sort of ingredients and steps to successfully bake the cake. Except in this case, substitute “recipe” for “instruction set” and replace “ingredients” with “instructions”. In essence, it’s for the computer chip to understand the type of data coming in (instructions) and how it should execute it (what instruction set to use). The important thing to understand from this, is that when micro-architectures are built, they are built to handle certain instruction sets.
Now that we have a grasp on instruction sets, how are they used? Well, think of it this way: If you can process more data in a smaller amount of time, you finish the “instructions” faster and therefore get higher performance. Or with the cooking analogy, if you can bake more cakes quicker, you can set them out to customers to be eaten faster. It’s a bad analogy, I know, but bear with me. But the whole goal of a new micro-architecture is to be even faster than the last one and to increase performance.
There is two main ways to increase performance in micro-architectures. You can firstly increase what is known as a “clock speed”. A “clock speed” is defined as “the speed at which a microprocessor executes instructions, usually expressed in cycles per second”. So for instance, a 1.0 GHz processor can do 1,000,000,000 cycles/hertz per second. Therefore, the faster the clock speed, the more instructions the microprocessor can execute per second. Much like the wheels on a car, the faster the wheels rotate, the faster the car can move down the track, toward the finish line. So, in this case, 5.0 GHz is faster than 2.0 GHz, with 2.0 GHz being faster than 0.5 GHz. You get the idea.
The second way you can increase performance, is by changing the amount of data that can be processed per clock cycle. So if a clock speed can process theoretically 512 Bytes of data at 2.0 GHz. Then let’s say we change the amount of data that can be processed at 2.0 GHz to 1,024 bytes of data, we have just increased the performance by two-times what it was previously, therefore, effectively doubling the performance.
So back to the Turing architecture. The Turing architecture uses what is known as “Integer” (INT) and “Floating Point” (FP) instruction sets to process data that is input into the chip by the computer. This data comes from your video game engine, of which a Turing GPU is trying to process what the game engine is telling it and how it should process the data, to display the graphics on your screen. There’s a lot of processes between the data being sent to the GPU and the GPU processing it and sending it to your display. We will save that for another time since it’s rather technical and requires explaining a lot of other details. But here’s a basic run down of how micro-processors work with instruction sets:
- Read an instruction and decode it
- Find any associated data that is needed to process the instruction
- Process the instruction
- Write the results out
If this is still a bit confusing, it was a bit for me too, just understand that Turing is sorting out FP and INT instructions and processing it to power the graphics in your games. More processing power = higher performance.
Now, Turing is the latest evolution of several architectures by the NVIDIA Corporation who specializes in making GPUs. With previous architectures coming before Turing being Pascal (GTX 10 series), Maxwell (GTX 9 series) and Kepler (GTX 7 series), with Turing being featured in the latest RTX 20 and GTX 16 series gaming graphics cards from NVIDIA. Turing is the latest and fastest commercially and consumer available architecture from NVIDIA.
What is Ray-Tracing?
Ray-tracing or ray tracing, is a difficult concept to explain because it involves understanding a little bit about how light works, however, I will try my best to explain it as simple as possible. Please forgive me if it goes over both of our heads or I might explain something too simply, I myself am not a physicist, so I don’t understand all the technicalities. But think of light like a particle, with a pre-determined path, how that light interacts with the world is dependent on so many things, how far it is from the object, whether the object it hits absorbs the light, reflects or refracts it and how intense the light is as a light source. If we can follow where the light goes after it hits objects and how the light moves on its way back to your eye (or in this case, the video game’s camera), with several millions or billions of rays at once, we can get almost photorealistic lighting and shadows, in real time. That’s the goal.
Currently, most video games do what is called “rasterization”, which is just another way of processing images and is much faster than ray tracing. The main advantage of rasterization is that because it’s so quick, it’s very fast at creating an image to display to a monitor or TV screen. Over the years, game developers and game engines have gotten very good at using tricks through rasterization, to get their way to more realistic images, colour and lighting. If you want to see how far rasterization has come, go back and compare the graphics of Quake II, to the latest game in the series, Quake Champions. Or go back and look at Call of Duty 1 and compare it to Call of Duty: Black Ops 4.
Rasterisation has the biggest downside of not being able to compute the color of pixels, thus shading is needed to fill in that information. In addition, because it’s so quick, it can’t process information very accurately, so simple details such as the accuracy of lighting, reflections and illumination aren’t very good or are completely missing in certain games. I’m sure someone will correct me in a response. However, since the early 2000’s, several techniques have been created to sort of trick these elements into video games via rasterization, such as “screen space reflections” for dynamic reflections, “shadow maps” for shadow quality, “environment maps” for quick reflections and “approximated global illumination”. On their own, these are very good techniques and have become so good they almost look real without looking at them too hard. But they do have some drawbacks.
The best way I can describe or show these drawbacks is through a video by NVIDIA.
This video is a seven minute one, but basically when RTX is “ON” it means some elements of ray-tracing are enabled, in this case, for reflections and when it’s “OFF”, it’s doing reflections solely through rasterisation via screen space reflections. The main drawback of screen space reflections is pretty evident from the video, but it boils down to, if something is off your screen with screen space reflections, the reflection won’t show on a reflective material. In this case, the car is the reflective material and the flames are off the player’s screen and thus, they are not being shown to be reflected via rasterisation, because you cannot see them. Ray-tracing fixes this, by bouncing rays of light off the car’s door from the player’s camera or perspective. When these rays are bounced they are seeing the detail away from the player’s camera or perspective and then that traced ray’s data moves back and is shown or rendered to the player. It’s pretty amazing stuff. Right? Now imagine instead of one ray being traced, it’s millions all happening at once every millisecond. It’s super computationally expensive, hence why it hasn’t been done in real time in video games before the RTX 20 series.
Turing handles ray-tracing through what it calls the “RT Core” within the microprocessor or GPU. To explain how the RT core does it, is very, very technical with an understanding of how triangles intersect, what bounding box tests are and how bounding volume hierarchy works. We are not interested in that today. But previous architectures from NVIDIA, such as Pascal or Maxwell did not include the RT core, hence why they cannot do real time ray tracing at a realistic level of performance, such as at 60 frames per second. It would be more like 8 frames per second which is incredibly choppy for gameplay. For most gamers, 30 frames per second would be the minimum and for PC Gamers they typically want at least 60 frames per second.
Changes between Turing and Previous Architectures
There are several changes from Turing and previous architectures, we will just cover the main differences between the RTX 20 series (Turing) and the GTX 10 series (Pascal) GPUs. The RTX 20 series superseded the GTX 10 series cards and is their successor. The biggest difference between Pascal and Turing is the introduction of the RT core for handling ray-tracing. There are some other minor changes such as “instruction level parallelism” and increased cache and memory storage sizes. Don’t worry about these, I will spare the super boring stuff for now, but for basic understanding, some of the structure of how these cache and memory structures work has changed, leading to increased performance.
In addition to these changes, we must also fully understand how a GPU works. With NVIDIA’s GPUs, they are made up of what they call Streaming Multiprocessors (SM’s). Each SM holds FP32 cores, Tensor Cores (‘Tensor’ is another instruction set) and INT32 cores. Don’t worry about the “32” at the end of FP and INT instructions, it just refers to 32 bits of information, but FP16 is a different instruction set to FP32. Here’s a diagram of a Turing SM:
As you can see, each FP32 core, Tensor Core and INT32 core comes as a block per SM. Each FP32 core is known as a “CUDA Core” within an NVIDIA architecture and CUDA Cores are the main thing doing processing in your favorite video games. More FP32 CUDA Cores and you generally get more performance. This is key to understanding what I will say later on in this post, so make sure you understand it. So each SM has a certain amount of CUDA Cores, in the case of Turing each SM has 64 FP32 Cores per SM. More CUDA Cores = more performance, because the GPU has higher throughput per clock cycle. Remember earlier when I said we could increase performance in two ways? More CUDA Cores = more data that can be processed at once = more performance per clock cycle. But it’s not always that simple. If we can also increase the amount of data each FP32 core can process itself, then we can also increase performance. Think of it like instead of increasing the throughput of an SM by adding more FP32 cores, we make it so the FP32 cores can do more processing on their own, so that way we can get an increase in performance with the SAME AMOUNT of FP32 cores. A lot of this is done by increasing the cache and memory structures of an SM. I think this diagram from NVIDIA will show it perfectly, where it compares the old Pascal architecture to the new Turing one.
There’s waaaaaaaay more cache and bandwidth now for each FP32 core to access, which means more throughput per FP32 core. It also means that yes, we get more performance as a result. Now two times the L2 capacity doesn’t mean two times the performance for various reasons. But it means we get an increase in performance thanks to this. However, we also can see not only has the amount of bandwidth and capacity increased, we also now have two load/store units for memory.
The biggest change is the fact there’s now multiple pipelines now in the Turing architecture versus in older NVIDIA ones, it’s shown in the diagram below. But the basics is more pipelines also means more throughput = more performance and NVIDIA achieves this through what it calls “concurrent execution” or “instruction level parallelism”, to create large gains in performance.
Instruction level parallelism is what NVIDIA calls “concurrent execution” and it basically means that now both INT and FP instructions can be executed at the same time in parallel via separate pipelines. It also means that INT, Tensor and FP can also be used independently with separate pipelines if need be. Previously the one pipeline was shared for both in architectures like Maxwell creating a bottleneck or clogging up and queuing instructions.
Turing fixes this by allowing a pipeline for each, meaning they can be done at the same time now, no longer bottlenecking, queueing and sharing resources for each other as much as they were before. This converts to extra performance in games which uses both Tensor (FP16) and FP32 instructions at the same time. This is most evident when you compare an RTX 2060 and a GTX 1070 in a game like Wolfenstein II: The New Colossus which uses both FP32 and FP16 instructions for rendering. Both the RTX 2060 and GTX 1070 carry the same amount of FP32 CUDA Cores, as both GPUs contain 1,920 CUDA Cores.
As we can see in this benchmark from ANANDTech.com, the RTX 2060 is smashing the GTX 1070 by 32% at 1080p, while maintaining a similar clock speed. But you ask yourself how? Well it’s a bit of all the improvements in Turing. It’s somewhat from the extra cache and bandwidth, but it’s mostly from concurrent execution enabling the FP16 instructions to be done at the same time as the FP32 ones. In other words, they are no longer holding each other back as much as they were previously due to the separate pipelines and this leads to almost 33% better performance at similar clock speeds.
Another big feature of Turing is “Variable Rate Shading” (VRS). VRS allows shading (colouring essentially) to be different across the screen in different areas. If areas are spent with less time shading, then you save computational power for where places where that computational power is needed for shading. VRS allows for different rates of shading across the screen. Thus, areas which might require more shading due to more movement or action, such as the center of the screen, can be specified in a grid like fashion by a developer. With areas such as the edges of the screen which require less shading power and detail to be specified as well for less computation. The different colours in the grid designate different shading rates. VRS is shown below.
NVIDIA has also added “Content Adaptive Shading” (CAS), which works in a similar matter by reducing shading in areas that have a reduced amount of detail. So for instance, areas of sky which are all just blue with no clouds, or a flat coloured wall without much detail, can have lower rates of shading than areas of road which have lots of texture or detail. It does this by analysing the previous frame and then checking for areas of low detail. This analysis in the previous frame drives the shading rate of areas in the next frame, if implemented by a developer. This is also implemented in Wolfenstein II, just like concurrent execution is. The different colours in the grid (bottom left) designate different shading rates. CAS is shown below.
As we can see, different areas of the screen have different shading rates, purely off colour and amount of detail being detected in the previous frame. NVIDIA claims this doesn’t show any visual difference in image quality, however I think there’s a small difference, but most people cannot perceive it.
Back to the RTX 2060 versus the GTX 1070. I can’t say for sure what kind of clock speed either card is running at in this specific benchmark from ANANDTech.com. But the clock speeds are super close, the RTX 2060 has a boost clock of 1,680 MHz and the GTX 1070 has a boost clock of 1,683 MHz. They are more than likely boosting higher than this though, but I would say that the RTX 2060 isn’t boosting 33% higher than the GTX 1070. So this is not what is leading to this performance increase. If it did, that would mean the RTX 2060 would be running at something like 2,234 MHz on air, which has basically never been recorded on an RTX 2060 ever, meaning it’s basically impossible. If you asked me what kinds of clocks these are both running at, I’d say they are both more than likely boosting to around 1,830 MHz each, with maybe the RTX 2060 being a little higher at 1,870 MHz, a negligible difference.
In fact, when we look at it, from a relative standpoint thanks to TechPowerUp.com, the RTX 2060 is delivering 25% more performance than the GTX 1070 across an average of multiple titles, all thanks to the improvements of Turing. While not the 32% faster that we saw in Wolfenstein II, it goes to show that the improvements certainly are something from NVIDIA, versus their previous architecture of Pascal.
Muddying the waters
If you remember all the way back to the top of this article/post, I mentioned the GTX 16 series graphics cards. These GTX 16 series cards, such as the GTX 1660 Ti and the soon to be released GTX 1660 also use the Turing architecture. There’s a catch however, they totally eliminated the RT core from the GTX 16 series GPUs, meaning no real-time ray-tracing capabilities. Instead, NVIDIA changed Turing for the 16 series to no longer have the RT Core and Tensor Cores, but instead to have FP16 cores instead.
I never talked about FP16 cores other than them being different to FP32 cores, but essentially it’s another instruction set used in a couple of games such as Far Cry 5, Wolfenstein II and Far Cry New Dawn. The RTX 20 series cards still have FP16 capability, it does it through the tensor cores instead. So if you picked up an RTX 20 series card, don’t stress, you didn’t miss out. But other than that, the same things remain in the GTX 16 series cards, such as concurrent execution, as well as the cache and memory improvements of the 20 series. There might be a few minor details that have changed, but I can’t find anything big to really write home about as a difference between the RTX 20 series and GTX 16 series, other than that the RT Core missing.
How does Turing stack up?
If you’re in the market for a new GPU, you need not worry. I have you covered with this easy buying guide and comparison.
NVIDIA Turing: еще один шаг к кинореализму в играх
Последние несколько лет NVIDIA не принимает непосредственного участия в игровой выставке Gamescom в Кёльне, а вместо этого проводит собственное мероприятие за день до ее открытия. В этом году компания не изменила своим традициям, однако на этот раз ее Geforce Gaming Celebration оказался на порядок масштабнее, чем обычно.
Обновлено: Детям из Мариуполя нужно 120 ноутбуков для обучения — подари старое «железо», пусть оно работает на будущее Украины


Повод для этого, впрочем, был самый что ни на есть подходящий: официальное представление игровых видеокарт семейства GeForce RTX на новой архитектуре Turing – а ее появление, по словам представителей компании, является событием такого же масштаба, как и представление вычислительной архитектуры CUDA 10 лет назад. Видимо, именно из этих соображений производитель «перескочил» сразу через десяток «поколений» в нумерации семейства – первые слухи об анонсе оперировали названием GeForce 11 (что было бы логично для преемника очень успешной линейки GeForce 10), однако в реальности новое поколение получило обозначение GeForce 20.
Основная презентация, проведенная президентом компании Хуангом Дженсеном, состоялась вечером 20 августа – все желающие могли посмотреть прямую онлайновую трансляцию, также у нас сразу последовали новости с основными техническими характеристиками новых видеокарт и локальными ценами в Украине (последняя обсуждалась особенно жарко), поэтому подробно на этой части мероприятия NVIDIA мы уже останавливаться не будем, отметим лишь, что Хуанг Дженсен настолько эмоционально вел презентацию, что сумел заразить своим энтузиазмом весь немаленький зрительный зал (где, помимо нескольких сотен журналистов, присутствовали также и тысячи простых посетителей презентации).


Но, помимо собственно GeForce Gaming Celebration, презентация нового поколения видеокарт включала в себя и дополнительный Editor’s Day – мероприятие, как ясно из названия, уже исключительно для прессы, где в течение целого дня представители компании в подробностях рассказывали о новой архитектуре Turing и о том, какую революцию она призвана совершить в игровой индустрии. Вот про этот «день редакторов» мы сегодня и расскажем.
Что такое рейтрейсинг?
Но прежде чем переходить к рассмотрению новой архитектуры – немного теории. Итак, до сих пор при создании кадра в 3D-игре, т.е. для преобразования трехмерной сцены в плоскую картинку на экране, используется так называемая растеризация. Здесь вершины треугольников, из которых состоят полигональные объекты, проецируются на плоскую поверхность «экрана» (ее в данном случае можно представить в виде сетки пикселей, где каждому пикселю присваивается характеристика соответствующего полигона). Процесс идет от самых дальних объектов к самым ближним, так что по умолчанию эта сетка пикселей будет по нескольку раз «перезаписываться», когда окажется, что перед уже «пройденным» объектом, например, домом, находится другой объект, например, дерево. До сих пор все развитие игровой графики строилось на оптимизации этого процесса – например, выбрасывании ненужной для данной сцены информации (предметы за пределами кадра или перекрываемые другими объектами). У растеризации есть свои очень сильные достоинства – так, она выполняется быстро, а за счет использования дополнительных «улучшателей» в виде различных шейдеров позволяет получить очень достойный результат… собственно, именно его мы и видим в современных трехмерных играх, поскольку все они на данный момент используют именно этот способ переноса трехмерной сцены на плоскость экрана. Но есть у растеризации и не менее сильные недостатки: например, предметы, не попавшие в кадр, порой все равно должны влиять на то, что находится внутри него (отбрасывать тень на объекты в сцене, отражаться в зеркальных поверхностях, менять цвет рассеянного освещения и т.д.), однако не могут это сделать, поскольку были исключены из расчетов в силу своей «невидимости». Частично это можно исправить с помощью «костылей» вроде карт теней, которые позволяют в ручном режиме «разложить» тени там, где этого хочется разработчику, но это будут именно костыли, неспособные создать полноценную реалистичную и главное – интерактивную картинку. И в любом случае, человеческий глаз – это не «сетка пикселей», проверяющая, что находится перед каждой из ее ячеек. Глаз работает по совершенно другому принципу: лучи света (от солнца, ламп, взрывов и т.д.) отражаются от поверхностей, часть из них попадает в глаз – и вот они-то и создают у нас в голове цельную картину того, что находится перед нами.
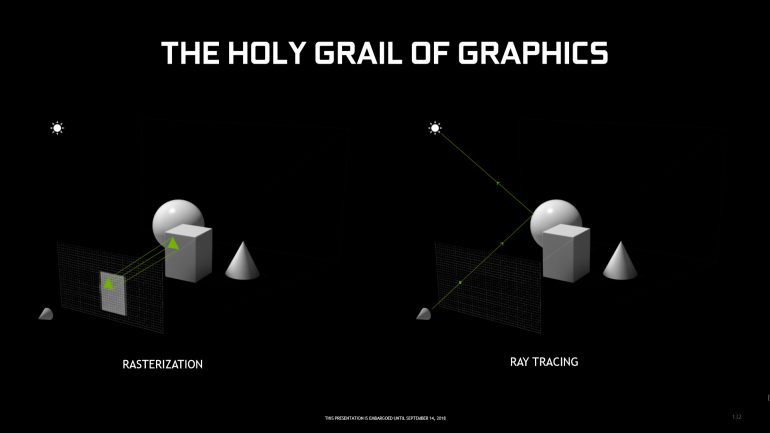
И тут мы наконец вплотную подходим к альтернативе растеризации: трассировке лучей, или «рейтрейсингу» (raytracing). Принцип действия звучит просто: изо всех источников света испускаются лучи света, которые «натыкаются» на предметы в сцене и, в зависимости от типа материала, оказавшегося на их пути, могут отразиться под тем или иным углом, поглотиться или пройти сквозь предмет, преломившись по пути. И так они будут «путешествовать» по сцене до тех пор, пока не попадут в «глаз» наблюдателя, т.е., в нашем случае, игрока. Созданное таким образом изображение оказывается гораздо более точным по сравнению с полученным с помощью растеризации — достаточно сказать, что именно так создаются компьютерные спецэффекты в современном кино. Однако здесь возникает одна маленькая проблема – ресурсоемкость (впрочем, «маленькая» она только для кинематографа, где время, потраченное на создание такого изображения, не является критичным параметром). Чтобы использовать эту технологию в играх, она должна работать в режиме реального времени, т.е. успевать прорисовывать десятки кадров в секунду, а сам по себе raytracing – невероятно сложный вычислительный процесс (достаточно сказать, что для каждого кадра нужно просчитать поведение миллионов лучей, причем буквально за считанные миллисекунды), и даже самые мощные современные игровые системы и близко не подошли к такой производительности.

На этом вопрос практического использования рейтрейсинга в играх можно было бы считать закрытым по крайней мере на ближайшие полдесятка лет, до появления принципиально более мощных видеокарт, однако в начале этого года появились весьма интересные анонсы, из которых выходило, что рейтрейсинг в реальном времени на самом деле ближе, чем кажется.
Так, весной на конференции разработчиков игр GDC Microsoft представила расширение DirectX 12 — DirectX Raytracing (DXR). Новое API предназначено для аппаратного ускорения трассировки лучей в DirectX-играх и используется в связке с традиционной растеризацией – оказалось, что ее вполне реально применять для базового расчета сцены и добавлять рейтрейсинг для вычисления достоверного освещения, теней, отражений и других эффектов, невозможных при использовании растеризации. Такой «гибридный» рендеринг позволяет создавать гораздо более реалистичные и привычные для человеческого глаза сцены, и при этом он оказывается менее требовательным к ресурсам, чем «полный» рейтрейсинг всей сцены – настолько, что его уже почти можно было использовать на современном «железе» (пусть и с явно недостаточной для комфортной игры производительностью даже на топовых конфигурациях полугодичной давности). Тогда же стало известно, что NVIDIA плотно сотрудничает с Microsoft над реализацией DXR. Впрочем, для менее широкой аудитории уже давно не секрет, что NVIDIA ведет разработки в этом направлении – еще в 2008 году на аналогичном Editor’s Day сотрудники компании показывали первую версию своего гибридного рейтрейсинга и говорили, что именно за ним будущее трехмерных игр.

Однако практическая выгода от появления DXR оставалась довольно туманной до конца лета, а точнее, до громкого анонса новой архитектуры NVIDIA Turing с аппаратной поддержкой гибридного рейтрейсинга и новой, 20-й серии игровых видеокарт GeForce RTX.

Что нового в новой архитектуре?
Итак, NVIDIA Turing. Главным нововведением этой платформы являются два новых типа ядер: RT-ядра для расчета трассировки лучей в реальном времени и тензорные ядра для задач, связанных с искусственным интеллектом. Отметим, что тензорные ядра впервые появились еще в архитектуре Volta (использовавшейся в видеокартах NVIDIA Titan V и Quadro GV100), однако в Turing они были обновлены, получив более высокую производительность в задачах тренировки нейронных сетей, а также при расчетах с пониженной точностью. NVIDIA переработала архитектуру потоковых мультипроцессоров (streaming multiprocessors, или SM — грубо говоря, основных блоков, из которых и «собирается» собственно GPU), и теперь каждый SM состоит из 64 ядер CUDA, плюс к ним добавлены 8 тензорных ядер и одно RT-ядро. Всего в GPU TU102 (которое используется в видеокарте GeForce RTX 2080 Ti) входит 72 мультипроцессора.

Одним из серьезных новшеств мультипроцессора Turing стало добавление отдельных блоков для выполнения целочисленных операций – это дает заметный прирост производительности в играх, поскольку в современных проектах, по словам докладчика, на каждые 100 операций с плавающей точкой приходится порядка 36 целочисленных операций, и теперь они будут выполняться одновременно, а не последовательно, как на видеокартах предыдущего поколения.
Также NVIDIA представила новую архитектуру кэш-памяти. У Pascal было два отдельных блока памяти – L1 и общая память (и это создавало определенную «неразбериху» и неоптимальное их использование различными приложениями), в Turing же их объединили – новый вариант (представленный еще в Volta и наконец добравшийся до потребительских видеокарт) получил название «унифицированной архитектуры кэш-памяти» и позволяет более гибко использовать кэш первого уровня, повышает его пропускную способность и снижает задержки. Также в Turing удвоен объем L2-кэша – с 3 до 6 МБ. Все эти решения позволили заметно повысить скорость обработки шейдеров – если верить показанной во время презентации диаграмме, в реальных играх новая архитектура памяти позволяет получить минимум полуторакратный прирост производительности.
Еще один предмет гордости NVIDIA – GPU на базе Turing стали первыми чипами с поддержкой памяти GDDR6. Заявлена пропускная способность интерфейса на уровне 14 Гбит/с (на треть выше, чем у предыдущего поколения), а также снижение уровня перекрестных помех на 40%.
Как говорилось чуть выше, Turing «унаследовал» от Volta тензорные ядра для задач, связанных с искусственным интеллектом. По сути, тензорное ядро – это АЛУ, предназначенное для выполнения матричных операций, поскольку именно умножение матриц и лежит в основе всего глубокого обучения ИИ. Не будем вдаваться в совсем уж технические дебри, отметим лишь, что благодаря наличию специализированных ядер новые видеокарты показывают в несколько раз большую производительность в таких задачах по сравнению с архитектурой Pascal.

Забегая чуть вперед — тензорные ядра также используются для «шумоподавления» и очистки полученного при рейтрейсинге изображения, что позволяет уменьшить количество лучей, необходимых для построения сцены (и, соответственно, ускорить процесс).
Возвращаясь к рейтрейсингу – на сегодняшний день стандартным алгоритмом для оптимизации определения видимости треугольников в сцене является т.н. bounding volume hierarchy (BVH) – своеобразная древовидная структура, группирующая треугольники в блоки все большего объема. Благодаря такому подходу в процессе определения, попал ли луч в треугольник, не приходится перебирать все треугольники в сцене: нужно проверить сначала самые большие блоки, найти требуемый, проверить входящие в него блоки и т.д., до тех пор, пока луч не «доберется» до конкретного треугольника.

Но даже с такой оптимизацией процесса при использовании программной эмуляции мультипроцессор Pascal тратит многие тысячи итераций для каждого луча, что, естественно, перегружает работой GPU, не давая ему заниматься другими задачами по прорисовке сцены. Чтобы «разгрузить» его, в Turing и были добавлены выделенные RT-ядра, занимающиеся исключительно этими расчетами: мультипроцессор просто «запускает луч» и получает от RT-ядра уже готовый результат.
В итоге, по данным NVIDIA, при расчете рейтрейсинга видеокарта GeForce RTX 2080 Ti демонстрирует в 10 раз более высокую производительность по сравнению с GeForce GTX 1080 Ti (больше 10 «гига лучей в секунду»).
Кроме того, NVIDIA представила ряд новых технологий, которые будут доступны на новой архитектуре. Одна из них – это Mesh Shading, с помощью которой разработчики игр смогут перекладывать на GPU задачи по расчету уровней детализации объектов. Сейчас LOD считается на CPU, что в случае сложных сцен со множеством объектов просто «забивает» процессор работой – так что в современных играх количество предметов в кадре обычно довольно ограниченно. С помощью же Mesh Shading эти вычисления будут производиться видеокартой, которая гораздо лучше приспособлена для таких задач – так, в ходе презентации была продемонстрирована сцена с космическим кораблем в поясе астероидов, в которой на экране отображалось порядка 300 тыс. объектов. По словам докладчика, это в 10 раз больше, чем было бы возможно при расчете LOD на центральном процессоре, при этом счетчик fps не опускался ниже 60 кадров/сек. Как образно выразился ведущий: «CPU лишь говорит видеокарте – так, в этой сцене будут вот такие объекты, сама с ними разбирайся, и все остальное делает уже GPU».
Вторая технология — Variable Rate Shading, позволяющая разработчикам оптимизировать применение шейдеров, снижая точность расчетов в малозначимых участках кадра (накладывая шейдер на один пиксель и дальше используя полученное значение для нескольких окружающих его пикселей). Это было продемонстрировано на сцене из автогонки, где точность расчета шейдеров для уносящегося назад асфальта в нижней части кадра может быть минимальной – все равно игрок не успеет оценить там все «красоты» дорожного покрытия.
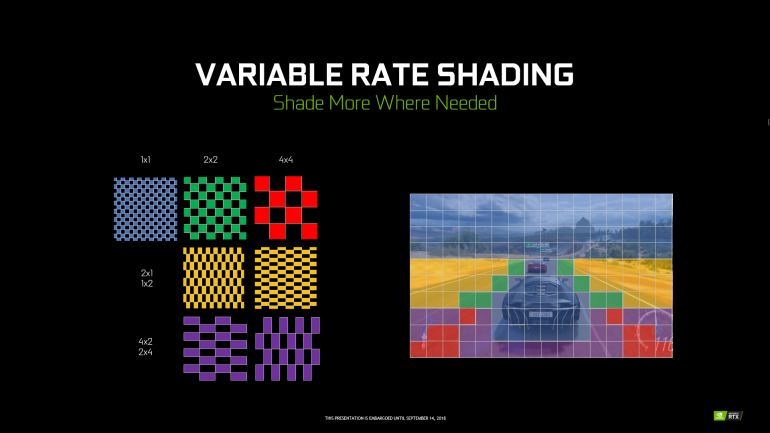
Кроме упрощения расчетов быстро движущихся участков изображения, Variable Rate Shading можно также использовать в зависимости от контента: например, статичные участки уровня, погруженные в полумрак и не содержащие никаких интересных для геймера деталей, можно вычислять с упрощениями, в то время как на находящиеся тут же циферблаты или экраны компьютеров накладывать шейдеры «по полной программе».
Зачем нужен рейтрейсинг в играх?
Впрочем, новая архитектура, новые ядра, технологии и т.д. – это, конечно, хорошо, но что это значит для обычного геймера, покупающего такую видеокарту? Что такого дает Turing, что станет недоступно в новых играх для игроков, использующих видео предыдущих поколений?
Итак, гибридный рендеринг в первую очередь позволяет получить правильное глобальное освещение, а также реалистичные тени и отражения в зеркальных поверхностях. Расчет глобального освещения (global illumination) с помощью рейтрейсинга дает возможность правильно осветить сцену с помощью имеющихся источников света, в том числе и находящихся за пределами кадра, а также учесть отраженный свет от залитых светом предметов. Во время презентации это демонстрировалось на примере Metro Exodus, где заброшенный деревенский домик освещался исключительно через один-единственный оконный проем. Без использования RTX освещен был лишь прямоугольник напротив окна, в который попадали только стол и пол вокруг него, все остальное помещение было полностью погружено в темноту. После включения RTX стол и фрагмент залитого солнечным светом пола выступили источниками отраженного света и «подсветили» окружающую обстановку, превратив непроглядную тьму комнаты в легкий полумрак. Конечно, аналогичного эффекта можно было бы достичь с помощью различных ухищрений вроде карт теней, однако результат получился бы статичным – смена дня и ночи, взрывы за окном, прошедший персонаж с фонариком и т.д. никак бы не повлияли на освещение интерьера этого домика, в то время как расчет глобального освещения с помощью RTX во всех подобных случаях автоматически выдает корректное изменение освещенности в комнате.
Рука об руку с глобальным освещением идут реалистичные тени. При растеризации динамические тени получаются резкими, с четкими краями, с видимыми артефактами в случае наложения теней от нескольких объектов и т.д. Рейтрейсинг же позволяет получить гораздо более реалистичные тени – более мягкие, с корректными «взаимопроникновениями» с тенями от других объектов, с правильными цветовыми оттенками в случае разноцветных источников освещения или отсветов от стоящих рядом цветных поверхностей, с естественными «стыками» теней и откидывающих их объектов (например, ног персонажей, отчего они перестают казаться либо «воткнутыми» в поверхность под ними, либо, наоборот, левитирующими в паре сантиметров над уровнем пола). Опять-таки, использование рейтрейсинга позволяет получить корректные тени в кадре от предметов, находящихся вне поля зрения.
И третий «кит», на котором стоит гибридный рендеринг технологии RTX – это отражения. «Честно» отразить окружающую обстановку в зеркальных поверхностях при растеризации практически невозможно: для тех же предметов, находящихся за пределами кадра, приходится использовать статичные кубические карты (cube mapping), которые, разумеется, не могут реагировать на изменяющуюся обстановку в игре. Пожалуй, именно реалистичные отражения и были любимой «фишкой» в презентациях игровых разработчиков, показывавших, чего они могут достичь при помощи RTX. «Переотражения» одной машины в другой на треке в автосиме Assetto Corsa Competizione, эффектные лужи машинного масла в боксах гигантских мехов в долгожданном продолжении Mechwarrior 5: Mercenaries, бесконечная галерея отражений в поставленных друг напротив друга зеркалах в сюрреалистическом Atomic Heart (при этом все виденное в них реально и полностью соответствует происходящему на уровне – например, в районе пятого-шестого отражения можно было разглядеть прогуливающихся в стороне ученых, и в этой зеркальной галерее они себя вели так же, как и в самой сцене). И, конечно, Battlefield V, в котором отражения позволили разработчику добиться настоящей кинематографичности происходящего: вспышки пламени отсвечиваются в глазах, струя огнемета отражается в лужах на брусчатке и окрашивает алым отсветом приклад винтовки у стоящего рядом солдата, в капоте автомобиля можно увидеть перевернутое небо с подбитым штурмовиком, падающим на площадь неподалеку, и т.д.
Однако Turing – это не только рейтрейсинг, но и искусственный интеллект. В теории его можно использовать для самых разных задач (повышение разрешения фото, построение трехмерных моделей на основе плоских изображений, колоризация черно-белых снимков и т.д.), на GeForce RTX с его помощью выполняется новый тип антиалиасинга — Deep Learning Super Sampling, или DLSS. Вкратце принцип его работы таков: NVIDIA в сотрудничестве с разработчиком игр создает идеальные игровые изображения из его проекта на порядок большего разрешения, чем будет использоваться в реальности, и обучает с их помощью нейронную сеть – «вот как данная игра должна выглядеть». После чего ее поддержка добавляется в драйверы, и при запуске этой игры тензорные ядра смогут использовать накопленные «знания» для повышения качества изображения в том разрешении, которое использует геймер.

В ходе презентации все желающие могли увидеть DLSS в действии – на нескольких стендах были установлены по две системы с запущенными на них демо Infiltrator от Epic Games, в одной из которых была установлена видеокарта GeForce GTX 1080 Ti, во второй – RTX 2080 Ti. Демо запускалось в 4K-разрешении, на первом стенде использовался «обычный» антиалиасинг – TAA (temporal anti-aliasing), на втором – DLSS. И если на первом компьютере производительность находилась на уровне
40 fps, то на втором она была вдвое выше – порядка 80 fps. Собственно, именно такой двухкратный прирост в играх с поддержкой DLSS и демонстрировала NVIDIA на одном из своих слайдов (на нем же видно, что в случае использования TAA GeForce RTX 2080 оказывается в среднем в полтора раза быстрее по сравнению с 1080).
Вместо послесловия
Но просто послушать о новинках – явно недостаточно; чтобы получить максимально полное впечатление о новых возможностях архитектуры Turing, в течение двух дней презентации NVIDIA предоставляла возможность лично «пощупать» как технологические демо, так и уже живые билды реальных игр с поддержкой рейтрейсинга.
Сразу стоит отметить, что в разных проектах эффект от использования рейтрейсинга ощущается по-разному: где-то сильнее, где-то слабее, где-то он сразу бросается в глаза, а где-то надо присматриваться и искать его проявления. Так, во время десятиминутного заезда в Assetto Corsa Competizione я, признаться, не ощутил особых отличий от «обычной» графики – реалистичные отражения в машинах не увидишь, когда едешь в одиночку по треку с видом из кабины, да и разглядеть правильное освещение у объектов на обочине сложно, когда проносишься мимо них на 150 км/ч…

Совсем другое дело было с Battlefield V и Metro Exodus. В этих играх хотелось «притормозить» и не спеша разглядывать отражения в окнах или лужах, игру света и тени в кронах деревьев, отсветы вспышек на стенах домов и т.д. Вообще, после знакомства с несколькими проектами сложилось впечатление, что чем медленнее протекает игровой процесс, тем лучше замечаешь все проявления новых технологий и тем сильнее они впечатляют. Так что уже ждем рейтрейсинг в неспешных «ужастиках», где реалистичное освещение вполне может стать составляющей частью геймплея.


Также на стендах присутствовали и собственно «виновницы торжества» — вся представленная линейка из GeForce RTX 2070, 2080 и 2080 Ti, которые пользовались повышенной популярностью у журналистов, выстраивавшихся в очередь для фотосессий.



Естественно, везде были установлены собственные варианты видеокарт, Founders Edition, однако в дальнем углу зала удалось найти и целую раскладку моделей от сторонних производителей – впрочем, платы у них у всех явно были референсные, так что отличались они, по сути, лишь системами охлаждения.



У одной из видеокарт не было тыловой защитной пластины, что позволило увидеть, как выглядит плата сзади.

На этом первое знакомство с новой архитектурой NVIDIA Turing и линейкой видеокарт GeForce RTX 20 в Кёльне подошло к концу – к сожалению, на мероприятии еще не были доступны коммерческие образцы видеокарт, только инженерные сэмплы, поэтому заранее получить видеокарту для тестирования не представилось возможным. В любом случае, мы надеемся подготовить для вас предметный обзор NVIDIA GeForce RTX 2080 в ближайшее время.