Хеш и кеш в чем раница?
хеш — это контрольная сумма файла. каждый файл имеет свою собственную контрольную сумму, по которой определяется его целостность. чаще всего я сталкивалась с понятием хеш в торрентах. когда добавляешь торрент в закачки, программа проверяет контрольную сумму файла — хеш, и определяет, сколько еще нужно докачать.
а кеш — это область на компьютере (жестком диске или в оперативной памяти), куда система записывает файлы, к которым чаще всего обращается пользователь. тем самым увеличивается быстродействие системы, потому что файл сразу запускается из кеша, а не ищется по всему пространству компьютера. как-то так
Хэш-функция в повседневной жизни
Известно, что хэш-функция создает уникальный цифровой отпечаток из исходной информации. Итоговое хэширования информации называют хэш-суммой или просто хэшем.
Как же это работает? Хэш-функция берет определенную информацию, например, часть текста или пароль от вашего аккаунта, это может быть даже отдельный файл и преобразует эту информацию в строку определенной длины. Эта строка всегда будет иметь одинаковую длину вне зависимости от того, какого размера была входная информация. Существует достаточно много различных хеш- алгоритмов. Например, слово bitcoin, пропущенное через хэш алгоритм sha-256 будет выглядеть вот так.
Хэш-функции очень сильно отличаются от обычного шифрования.
Зашифровав какую-либо информацию через алгоритм AES вы всегда с помощью парольной фразы сможете ее расшифровать. Хэш-функции работают только в одну сторону. Пропустив какую-либо информацию через хэш-функцию, например, свой пароль, вы не сможете получить исходное значение информации, зная значение хэша. Это одно из требований к хэш-функциям. Хэш-функция должна быть однонаправленная. Позже мы разберем пример, для чего это нужно.
Второе основное требование для хэш-функций — фиксированный размер получаемого хэша, вне зависимости от введенной информации. Сейчас перед вами таблица с несколькими исходными данными и хэшами.
Как видите исходная информация разной длины, однако хэш имеет одинаковую длину. В любом из случаев следующее требование к хэш-функции — уникальность получаемого кэша и практически полное отсутствие коллизии. Что это значит? Это значит, что два разных набора информации не могут выдать одинаковое значение хэша.
Коллизии существуют для большинства хеш-функций, но в надежных хеш- функциях частота возникновения коллизии близка к теоретическому минимуму. Например, хэш-функция md5 сейчас стала абсолютно не устойчива к коллизии.
Компьютеры стали настолько мощные, что найти коллизию за приемлемое время не составит труда. Прямо сейчас в интернете можно найти генератор к коллизии для хэш-функции md5. Чуть позже мы объясним, как коллизии могут быть использованы злоумышленникам. Хэш-функция также должна быть быстрой и быстро хэшировать исходную информацию. Но, это так же является и уязвимостью для «брутфорса», так чем быстрее работает хэш-функция, тем больше она уязвима для полного перебора. Для хорошей криптографической хэш-функции также важно наличие лавинного эффекта. Что это значит? Это значит, что при изменении даже одного байта в исходной информации, полученный хеш поменяется кардинально.
Как же будет выглядеть идеальная криптографическая хэш-функция? Идеалом криптографической хэш-функции можно считать ту функцию, которой присущи следующие пять свойств:
- Детерминированность — одинаковые входные данные всегда дают одинаковое значение хэша.
- Высокая скорость вычисления хэш-функций из любого сообщения.
- Однонаправленность — невозможно получить исходное сообщение, зная его хэш, за исключением попыток полного перебора.
- Наличие лавинного эффекта – минимальное изменение в исходном сообщении приводит к кардинальному изменению хэша.
- Невозможность найти одинаковое значение хэша для двух разных сообщений.
Давайте рассмотрим простой пример, как используются хэш-функции, когда вы
регистрируетесь, например, в Вконтакте или другой социальной сети. Ваш логин и пароль пропускается через определенную хэш-функцию и значения хэша записываются в базу данных. После регистрации, когда вы используете логин и пароль для входа они опять пропускаются через хэш-функцию, и значение хэша сравнивается с тем значением хэша, которое было записано в базу данных.
Изначально, после вашей регистрации, если значения совпадают, система вас авторизует. Если значение хэша не совпадают, то выскакивает уведомление о том, что логин или пароль неверный. Здесь мы возвращаемся к основному требованию хэш-функции — однонаправленности. Потенциальные злоумышленники, взломав базу данных какой-то социальной сети получат значений хэшей, но не чистые логины и пароли. Именно из-за того, что хэш-функция однонаправленная, из нее нельзя получить исходные данные, такие как пароль и логин пользователя.
Тем не менее злоумышленник, получив хэши все-таки сможет узнать пароль некоторых пользователей. Для этого используется атака по «радужным» таблицам.
Злоумышленники используют заранее вычисленные хэши для простых и часто используемых паролей и сравнивают хэши в таблице с полученными хэшами из базы данных социальной сети. Но тут появляется одна такая проблема: если некоторые пользователи устанавливают одинаковый пароль, итоговый хэш паролей получается тоже одинаковый. Вы можете сказать, что маловероятно что кто-то будет использовать одинаковый пароль. Однако, вот таблицы самых популярных паролей за 2020 год которые используют пользователи в социальных сетях и других сервисах.
Чтобы не было проблем с одинаковым хешем, когда несколько пользователей используют одинаковый пароль, используется «соль».
Что такое «соль»? «Соль»- это строка данных которая пропускается через хэш-функции вместе с паролем.
Использование «соли» при хэшировании гарантирует то, что даже при одинаковых паролях значение хэша будет разное. Допустим, если Алиса и Боб используют одинаковый пароль qwerty. Хэш этих паролей будут кардинально отличаться из-за того, что была использована «соль».
В интернете есть огромное количество уже прочитанных заранее хэшей. Для самых популярных паролей, например, на сайте «crackstation» можно проверить, как это работает. Для начала давайте пропустим самый часто используемый пароль qwerty через хэш-функцию sha-256.
Получаем значение хэша. Это значение хэша вставляем на сайт «crackstation» и получаем результат qwerty. Это не значит, что хэш-функцию обратили и вычислили исходное значение. Это значит, что у этого сайта есть база данных с уже прочитанными хэшами для каждого простого и часто используемого пароля.
Но использование «соли» не гарантирует полную защиту от атак злоумышленников. Злоумышленники все еще могут перебирать значение хэша через «брутфорс» или же полный перебор. Злоумышленникам понадобится больше времени, так как надо будет перебирать еще и все возможные значения «соли». Но теоретически это возможно, так как основное требование хэш-функции — скорость хэширования. А как мы упоминали ранее, скорость хеширования не всегда является преимуществом, особенно когда это касается хранения паролей, чтобы защититься от «брутфорса».
Так используются специально замедленные хэш-функции, на вычисление которых уходит больше времени, чем на вычисление стандартных функций. Это функции: decrypt, sckrypt или argon2. Их использование для хранения паролей полностью нейтрализует возможный «брутфорс» (Brute-force Attack). Такие функции используются для создания секретного ключа, который состоит из пароля пользователя, «соли», и дополнительного параметра cost. Параметр cost необходим для защиты от «радужных таблиц».
Параметр cost определяет количество циклов, через который будет пропущена исходная информация и это замедляет процесс хэширования. Таким образом, атака полного перебора становится невозможной, так как процесс хэширования сильно замедлен и за приемлемое время не получится перебрать достаточное количество паролей и всевозможных комбинаций «соли».
Со временем компьютеры станут мощнее и атаки полного перебора на этот алгоритм смогут быстрее достигать своей цели. Для защиты от этого необходимо просто увеличить параметр cost, который определяет количество циклов.
Чем больше циклов, тем больше времени потребуется для хеширования исходной информации.
Давайте рассмотрим метод защиты данных, который используют сервис dropbox. Изначально dropbox берёт пароль пользователя и пропускают его через определенную простую хэш-функцию без использования «соли». И затем полученный хэш пропускается через функцию BCrypt с использованием «соли» и параметр cost величиной в 10 циклов. Это защищает от брутфорса (Brute-force Attack). Так в конечном итоге вся эта информация шифруется алгоритмом шифрования aes. Злоумышленнику придется вскрывать все эти слои защиты, чтобы добраться до нужной ему информации.
Однако, стоит отметить что слабые пароли все равно уязвимы. Длинный и надежный
Пароль, пропущенный через простую хэш-функция md5 будет сложнее подобрать
чем пароль из 6 символов, но пропущенный через функцию BCrypt с параметром cost в 25 циклов.
Хранение и защита паролей не единственная сфера где применяются хэш-функции. Они также применяются для проверки целостности файлов, как было сказано ранее. При малейшем изменении исходного файла его хэш-сумма кардинально изменяется. Как это может быть использовано? Самый простой пример: проверка программного обеспечения, скаченного с сайта разработчика. Большинство разработчиков программного обеспечения рядом со ссылкой на скачивание программы размещают хэш-сумму каждого из файлов. После загрузки ПО на свой компьютер, пользователь может сравнить хэши и убедиться в том, что файлы подлинные и не подвергались изменению. Это может быть также использовано для передачи файлов между двумя людьми, когда необходимо убедиться в том, что в процессе передачи файлов он не был изменен. Но здесь при использовании надежных или устаревших хэш-функций имеет место быть коллизионная атака, когда два разных документа имеют одинаковый хеш.
Как происходит коллизионная атака. Приведём пример. Ева создает два разных документа «а» и «б» имеющих одинаковое значение хэш суммы. Предположим, что Ева хочет обмануть Боба, выдав свой документ за документ Алисы. Ева отсылает документ Алисе, которая доверяет содержанию данного документа, подписывает его хэш и отсылает подпись Еве. Ева прикрепляет подпись документа «а» к документу «б» затем отправляет подпись и документ Бобу утверждая, что Алиса подписала этот документ. Поскольку электронная подпись сверяет лишь значение хэша документа «б», Боб не узнает о подмене.
С надежным криптографическими хэш-функциями такое провернуть невозможно, но с устаревший md5 это реально осуществить.
Хэш-функции также используются и в блокчейне, каждая транзакция в блокчейне биткоина содержит информацию о получателе и отправителе. О сумме транзакций, времени её отправки и так далее. Вся эта информация хэшируется и образуется «транзакшин ID». «Транзакшин ID» это хэш-сумма, которая используется для ее идентификации и проверки того, что эта транзакция произошла. Хэши также используются и в блоках в блокчейне. Каждый блок блокчейна, биткоина, содержит свой хэш и хэш предыдущего блока, что образует связанную цепочку.
Пример применения хэширования паролей в Python с помощью модуля BCrypt.
Модуль bcrypt в PyPi предлагает удобную реализацию BCrypt, которую мы можем установить через pip:
После того, как установили BCrypt с помощью pip, вы можете импортировать его в свой проект:
Возьмем «Passwordnew» в качестве примера пароля, чтобы показать его в использование BCrypt:
Хешируем зашифрованный пароль с помощью BCrypt:
Проверим, будет ли текстовый пароль допустимым паролем для нового хэша, который создали в примере:
Таким образом, для наглядности был проиллюстрирован процесс хеширования пароля на примере BCrypt.
Надеюсь, что у вас сложилось представление о том, что такое хэш-функция, как работает алгоритм хэширования и как это можно использовать.
Структуры данных, которые необходимо знать каждому программисту
![]()
Пройти путь от нуля до профессионального инженера-программиста можно исключительно с помощью бесплатных ресурсов в интернете. Но разработчики, которые идут по этому пути, часто игнорируют концепцию структур данных. Они считают, что эти знания не принесут им пользы, поскольку они будут разрабатывать только простые приложения.
Однако уделять внимание структурам данных важно с самого начала обучения, так как они повышают эффективность приложений. Хотя это не означает, что нужно везде применять эти структуры — не менее важно понимать, когда они будут лишними.
Что такое структура данных?
Независимо от профессии, ежедневная работа связана с данными. Шеф-повар, инженер-программист или даже рыбак — все они работают с теми или иными формами данных.
Структуры данных — это контейнеры, которые хранят данные в определенном формате. Этот специфический формат придает структуре данных определенные качества, которые отличают ее от других структур и делают ее пригодной (или напротив, неподходящей) для тех или иных сценариев использования.
Рассмотрим некоторые из наиболее важных структур данных, которые помогут создавать эффективные решения.
Массивы
Массивы — одна из самых простых и часто применяемых структур данных. Такие структуры данных, как очереди и стеки, основаны на массивах и связанных списках (которые мы рассмотрим чуть позже).
Каждому элементу в массиве присваивается положительное целое число, которое обозначает положение элемента. Это число называется индексом. В большинстве языков программирования индексы начинаются с нуля. Эта концепция называется нумерацией на основе нуля.
Существует два типа массивов: одномерные и многомерные. Первые представляют собой простейшие линейные структуры, а вторые — вложенные и включают другие массивы.
Основные операции с массивами
- Get — получить элемент массива по заданному индексу.
- Insert — вставить элемент массива по заданному индексу.
- Length — получить количество элементов в заданном массиве.
- Delete — удалить элемент массива по заданному индексу. Может быть выполнено либо путем установки значения undefined , либо путем копирования элементов массива, за исключением удаляемого, в новый массив.
- Update — обновление значения элемента массива по заданному индексу.
- Traverse — проход цикла через массив для выполнения функций над элементами массива.
- Search — поиск определенного элемента в заданном массиве с помощью выбранного алгоритма.
Применение массивов
- Представляют собой строительные блоки более сложных структур данных, таких как стеки, очереди и т.д.
- Подходят для хранения несложных связанных данных благодаря простоте использования.
- Используются для различных алгоритмов сортировки, таких как сортировка вставок, сортировка пузырьком и т.д.
Связанный список (Linked List)
Связанный список — это набор элементов, называемых узлами, в линейной последовательной структуре. Узел — простой объект с двумя свойствами. Это переменные для хранения данных и адреса памяти следующего узла в списке. Поэтому узел знает только о том, какие данные он содержит и кто его сосед. Это позволяет создавать связанные списки, в которых каждый узел связан с другим.
Существует несколько типов связанных списков.
- Односвязный. Обход элементов может выполняться только в прямом направлении.
- Двусвязный. Обход элементов может выполняться как в прямом, так и в обратном направлениях. Узлы включают дополнительный указатель, известный как prev , указывающий на предыдущий узел.
- Круговые связанные. Это связанные списки, в которых предыдущий ( prev ) указатель “головы” указывает на “хвост”, а следующий указатель “хвоста” указывает на “голову”.
Основные операции со связанными списками
- Insertion — добавление узла в список. Это может быть сделано на основе требуемого местоположения, такого как голова, хвост или где-то посередине.
- Delete — удаление узла в начале списка или на основе заданного ключа.
- Display — отображение полного списка.
- Search — поиск узла в данном связанном списке.
- Update — обновление значения узла в заданном ключе.
Применение связанных списков
- В качестве строительных блоков сложных структур данных, таких как очереди, стеки и некоторые типы графиков.
- В слайд-шоу изображений, поскольку изображения идут строго друг за другом.
- В динамических структурах для выделения памяти.
- В операционных системах для легкого переключения вкладок.
Стек — линейная структура данных, которая создается на основе массивов или связанных списков. Стек следует принципу Last-In-First-Out (LIFO, “первым на вход — последним на выход”), т.е. последний элемент, вошедший в стек, будет первым, кто покинет его. Причина, по которой эта структура называется стеком, в том, что ее можно визуализировать как стопку книг на столе (по-английски stack).
Основные операции со стеком
- Push — вставка элемента в верхнюю часть стека.
- Pop — удаление элемента из верхней части стека с возвращением элемента.
- Peek — просмотр элемента в верхней части стека.
- isEmpty — проверка пустоты стека.
Применение стеков
- В истории навигации браузера.
- Для реализации рекурсии.
- При выделении памяти на основе стека.
Очередь
Как и стек, очередь — это еще один тип линейной структуры данных, основанной либо на массивах, либо на связанных списках. Очереди отличаются от стеков тем, что они основаны на принципе First-In-First-Out (FIFO, “первым на вход — первым на выход”), где элемент, который входит в очередь первым, и покинет ее первым.
Реальная аналогия структуры данных “очереди” — это очередь людей, ожидающих покупки билета в кино.
Основные операции с очередями
- Enqueue — вставка элемента в конец очереди.
- Dequeue — удаление элемента из передней части очереди.
- Top/Peek — возвращает элемент из передней части очереди без удаления.
- isEmpty — проверка содержимого очереди.
Применение очередей
- Обслуживание нескольких запросов на одном общем ресурсе.
- Управление потоками в многопоточных средах.
- Балансировка нагрузки.
Граф — это структура данных, представляющая собой взаимосвязь узлов, которые также называются вершинами. Пара (x,y) называется ребром. Это указывает на то, что вершина x соединена с вершиной y . Ребро может указывать на вес/стоимость, то есть стоимость прохождения по пути между двумя вершинами.
Ключевые термины
- Размер — количество ребер в графике.
- Порядок — количество вершин в графе.
- Смежность — случай, когда два узла соединены одним и тем же ребром.
- Петля — вершина, соединенная ребром сама с собой.
- Изолированная вершина — вершина, которая не связана с другими вершинами.
Графы делятся на два типа. Они различаются главным образом по направлениям пути между двумя вершинами.
- Ориентированные графы: все ребра имеют направления, указывающие начальную и конечную точки (вершины).
- Неориентированные графы: ребра не имеют направлений, которые позволяют обходам происходить с любого направления.
Распространенные алгоритмы обхода графов
- Поиск в ширину (BFS) — метод поиска кратчайшего пути в графе, основанный на вершинах.
- Поиск в глубину (DFS) — метод, основанный на ребрах.
Основные операции с графами
- Add vertex : добавить вершину в граф.
- Add edge : добавить ребро между двумя вершинами.
- Display : отобразить вершину.
- Total cost of traversal : найти общую стоимость пути обхода.
Применение графов
- Для представления потоковых вычислений.
- При распределении ресурсов операционной системой.
- Реализация алгоритмов поиска друзей в Facebook.
- Расчет кратчайшего пути между двумя локациями (Google Maps).
Дерево
Дерево — это иерархическая структура данных, состоящая из вершин (узлов) и ребер, которые их соединяют. Деревья часто используются в системах искусственного интеллекта и сложных алгоритмах, поскольку обеспечивают эффективный подход к решению проблем. Дерево — это особый тип графа, который не содержит циклов. Некоторые утверждают, что деревья полностью отличаются от графов, но эти аргументы субъективны.
Существует несколько типов деревьев.
- N-арное дерево.
- Сбалансированное дерево.
- Бинарное дерево.
- Бинарное дерево поиска (BST).
- Дерево AVL.
- Красно-черное дерево.
- 2-3-дерево.
BST — самые распространенные типы деревьев.
Основные операции с BST
- Insert — вставка элемента в дерево.
- Search — поиск элемента в дереве.
- PreorderTraversal — обход дерева прямым способом.
- InorderTraversal — обход дерева центрированным способом.
- PostorderTraversal — обход дерева обратным способом.
Применение деревьев
- Представление организации.
- Представление компьютерной файловой системы.
- Представление химической формулы.
- В деревьях принятия решений.
- Внутри JVM (Java Virtual Machine) для хранения объектов Java.
Хэш-таблица
Хэш-таблица хранит данные в парах ключ-значение. Это означает, что каждый ключ в хэш-таблице имеет некое значение, связанное с ним. Такая простая компоновка обеспечивает эффективность хэш-таблиц, независимо от их размера, при работе с данными.
Хэш-таблицы похожи на обычное хранилище данных с парой ключ-значение, однако их отличает способ генерации ключей. Они создаются с помощью специального процесса, называемого хэшированием.
Хеширование (хэш-функция)
Хэширование — это процесс, который с помощью хэш-функции преобразует ключ для получения хэшированного ключа. Эта хэш-функция определяет индекс таблицы или структуры, в которых должно храниться значение.
- h — хэш-функция.
- k — ключ, из которого должно быть определено хэш-значение.
- m — размер хэш-таблицы.
Например, рассмотрим использование хэш-функции k%17 . Если исходный ключ равен 20 , то хэшированный будет 20%17=3 . Значение будет храниться в хэш-таблице под индексом 3 .
Зачем нужен хэш?
Некоторые задаются вопросом, зачем проходить через дополнительный процесс хэширования, когда можно просто сопоставить значения непосредственно с ключом. Хотя прямое сопоставление несложно, оно может оказаться неэффективным при работе с большим набором данных. С помощью хеширования можно достичь почти постоянного времени O(1).
Коллизии
Поскольку для преобразования ключей используется общая хэш-функция, существует вероятность коллизий. Рассмотрим приведенный ниже пример с учетом хэш-функции k%17 .
- Когда k = 18, h(18) = 18%17 = 1.
- При k = 20, h(20) = 20%17 = 3.
- При k = 35, h(35) = 35%17 = 1.
Когда ключи равняются 18 и 35, происходит коллизия, поскольку они направляются к индексу 1.
Коллизии можно разрешить с помощью таких стратегий, как раздельная цепочка и открытая адресация.
Основные операции с хэш-таблицами
- Search — поиск элемента в хэш-таблице.
- Insert — вставка элемента в хэш-таблицу.
- Delete — удаление элемента из хэш-таблицы.
Применение хэш -таблиц
- В индексации баз данных.
- При проверке орфографии.
- При реализации заданной структуры данных.
- В кэше.
Заключение
Разработчикам важно знать хотя бы основы этих структур, поскольку при правильной реализации они помогут повысить эффективность ваших приложений.
Хеширование
Хеширование — это преобразование информации с помощью особых математических формул. В результате возникает хеш — отображение данных в виде короткой строки, в идеале — уникальной для каждого набора информации. Размер строки может быть одинаковым для информации разного объема.

«IT-специалист с нуля» наш лучший курс для старта в IT
Что такое хеш
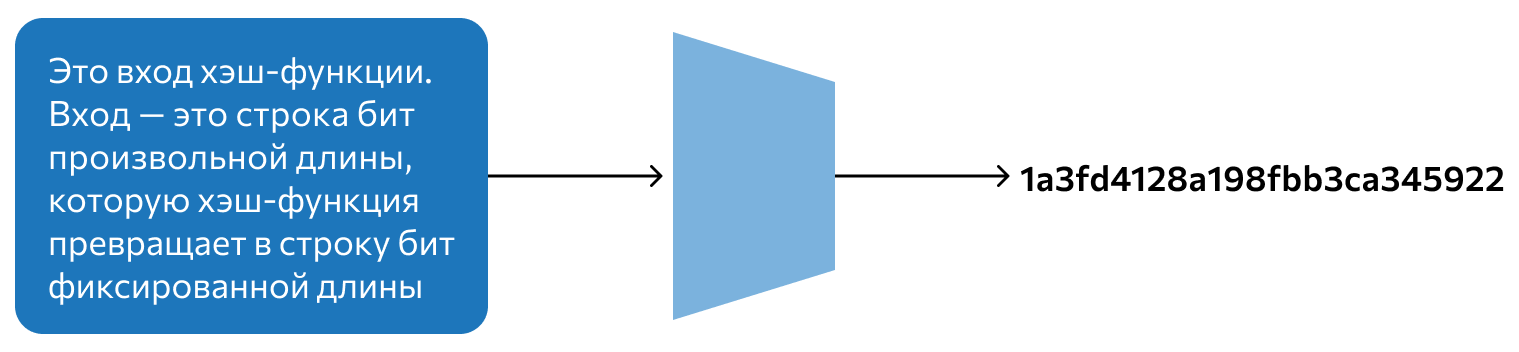 Как устроено хеширование
Как устроено хеширование
Хеш — это не закодированная исходная информация. Это скорее уникальная метка, которая генерируется для каждого набора данных индивидуально. Если захешировать большую книгу и одно слово, получатся хеши одинаковой длины. А если изменить в слове одну букву и снова захешировать полученную строку, новый хеш будет совершенно другим, там не окажется участков, которые повторяли бы предыдущий.
Хеш-функция — это математический алгоритм, по которому хешируется информация. Его название тоже иногда сокращают как «хеш». Хеш-функций существует очень много, они различаются методами вычислений, назначением, надежностью и другими параметрами.
Попробуйте 9 профессий за 2 месяца и выберите подходящую вам

Кто работает с хешированием
- IT-специалисты, разработки которых хранят чувствительную конфиденциальную информацию. Например, в веб-разработке хеши обычно нужны для проверки паролей. Вместо них на сервере хранятся хеши, а когда пользователь вводит пароль, тот автоматически хешируется, и хеш сравнивается с сохраненным на сервере.
- Разработчики, имеющие дело со сложными структурами данных, такими как ассоциативные массивы и хеш-таблицы.
- Люди, которые имеют дело с криптовалютой. В этой сфере активно используется хеширование как удобный способ проверки подлинности данных. На алгоритмах хеширования во многом построен блокчейн.
- Этичные хакеры и специалисты по информационной безопасности для обеспечения конфиденциальности данных или, наоборот, для проверки той или иной информации. Например, конкретный вирус можно распознать по характерному хешу.
Для чего нужно хеширование
Основное назначение хеширования — проверка информации. Эта задача важна в огромном количестве случаев: от проверки паролей на сайте до сложных вычислений в блокчейне. Так как хеш — это уникальный код определенного набора данных, по нему можно понять, соответствует ли информация ожидаемой. Поэтому программа может хранить хеши вместо образца данных для сравнения. Это может быть нужно для защиты чувствительных сведений или экономии места.
Вот несколько примеров:
- вместо паролей на сервере хранятся хеши паролей;
- антивирус хранит в базе хеши вирусов, а не образцы самих программ;
- электронная подпись использует хеш для верификации;
- информация о транзакциях криптовалюты хранится в виде кешей;
- коммиты в Git идентифицируются по хешу (подробнее про Git и коммиты можно прочесть в нашей статье).
Среди других, менее распространенных примеров использования — поиск дубликатов в больших массивах информации, генерация ID и построение особых структур данных. Это, например, хеш-таблицы — в них идентификатором элемента является его хеш, и он же определяет расположение элемента в таблице.
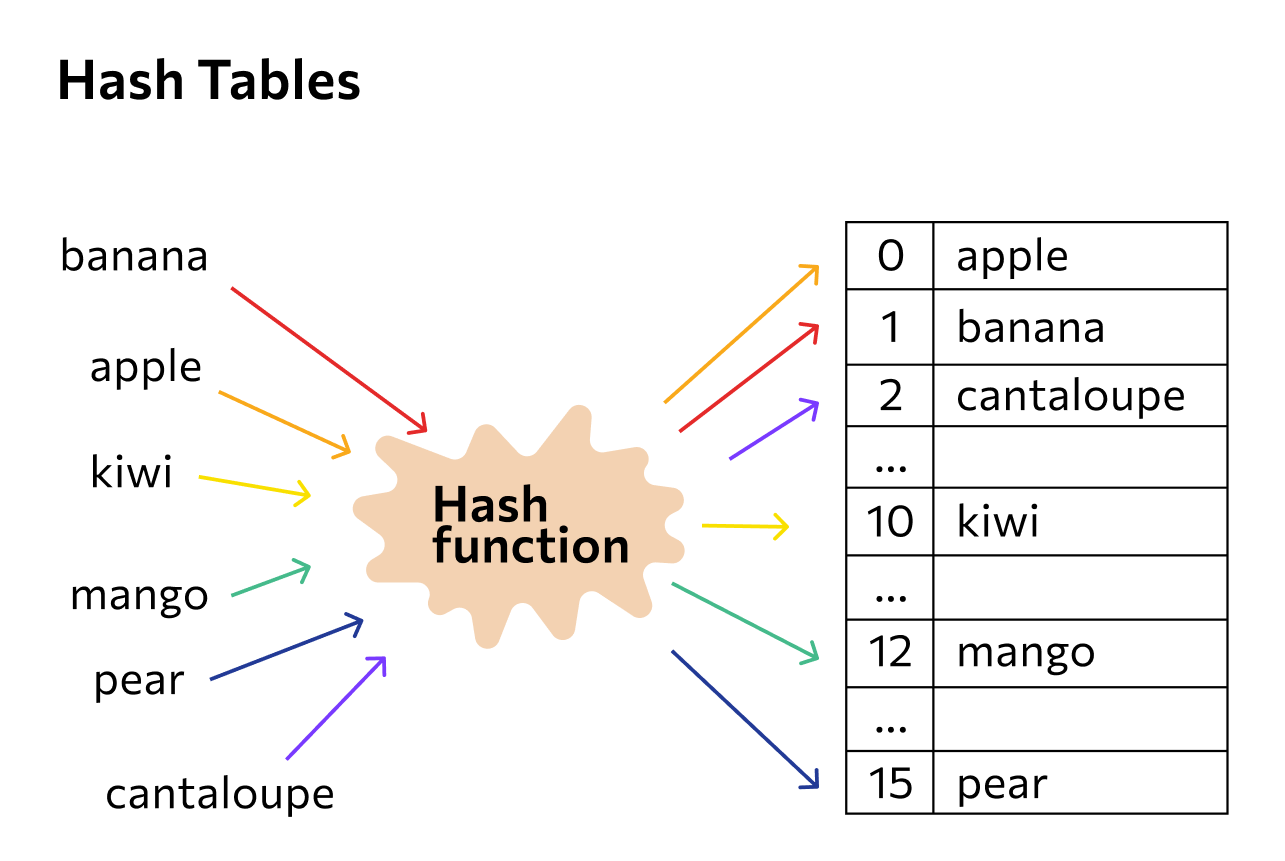
Как работает хеш-функция
Возможных преобразований для получения хеша бесконечное количество. Это могут быть формулы на основе умножения, деления и других операций, алгоритмы разного уровня сложности. Но если хеш применяется для защиты данных, его функция должна быть криптографической — у таких хеш-функций есть определенные свойства. Именно криптографические хеш-функции используются, например, при хранении паролей.
Если говорить о криптографической хеш-функции, то она чаще всего работает в несколько шагов. Данные разбиваются на части и проходят через сжимающую функцию, которая преобразовывает информацию в меньшее количество бит. Функция должна быть криптостойкой — такой, результат которой практически невозможно вскрыть.
А вот хеш-функции для более простых случаев, например построения таблиц, не обязаны быть криптографическими. Там преобразования могут быть проще.

Курс для новичков «IT-специалист
с нуля» – разберемся, какая профессия вам подходит, и поможем вам ее освоить
Свойства криптографических хеш-функций
Необратимость. Из хеша нельзя получить исходные данные даже теоретически. Слишком много информации отбрасывается в процессе; это не зашифровка информации.
Детерминированность. Если подать хеш-функции одинаковые данные, то и хеш у них будет одинаковым. Именно это свойство позволяет использовать хеши для проверки подлинности информации.
Уникальность. Идеальная хеш-функция выдает стопроцентно уникальный результат для каждого возможного набора данных. В реальности такое невозможно, и иногда случаются коллизии — одинаковые хеши для разных сведений. Но существующие хеш-функции достаточно сложны, поэтому вероятность коллизии сводится к минимуму.
Разнообразие. Даже если два набора информации различаются одним-двумя символами, их хеши будут кардинально разными. У них не будет общих блоков, по ним невозможно будет понять, что исходные данные схожи.
Высокая скорость генерации. Это в целом свойство любых хешей: в отличие от зашифрованных версий файлов, они генерируются быстро, даже если входной массив данных большой.
Взламывайте ПО безнаказанно и за оплату

Безопасность криптографической хеш-функции
Цель использования хешей — обеспечить безопасность пользователей. Идентификация или проверка подлинности данных нужны, чтобы никто не мог воспользоваться чувствительной информацией в своих целях. Поэтому специалисты пользуются именно криптографическими хеш-функциями. Они должны быть безопасными — так, чтобы никто не мог взломать их.
Идеальная криптографическая хеш-функция полностью отвечает перечисленным ниже требованиям. Реальные не могут ответить им на 100%, поэтому задача их создателей — максимально приблизиться к нужным свойствам.
Стойкость к коллизиям. Выше мы писали, что коллизия — явление, когда у двух разных наборов данных получается одинаковый хеш. Это небезопасно, потому что так злоумышленник сможет подменить верную информацию неверной. Поэтому коллизий стремятся максимально избегать.
Современные криптографические хеш-функции не полностью устойчивы к коллизиям. Но так как они очень сложные, для поиска коллизии нужно огромное количество вычислений и много времени — годы или даже столетия. Задача такого поиска становится практически невыполнимой.
Стойкость к восстановлению данных. Частично это означает все ту же необратимость, о которой мы писали выше. Но восстановить данные в теории можно не только с помощью обратной функции — еще есть метод подбора. Стойкость к восстановлению данных подразумевает, что, даже если злоумышленник будет очень долго подбирать возможные комбинации, он никогда не сможет получить исходный массив информации.
Это требование выполняется для современных функций. Информации в мире настолько много, что полный перебор всех возможных комбинаций занял бы бесконечно большое количество времени.
Устойчивость к поиску первого и второго прообраза. Первый прообраз — как раз возможность найти обратную функцию. Такой возможности нет, ведь криптографическая хеш-функция необратима. Этот пункт пересекается с требованием стойкости к восстановлению данных.
Второй прообраз — почти то же самое, что нахождение коллизии. Разница только в том, что в случае со вторым прообразом ищущий знает и хеш, и исходные данные, а при поиске коллизии — только хеш. Хеш-функция, неустойчивая к поиску второго прообраза, уязвима: если злоумышленник будет знать исходные данные, он сможет подменить информацию.
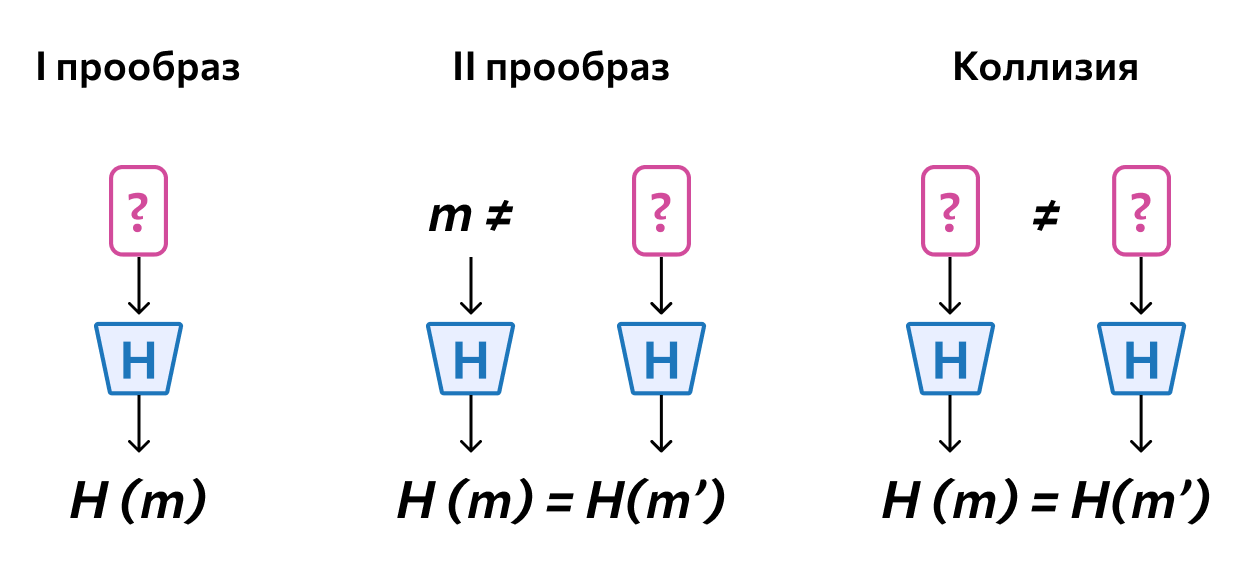 Прообразы и коллизия
Прообразы и коллизия
Криптографические хеш-функции устойчивы к поиску второго прообраза потому же, почему они считаются стойкими к коллизиям. Вычисления для нахождения таких данных слишком сложные и длительные, чтобы задача была реальной.
Наш лучший курс для старта в IT. За 2 месяца вы пробуете себя в девяти разных профессиях: мобильной и веб-разработке, тестировании, аналитике и даже Data Science — выберите подходящую и сразу освойте ее.